{kind=link}

This is an R project on data cleaning of an IMBD movie list. This project is to ensure that the data is accurate, complete and consistent so that it can be used for analysis or other application with confidence in its quality.
The dataset contains information about movies such as title ID, release year, genre, duration, country, content rating, director, income, votes, and score. The data is not cleaned and contains several inconsistencies such as different date formats, missing values, and inconsistent values. The problem is to clean and pre-process the data to make it suitable for further analysis. Specifically, the data needs to be standardized to a common format, missing values need to be handled, and inconsistent values need to be corrected. The goal is to create a clean dataset that can be used to analyse the .IMBD data. For example:
- The Release year column (e.g., '09 21 1972', '22 Feb 04', '10-29-99'), which need to be converted to a consistent format (e.g., 'YYYY-MM-DD') for analysis.
- Some rows contain missing or invalid data in the Duration column (e.g., 'Nan', 'Inf'), which need to be cleaned or imputed to ensure data integrity.
- The Genre column contains multiple genres separated by commas, which need to be split into separate columns to facilitate analysis.
- The Content Rating column contains abbreviated characters which needs to be in their full form for those who would not know the meaning (e.g., 'R', 'Not Rated', 'PG-13', 'Approved') that need to be standardized for analysis.
- The Income column contains dollar signs and commas that need to be removed and the values converted to integers for analysis.
- The Votes column contains commas that need to be removed and the values converted to integers for analysis.
- The Score column contains inconsistent decimal separators (e.g., ',' and '.'), which need to be standardized for analysis.
- Some rows contain missing or invalid data in various columns, which need to be cleaned or imputed to ensure data integrity.
Data wrangling and cleaning are skills used for this project such as manipulating, reshaping and transforming data into various formats and structures. This project utilizes several R packages including stringr, dplyr, visdat, tidyr, scales, and lubridate to achieve the desired data cleaning tasks.
This dataset was acquired from a Twitter user who shared a link to a Google Drive containing the data.
The dataset was assessed for abnormalities and data quality. It was noted that all the data are in the character class, and there are some missing values.
Using visdat to visually show us what our column looks like

Using vis_guess to ask R to help us look through the data and guess what class they are supposed to belong to
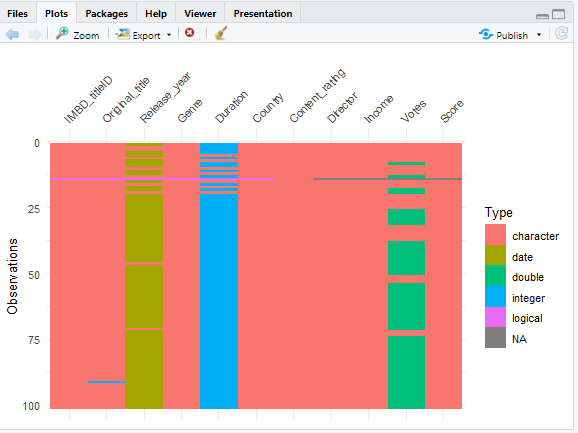
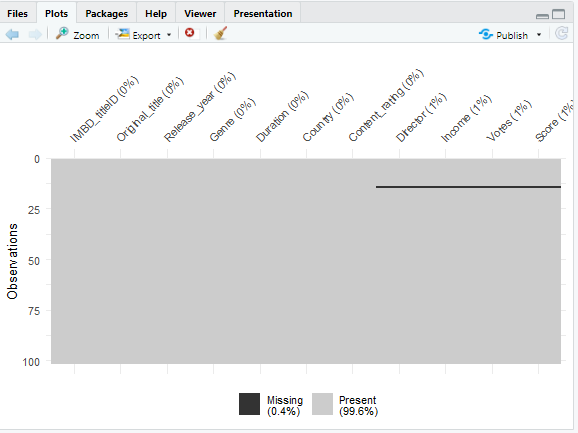
Using vis_miss to visualize column with missing observations
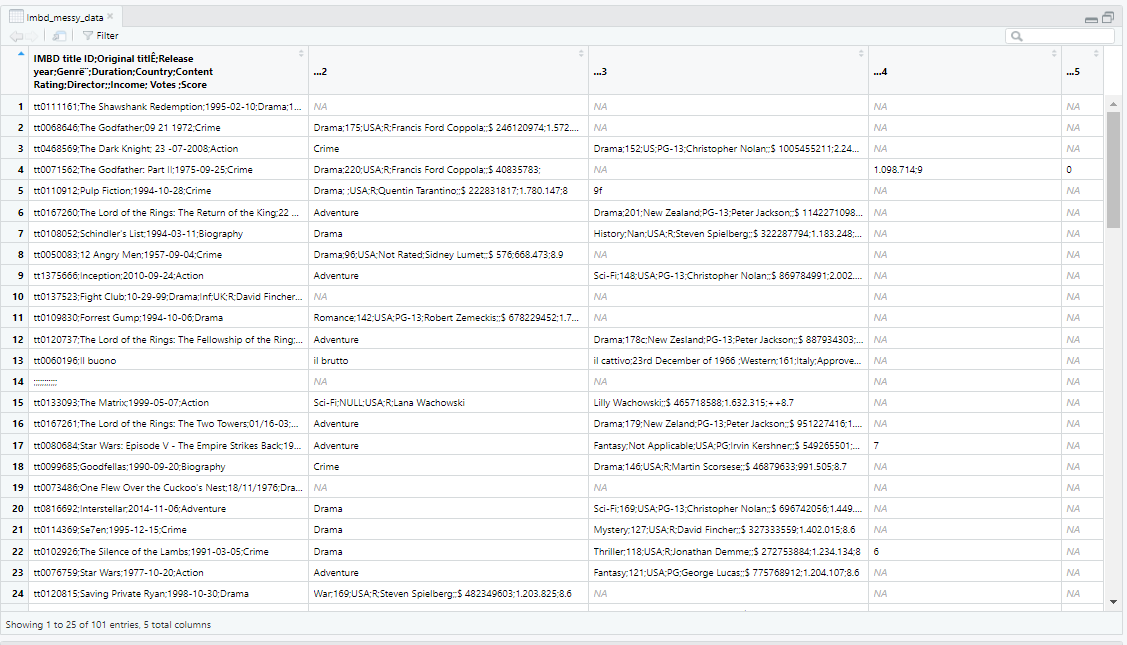
When I initially downloaded the dataset, I viewed it in Excel before importing it to R. Since the dataset was in a CSV file format, I converted it to an Excel file. Before cleaning, the dataset had approximately 101 rows and 5 columns. However, after cleaning, one row had no data and was removed, resulting in a total of 100 rows. Additionally, the number of columns increased to 11 because the initial columns were not properly distributed into their appropriate variables. Furthermore, the dataset was only separated by a semicolon instead of being separated by colon, which required additional cleaning steps. You can see view the original data here
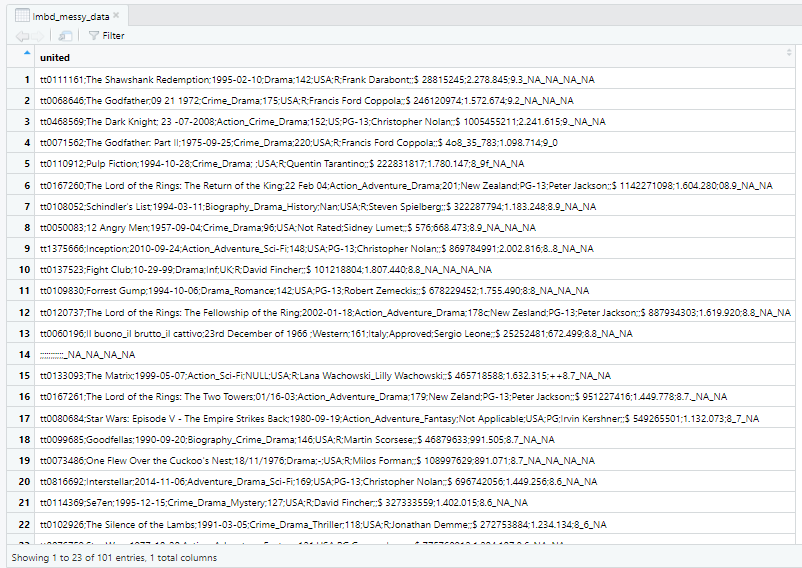
I combined all columns into a single column using the 'unite' function and used the 'mutate' function to ensure that all delimiters were consistent. Then, I separated the data into their respective column .
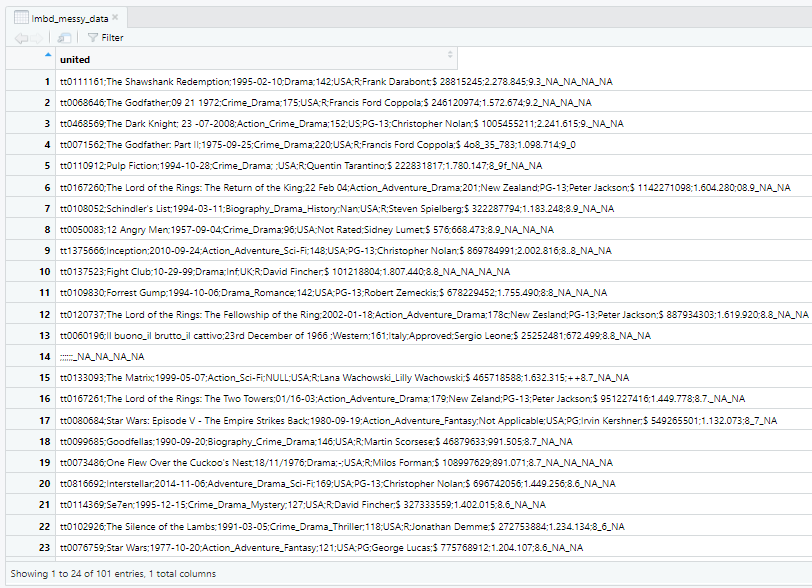

- It has a character of 9 string length and no duplicate.

- Corrected some misspelled words with accented alphabets
| Messy | Cleaned |
|---|---|
 |
 |
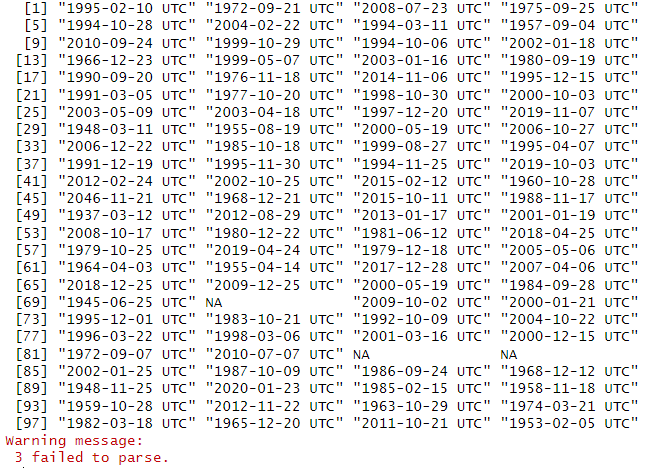
- Made the date format consistent
- Extracted year from the date
- Manually inserted the correct date gotten from imbd website online to fill the missingness
- Converted to a numeric class
| Messy | Cleaned |
|---|---|
 |
 |
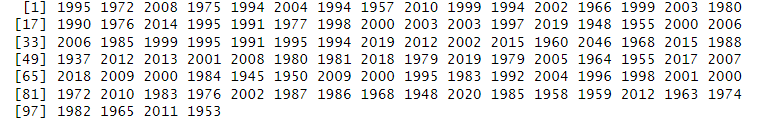
- Changed the underscores to commas
| Messy | Cleaned |
|---|---|
 |
 |
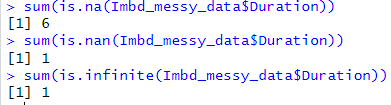
- Had 5 NAs, a NaN and an Inf
- Manually inserted the correct duration from IMBD website online to fill the null observations
- Converted from class character to class numeric
| Messy | Cleaned |
|---|---|
 |
 |

- Corrected the misspelled country names
| Messy | Cleaned |
|---|---|
 |
 |
- Replaced the abbreviated content rating to its full form
- Converted to a factor since it is a categorical data having a total of 6 levels
| Messy | Cleaned |
|---|---|
 |
 |
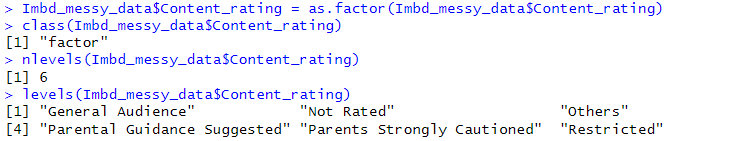
- Changed accented alphabet to a proper alphabet,
- Replaced underscore with comma where we have more than a director
| Messy | Cleaned |
|---|---|
 |
 |
- Removed the dollar sign to be able to convert to a numeric class,
- Renamed the column to income_usd to indicate that it is in dollar format
| Messy | Cleaned |
|---|---|
 |
 |
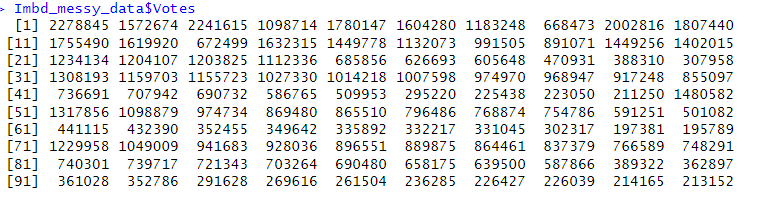
- Removed non numeric characters (.) and converted to a numeric data
| Messy | Cleaned |
|---|---|
 |
 |
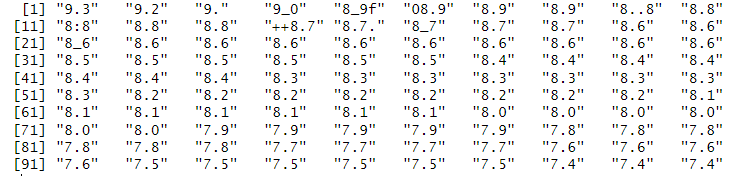
- Removed non-alphabetical characters,
- Removed leading 0,
- Added decimal points to those without,
- Removed extra decimal point,,
- Converted to numeric data
| Messy | Cleaned |
|---|---|
 |
 |
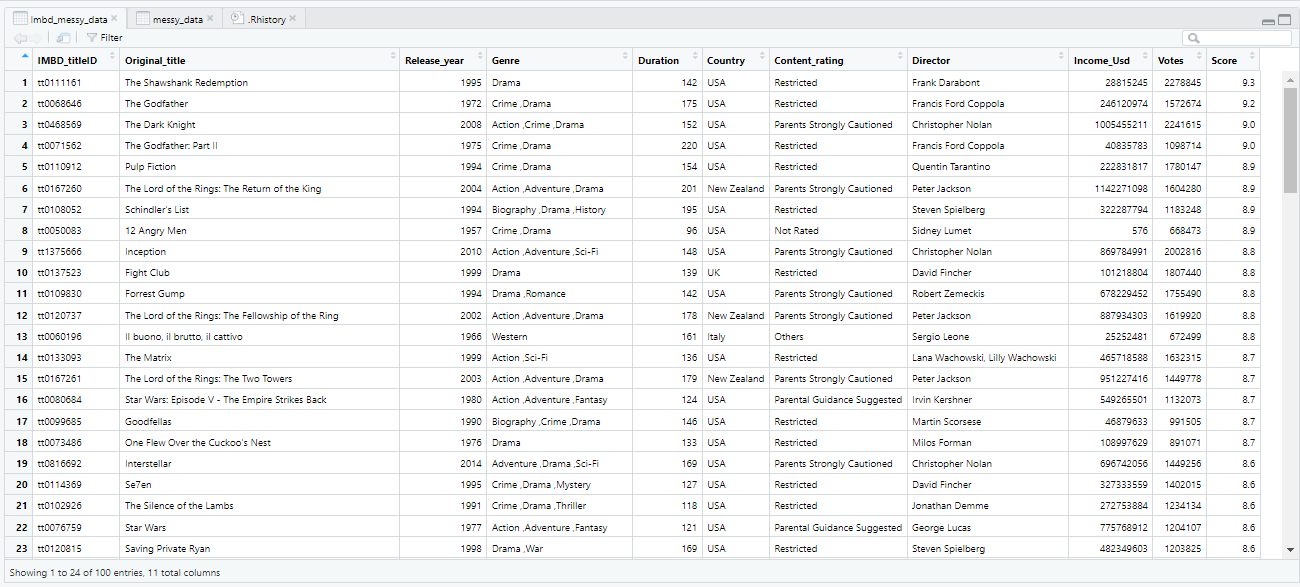 You can view the cleaned data here
You can view the cleaned data here
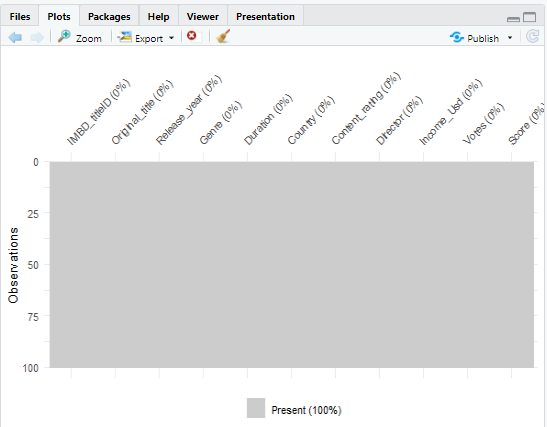
Now we are checking to confirm there are no missing observation
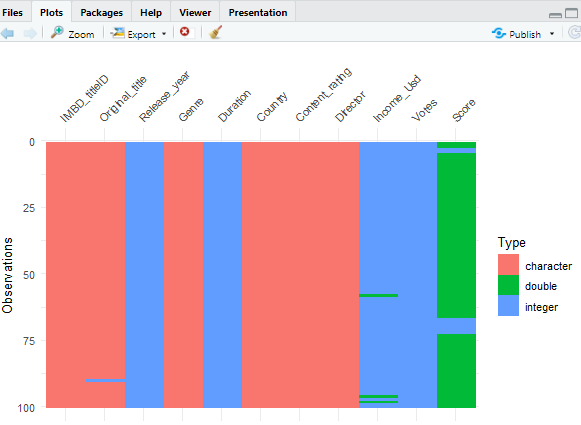
Now we are using the vis_guess to check if they are in their right classes
The cleaning process for the dataset has some limitations that should be noted. Manually inserting data slowed down the cleaning process and may introduce errors or biases in the data if not done carefully. Additionally, some columns in the dataset have missing values or incomplete data, which may limit the analysis that can be conducted. In terms of the nature of the dataset, there are also some limitations to consider. The dataset only includes information about the top-rated movies on IMBD, which is a relatively small subset of all movies ever made, making it limited in scope. Additionally, the dataset is based on user ratings, which could potentially affect the representativeness of the sample and the accuracy of the ratings due to biases from self-selection, non-response, and rating manipulation. Lastly, the dataset only includes movies up to a certain point in time and may not reflect more recent trends or changes in the movie industry
After cleaning the dataset, few out of the many insights that can be obtained for instance are : The Lord of the Rings trilogy has three movies in the top 15, with The Return of the King having the highest score of 8.9. The top-rated movies are mostly crime and drama, followed by action and adventure, and are mainly from the United States. The content ratings of top-rated movies vary, with R being the most common, followed by PG-13 and PG. Interestingly, there is no clear correlation between a movie's income and its rating, as some high-rated movies had a low income, while some lower-rated movies had a high income. Furthermore, the number of votes for a movie is positively correlated with its rating, indicating that popular movies tend to have higher ratings. Overall, the top-rated movies in the dataset are diverse in terms of styles, genres, and origins, suggesting that there is no single formula for making a highly-rated movie. Finally, the purpose of data cleaning is to ensure the accuracy, consistency, and completeness of the data, which can help prevent errors and enable more accurate analyses and predictions.
You can view the step-by-step process I followed to clean the data here