

Hi, I’m vs-123. I am a passionate programmer. I have a deep-seated interest in the inner workings of computers. My interests primarily revolve around low-level development. I enjoy bridging the gap between hardware and software.
C is my primary language of choice with a specific fondness for C99. I appreciate its efficiency and the granular control it offers over machine state, and I find its philosophy aligns perfectly with my interest in building lean & transparent systems.
-
C — C is my primary tool of choice for exploring the machine state. I highly value and enjoy the transparency, lean nature and the fine control it offers me over memory and hardware
-
C++ — C++ has been my bridge from high-level abstractions to systems programming. I still use it when the project requires complex architectural patterns or modern abstractions
-
Rust — Rust shaped my understanding of memory safety and has equipped me with key concepts such as memory ownership, borrowing, pointer aliasing, unsafe optimisations, etc.
-
WASM — I treat the web as just another compilation target. Sometimes I write projects in C/C++/Rust which I wish to be able to use on my browser, in such cases I compile to WASM
-
Regex — Beyond just using it, I’ve implemented a PCRE-compatible engine called regen from scratch in C99, in order to understand how it works deep under the hood. This has given me deep insights on not just regex, but also non-finite automata and backtracking
-
Python — I use Python as a scripting language, as a glue language. I use it mostly for writing quick scripts that are slightly more complex for bash, quick prototypes of algorithms, visualising data and making statistical observations and verification, like that of ystar
-
Lua — I enjoy Lua’s simplicity for a scripting language, and its embeddable nature. I use it primarily for my Neovim configuration.
-
Haskell — Haskell is my playground and laboratory for parser algorithms. I use Haskell for writing quick parser algorithms, as well as testing them. It’s functional nature and expressive type system makes it a perfect environment for me to test formal grammars
-
TypeScript — TypeScript was my first encounter with a formal type system. Initially I disliked its statically-typed nature, but after a while of using it, I had eventually learnt to appreciate type systems in general. The fact that I could catch potential errors before runtime was a fascinating idea to me, coming from JavaScript where somehow
0 == "0"and"0" == []aretruebut0 == []isfalseand('b' + 'a' + + 'a' + 'a').toLowerCase()becomes"banana" -
Linux & BSD — I enjoy exploring the philosophies of various platforms including *nix ecosystem, which also includes Linux and BSD. Although Void Linux is my daily driver, I admire the BSD family committing to the true UNIX philosophy. I especially admire the idea of "do one thing and do it well", which is pretty evident in the BSD userland and architecture
-
Vim — Vim is the first text editor I tried after months of VSCode. I found the idea of using my entire keyboard to manipulate text quite interesting. Vim has been my entry point into keyboard-oriented text editors
-
Emacs — I enjoy the highly customisable nature of Emacs. What stands out for me the most is the idea of it being a "self-documenting editor". I really appreciate its built-in help features, especially
C-hchords -
Neovim — I enjoy the idea that I can use Lua to customise Vim over using Vimscript, although I tend to use a bit of both. I enjoy using it for programming most of my projects. For certain, quick edits however I use
ed -
CMake — CMake is my primary meta-buildsystem of choice when I write C and C++ projects. I enjoy its ability to general build files for various buildsystems. This allows my projects, which I build with GNU Make, to be built on someone’s Windows machine with Visual Studio
-
LaTeX & Markdown — These are my tools of choice when it comes to technical documentation and making general notes. However, I tend to prefer AsciiDoc over Markdown due to its ability to modularise and reuse content. This README too, is written in AsciiDoc and not Markdown
-
regen — A PCRE-compatible, regular-expressions engine written in C99. Supports various features including capture groups, backreferences, zero-width lookaround assertions, character classes, and more. No external libraries were used
Highlights:
-
Transactional Backtracking — Uses a local "undo log" for each recursion depth to ensure integrity of captures and prevent "dirty" states.
-
Full Lookarounds — Supports Positive/Negative Lookahead
(?=…)and Lookbehind(?<=…). -
Backreferences — Supports
\1through\9with implemented safety checks to avoid infinite recursion in nested patterns. -
Zero Third Party Dependencies — Pure Standard C99 logic, no external libraries used.
Syntax Support (click to expand)
SYNTAX TERMINOLOGY DESCRIPTION ^START OF STRING
Matches only at the absolute beginning
$END OF STRING
Matches only at the very end
.WILDCARDS
Matches any single character
*,+,?QUANTIFIERS
Greedy: zero/one or more occurrences
*?,+?NON-GREEDY
Matches the minimum required
|OR OPERATOR
Match first pattern or the other, chainable
(…)CAPTURE GROUPS
Group & extract sub-matches (can be nested)
(?:…)NON-CAPTURE
Groups without saving to capture array
\1,\2BACKREFERENCES
Matches exact text of a previous group
(?=…)LOOKAHEAD
Match only if the pattern follows
(?⇐…)LOOKBEHIND
Match only if the pattern precedes
\d,\s,\wSHORTHANDS
Digits, Whitespace, Alphanumeric
\bBOUNDARY
Word boundary
-
-
ystar — A xorshift64* PRNG implementation in C99 with my own custom constants, tested and verified with various statistical tests including Wald-Wolfowitz Runs Test and Lag-1 Correlation Test.
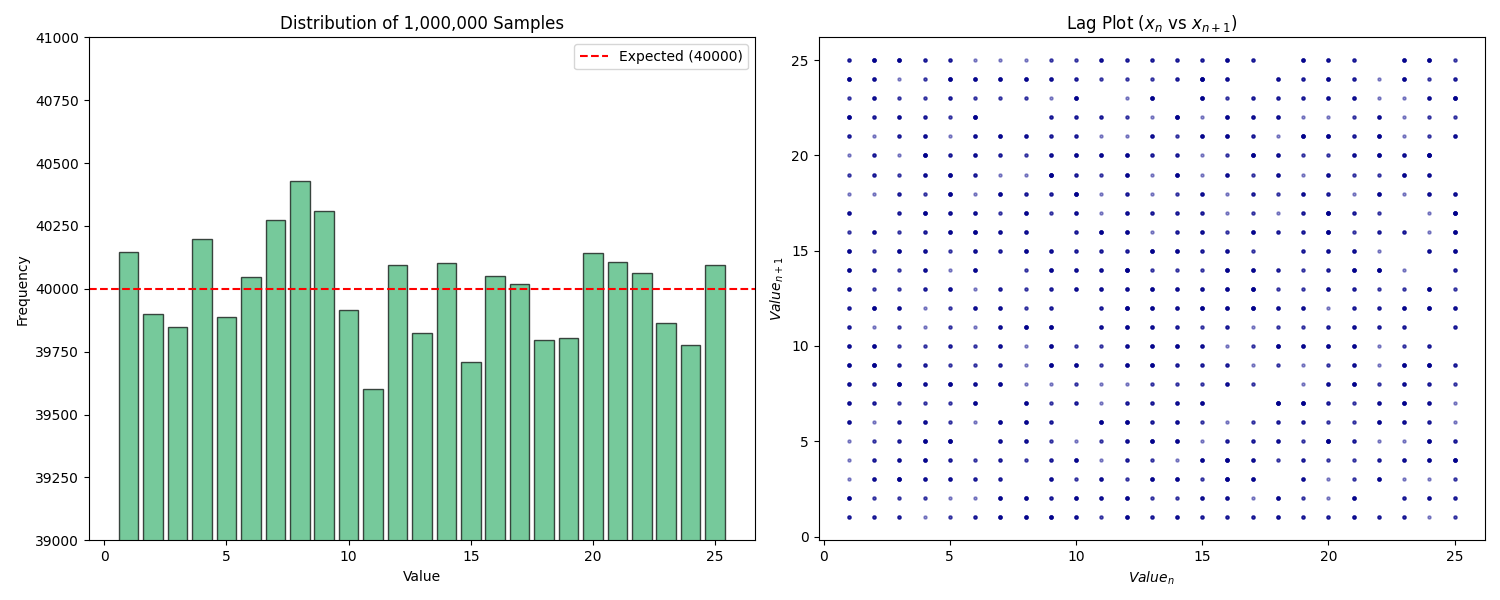
-
bpvm — A simple, fully-functional BytePusher VM implementation in C99.
More Screenshots (click to expand)
-
cchat — A high-performance, minimalist chat system written in C99, built with "Single Source of Truth" server architecture philosophy in mind. Performs non-blocking I/O multiplexing without the overhead of thread-per-connection models.
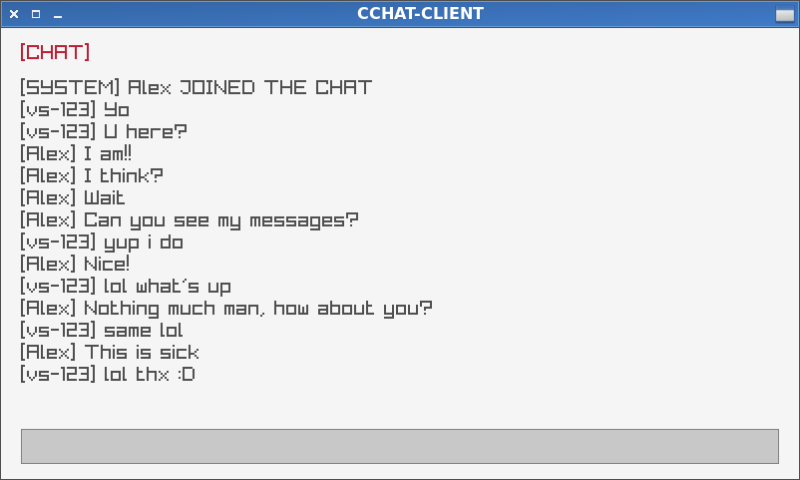
-
pong — A simple recreation of the classic arcade table-tennis game "pong". Built with a focus on deterministic state management and low-latency feedback with the aim to demonstrate a clean C99 implementation of a real-time game loop. Utilises Raylib for hardware-accelerated rendering and a custom particle engine for dynamic visual feedback. Takes a struct-oriented approach where the game logic, input handling and rendering are decoupled via a centralised state structure
-
halloc — A dead-simple, thread-safe, general-purpose, explicit-freelist heap allocator library written in C99
-
cbot — A simple discord bot written in pure C99. Maintains a maximum resident set size between
11.6MBto11.8MB, a native BF interpreter that is resistant to infinite loops, memory exhaustion and out of bound errors, and a simple banking system with persistence. Implements a flat-file banking architecture for state persistence in order to avoid the overhead and black box nature of traditional database engines whilst keeping it reasonably simple to switch to a binary-based format in case it ever becomes a bottleneck. Race conditions related to bank persistence are mathematically impossible by design, visit the repository to learn more. -
barc — A lexicographical permutation-based BWT + local frequency-adaptive MTF transform + multi-byte chunked RLE file-compressor archive utility tool written in C99. This project uses no OS-specific/POSIX/external libraries in order to keep it portable
-
l-tail — A memory-efficient, POSIX-compliant, high-performance, log-scanning utility tool for stream monitoring written in C99.
-
dman — An efficient, POSIX-compliant, policy-based directory-pruning utility tool written in C99
-
qenv — A simple, POSIX-compliant, zero-dependency environment variable inspection utility tool designed for quick and memory-efficient filtering across diverse shell environments.
-
mbf — A custom BF implementation, with the addition of macros
-
dstr — A dead-simple dynamic-string library written in C89. Supports printf-style formatters for string concatenation, written from scratch
-
mswpr — Fully functional Minesweeper implementation in C99, using my own ystar PRNG for mine generation and placement.

-
kernel — A dead-simple kernel written in C99 with LLVM toolchain
-
tegen — A recursive, stochastic text generator for Rust
-
auc — A high-performance, lightweight, cross-platform, thread-safe and dependency-minimal auto-clicker written in C11
-
firethorn — Simple extension for Firefox that brings back English’s lost letter thorn (þ)
-
Royal Hemlock (meta-repo) — Soothing royal-blue light-theme for Emacs and Neovim. This is a meta-repository
I find myself fascinated by the core mechanics of different programming languages and the way they’re implemented. This often leads me to find myself exploring different compilers via Godbolt, where I read and understand the assembly generated by various different compilers. I find it enjoyable to learn and analyse how various compilers handle various optimisation passes and architecture specific optimisations. I treat the translation from code to machine instructions as a field of study in itself.
My time spent with Compiler Explorer has deeply influenced my development workflow. It has helped me develop a habit of making low-level optimisation decisions as I write code. This practice gives me a rough yet grounded intuition about the potential memory layout, cache locality and the precise state transitions the hardware performs during execution of my programs.
As a result of learning and analysing how different compilers target various ISAs, I’ve gained a well familiarity with several architectures including but not limited to x86-64, x86, MIPS, ARM32/64 and MPPA. This has allowed me to reason about code performance across a wide and diverse range of platforms.
This exposure with a diverse range of assemblies has granted me the advantage of being able to intuitively read and understand most assemblies, even for architectures I haven’t formally encountered before. I find this skill incredibly helpful when debugging programs or reverse-engineering.
This grasp on assembly developed over the years, combined with my interest in language implementation, has led me to a much deeper understanding of the core mechanics of a computer. It allows me to evaluate the specific trade-offs and underlying philosophies offered by different programming languages from the POV of how they actually work under the hood.
In addition to code, I enjoy exploring the philosophies of different software and their communities. This curiosity drives my appreciation for Linux, UNIX, *nixes as well as the POSIX standard. I understand and appreciate the historical design patterns and the ideologies emerged historically. I find more interest in the "why" of a system’s design more than I do in the "how" of its execution.
MIPS Compiler Magic — Branch Delay Slot (click to expand)
Consider the following simple C code:
int add(int x, int y) {
return x + y;
}When we compile it with -O3 targeting MIPS, we get this assembly:
add:
jr $31
addu $2,$4,$5Notice something interesting is going on here. It does the addition after returning from the function. What’s going on?
Just FYI:
-
$31is the return address (RA). -
$2holds the return value (V0). -
$4and$5are argumentsxandy. -
jr $31is the jump register (i.e. return) instruction.
At first glance, it looks like the function returns before it ever adds the numbers. However this is a special hardware feature of MIPS called the Branch Delay Slot (BDS).
In a general MIPS pipeline, the instruction immediately following a branch or jump is executed before the jump actually completes.
Hence in this case, the C compiler is actually being smart here. Instead of doing something like:
addu $2,$4,$5 # (cycle 1)
jr # $31 (cycle 2)
nop # (delay slot)The compiler actually reorders the instructions so that the addition happens INSIDE the jump’s delay slot. It essentially hides the cost of the addition within the time the processor spends resolving the jump. We get our result in what feels like a single operation.
This optimisation effectively reduces the branch penalty to zero cycles. This is a crucial feature in early RISC architectures where every pipeline stall was an expensive performance hit.
Honestly it’s pretty interesting to see how the compiler "exploits" specific hardware quirks like this to strip off potential inefficiencies.
PPCI Compiler (click to expand)
Here’s a simple C code
int main() {
int y = 1;
int z = 2;
int x = y + z;
return 0;
}It’s pretty simple, you have an integer x with just the value y + z
Now let’s compile this with a different C compiler. Not GCC, not Clang, we will use the ppci compiler.
We’ll compile using the flags --std=c89 -O0 (link — https://c.godbolt.org/z/Wq7vcv5ec)
This generates the following assembly:
section data
section code
main:
push rbp
mov rbp, rsp
sub rsp, 24
main_block0:
mov r8, 1
mov [rbp, -8], r8
mov r8, 2
mov [rbp, -16], r8
mov r8, [rbp, -8]
mov r11, [rbp, -16]
add r8, r11
mov [rbp, -24], r8
mov rax, 0
jmp main_epilog
main_epilog:
add rsp, 24
pop rbp
retmain: is the int main() { part and main_epilog is the } part (end of main() function)
The main interesting part I wanted to talk about is in main_block0, specifically this part:
...
main_block0:
mov r8, 1
mov [rbp, -8], r8
mov r8, 2
mov [rbp, -16], r8
...These are our int z & int y variables. It’s being stored using register r8 as the temporary register in the stack at positions rbp - 8 and rbp - 16
The real interesting part is that it’s storing the other int at rbp - 16 instead of what you’d normally expect to be rbp - 12.
The thing is that, most compilers that target x86-64, x86, ARM, MIPS, etc. like clang and gcc, typically use 4 bytes for an int.
This means that, given a stack pointer sp, the variables int z & int y should have been stored in the stack register at n bytes away from sp (i.e. sp - n) and the other one must have been stored 4 bytes away from the last one (i.e. sp - (n+4)) like:
main:
mov [rbp - 8], 1
mov [rbp - 12], 2However, notice that in the case of PPCI, it stores them at rbp - 8 and rbp - 16 instead of rbp - 12. The key thing here is that it’s using an offset of 8 bytes instead of 4 bytes.
Question: Does PPCI treat `int`s as 8 bytes instead of 4?
Let’s find out.
Here’s another C program. We’ll compile it with the same compiler flags using PPCI.
int main() {
return sizeof(int);
}Essentially, our main() function should return the size of int.
Here’s the assembly for it:
section data
section code
main:
push rbp
mov rbp, rsp
main_block0:
mov rax, 8
jmp main_epilog
main_epilog:
pop rbp
retNotice the instruction mov rax, 8. That confirms that our int in PPCI is being treated as 8 bytes instead of the usual 4 bytes.
So our previous code seems to be consistent. But wait, most compilers and platforms use 4 bytes for an int, PPCI is using 8 bytes. Does this mean PPCI is breaking the C standard?
Question: Does PPCI break the C standard?
Let’s look at how C standard defines an int:

This screenshot is from the official C standard.
It essentially says that an int must be able to AT LEAST hold a number within the range [−32767, +32767]
The C standard does not say that an int must be 4 bytes, rather it says that it should be able to hold AT LEAST 2 bytes. Note that it’s the LEAST, this means an int can theoretically be as large or as small as the compiler/platform wants, it just needs to be able to hold a number within that range in order to call itself an int.
Thus, most systems use their own convention for convenience.
For example, an int in MS-DOS 2 bytes. The same int in Windows x86 is 4 bytes.
There’s two interesting conventions called LP64 and LLP64. It dictates the size of `long`s, `long long`s, and pointers.
The names themselves are actually shorthands for which types are 8 bytes. L = long, LL = long logng, P = pointer. The 64 at the end says they take up 64-bits of storage.
Majority of UNIX and UNIX-like systems use the LP64 model, whereas Windows uses LLP64 to maintain backward compatibility.
This means that a long on macOS would be 8 bytes, but the same long on Windows would be 4 bytes.
Coming back to PPCI, what does this "an int must be at least 2 bytes" have to do with it?
This implies that, PPCI is actually standard C and its int is perfectly 100% standard-compliant.
Ok now the bigger question, why does PPCI make it 8 bytes instead of 4 bytes?
I’m not quite sure about this, but I believe that PPCI treats it as 8 bytes just so it can use the value directly in rax for simplicity.
If that’s the case, there’s an implication that since it is promoting our 4 byte int into an 8 byte stack, it actually keeps the stack perfectly aligned for CPU processing.
This is actually perfect because an x64 CPU prefers to read data in chunks of 8 bytes rather than chunks of 4 bytes like x86 CPUs.
So yeah, whether it was intended or not, it’s actually convenient for x64 CPUs.
Why XOR EAX, EAX? (click to expand)
Let’s take a very simple C program as follows:
int main(void) {
return 42;
}Compiling this using clang, targetting x86-64 with the highest optimisation using -O3, we get:
main:
mov eax, 42
retmov eax, 42 sets eax to 42 and then ret returns it (as the program’s exit code).
Let’s try another number.
int main(void) {
return 128;
}Compiling this with the same flags as the previous one, we get:
main:
mov eax, 128
retNotice that both the assemblies are pretty much identical, except the 42 changed to 128.
Seems fair enough, let’s try the usual return 0;. As you might expect, we’re gonna get mov eax, 0.
int main(void) {
return 0;
}Compiling this with the same setup, we get:
main:
xor eax, eax
retInteresting, looks like we didn’t get the mov eax, 0 we were expecting. Instead, we got xor eax, eax.
Why’s it tryna be all fancy in here? Why xor instead of the usual mov? Turns out, there’s an interesting reason behind this.
If we strip away the fancy stuff, assembly languages are just syntactic sugar for machine code. Instead of manually writing stuff like 48 b8 88 77 66 55 44 33 22 11 and 48 01 d8, we write mov rax, 0x1122334455667788 and add rax, rbx because these are much more readable and easier to maintain.
In this case, when we have mov eax, 128 in x86-64, it usually encodes to something like b8 80 00 00 00, where b8 is the opcode for mov eax and 128 is encoded as 80 00 00 00 (0x80 = 128). The reason it’s 80 00 00 00 instead of 00 00 00 80 is because x86 is little endian, hence the least significant byte appears first.
Similarly, mov eax, 0 would encode to b8 00 00 00 00, and it makes perfect sense why.
What about xor eax, eax? xor eax, eax actually encodes to just 31 c0. 31 is the opcode for xor, and c0 is the mod r/m byte. In binary, c0 turns to 11 000 000, where 11 says that it’s a "register to register" kind of operation (no memory addresses involved), and both of the 000`s refer to register `eax.
Okay, let’s get this straight. mov eax, 0 becomes b8 00 00 00 00, and xor eax, eax becomes 31 c0. Cool, so what? Why does that make xor eax, eax any better?
The idea is that, mov eax, 0 encodes to 5 bytes, whereas 31 c0 is just two bytes. This implies that, when you have a program with thousands of zero-initialisations, the compiler’s choice of xor eax, eax over mov eax, 0 actually shaves off several potential kilobytes off your binary size. This makes the binary smaller, and hence you’re gonna have better I-cache density, hence fewer cache misses.
In addition to this, modern CPUs don’t really "calculate" this xor eax, eax operation. The thing is that there’s a logical component in your CPU called "register renamer". Basically, it’s sort of a dictionary full of several "idioms". So when it sees a common pattern like xor eax, eax, the register renamer recognises it from its dictionary and immediately marks the register zero instead of sending it to the ALU. This makes the instruction execute at zero latency and also doesn’t hog up an execution port.
There’s also a side effect related to this in x86-64. The thing is that a x32 operation like xor eax, eax automatically zero extends to the full x64 rax register. This implies that xor eax, eax clears all 64 bits. This makes xor eax, eax more efficient than xor rax, rax because the x32 one also avoids REX prefix byte which saves even more space.
What’s even cooler about this is that this xor operation tells the CPU that eax no longer depends on whatever its previous value was. This actually gives the CPU a green light to perform "out of order" execution, meaning it can do its next task without having to wait for the old eax to retire.
Name Mangling — C++ (click to expand)
In regular C, every function is supposed to have a unique name (an identifier). When you have a function that adds two integers, you might name it add. Later when you need a function to add two floating-point numbers instead of integers, you’d have to come up with a different name it something other than add whilst keeping it accessible, maybe add_float for example.
C++ however removes this restriction by allowing the "signature" of the function (its name plus its parameters) to act as its unique identity within the source code. The original intent of this was to allow for more intuitive APIs and to solve the add vs add_float problem.
Let’s take a closer look at the add vs add_float example in C.
int add(int x, int y) {
return x + y;
}
int add_float(float x, float y) {
return x + y;
}Notice the names are different. As a user, I now have to be aware of the fact that both add() and add_float() exist.
Cool, what about C++? Since C++ removes this restriction of having unique names for functions, we could just do something like:
int add(int x, int y) {
return x + y;
}
int add(float x, float y) {
return x + y;
}Seems pretty simple. When I call add(5, 10), the compiler looks at the arguments types (two integers) and matches the call to the first definition. When I call add(5.5f, 2.1f), it matches it to the other.
Even though the C++ compiler is perfectly happy with this, the linker however (the tool that combines multiple object files into a single executable) is not as flexible. Linkers operate on unique symbol addresses and can’t distinguish between identical identifiers. This is why you get "multiple definition" errors.
Since C++ allows you to have two things with the same name, the compiler must have a way to tell the linker that the two add() functions are different.
As a compiler, we need a way to be able to transform our add functions into unique symbols whilst remaining deterministic. We wish be able to mangle our add() functions.
Let’s first check the C++ standard and see if it says anything about it.

It gives us a hint that we need to use the signature for name mangling. However, searching the whole PDF, we don’t see anything that tells about how to mangle a function name. Oh well, looks like we’re on our own.
Okay so before we get started with mangling, we need a way to make sure that our beautiful add() function does not collide with ordinary C functions. We could use a prefix for this, say _Z.
Now both of the add() functions become _Zadd. However, we still need to add bit more structure to prevent ambiguity with different name lengths. To deal with this, we could add the length of the function name right after our prefix. The symbol now becomes _Z3add. However, we still have a collision between both add() functions.
The only difference left between the two is the parameter list. The standard gave us a hint that we could use the signature for name mangling, and parameter list does count as part of the signature. How can we use the parameter list to tell them apart? How can we encode them into the symbol?
We obviously can’t use the parameter names themselves, since you can have both int add(int x, int y) and float add(float x, float y) even though they use the same parameter names x and y. What we do know is that, two functions with the same name must have different parameter type lists. So instead of parameter names, we could use the types itself. In this case, we have two int and two float, let’s use i to represent int and f to represent float.
We’re gonna append these representations to the symbol name according to their order. The first add() takes two integers, so we append ii and get _Z3addii. The other add() function takes two floats, so we append ff and get _Z3addff. Hence, the mangled names are _Z3addii and _Z3addff respectively.
Congratulations, you just invented GCC name mangling! The linker now sees two different symbols _Z3addii and _Z3addff, even though you wrote two add() functions in your C code. This is the core of the *Itanium C ABI*, used by both GCC and Clang.
Wait, so this is how GCC would mangle my beautiful add() function? I don’t believe you.
Fair enough, let’s try it on Godbolt.
To keep it simple, we’ll leave the bodies empty:
int add(int x, int y) {}
float add(float x, float y) {}When you compile this with x86-64 gcc 4.0.4 using -O3 flag, you get:
_Z3addii:
rep ret
_Z3addff:
rep retAs we can see, the add() functions were mangled to _Z3addii and _Z3addff, just like what we came up with.
Clang uses the same Itanium ABI as GCC, we can expect to see the same mangled names when we compile with clang:
_Z3addii: # @_Z3addii
_Z3addff: # @_Z3addffQuestion: Does MSVC mangle names the same way as GCC and Clang?
Let’s find out. We’ll be compiling the following C++ code using MSVC:
int add(int x, int y) {return 0;}
float add(float x, float y) {return 0;}Specifically, we’ll be using x64 msvc v19.50 VS18.2 with /O2 flag. We get:
x$ = 8
y$ = 16
?add@@YAHHH@Z PROC ; add, COMDAT
xor eax, eax
ret 0
?add@@YAHHH@Z ENDP ; add
x$ = 8
y$ = 16
?add@@YAMMM@Z PROC ; add, COMDAT
xorps xmm0, xmm0
ret 0
?add@@YAMMM@Z ENDPLooks like our add() functions were mangled into ?add@@YAHHH@Z and ?add@@YAMMM@Z instead of what we saw earlier.
MSVC’s mangling seems to be a bit of a mess. It’s notorious for being a bit more complex and its interesting use of characters like ?, @ and $.
That’s because MSVC focuses on encoding as much information as possible into the symbol, including calling conventions and access levels.
Let’s focus on int add(int x, int y) and see how MSVC mangles it into ?add@@YAHHH@Z.
The first ? is equivalent to GCC’s _Z.
Next we have the name of the function add. Notice that it isn’t prefixed with the length of the symbol. Unlike GCC, it reads until it hits a terminator. The @@ acts as the terminator for the name (and in other cases provides namespace/class information).
YA represents the calling convention, usually means cdecl which is the default. If it were something like a private member of a class, YA would change to IA for thiscall. This tells us that MSVC encodes the access of a function as well.
We then see HHH. Remember how we used i for int earlier? MSVC too has its own alphabet for types that goes H for int, M for float, N for double, X for void and PA for pointers.
The first H in HHH is the return type. The second H is the first parameter and the third is the second parameter. Notice that, unlike GCC, MSVC also includes the return type in its mangled name. The idea is to let the linker use it as an extra safety check to ensure you aren’t linking against a version of the function that returns something different.
Finally, @Z is again another terminator, this time it’s for the parameter list. It tells where the parameters end.
The same mangling logic applies for float add(float x, float y). Since it uses three float types, the HHH in the mangle would become MMM and hence you’d end up with ?add@@YAMMM@Z.
Congratulations, you can now read GCC, Clang and MSVC mangled symbols! Pretty cool, right?
| Aspect | Choice |
|---|---|
Environment |
|
Text Editor |
|
OS |
|
WM |
|
Shell |