먼저, European Cardholders가 만든 2일동안 발생한 284808개의 카드 거래 데이터를 가져온 다음, 이 데이터를 7:3의 비율로 train data(159492)와 test data(68355)로 나눈다. input data들을 정규화 시킨 뒤, SMOTE를 이용하여, train data 중에 사기 거래 data를 늘리고 DNN 알고리즘으로 학습시킨다. 학습된 model을 통해, test data가 사기 거래와 정상 거래 중 어디에 속하는지를 판단한다.
OS: Windows 10
IDE: Pycharm 2021.1
-
DNN 알고리즘 :
DNN은 입력층(input layer)과 출력층(output layer) 사이에 여러 개의 은닉층(hidden layer)들로 이뤄진 인공신경망이다.

-
layer
- hidden layer 수
hidden layer 수는 1개로 정하였다. 수업시간에 배운 내용에 따르면 대부분 문제는 hidden layer 한 개만으로도 좋은 결과를 얻어낼 수 있고, 오히려 hidden layer의 개수를 늘릴 경우 학습에 걸리는 시간이 늘어나기 때문이다. 직접 코드를 짜본 결과, hidden layer를 1개로 했을 때와 2개로 했을 때의. 정확도는 큰 차이가 없었으나, hidden layer가 2개 일때가 1개 일때보다 학습에 소요되는 시간이 오래 걸렸다.
-
node
-
input layer의 node 수
input layer의 node수는 29개로 정하였다
-
hidden layer의 node 수
hidden layer의 node수는 input layer의 node 수(29개)와 output layer의 node 수(1개)의 평균인 15개로 정하였다.
-
output layer의 node수
신용카드 거래 내역이 사기 거래인지, 정상 거래인지 판단하는 문제이므로, 0과 1 두개의 class로 분류할 수 있다. 따라서 output layer의 노드 수를 1개로 결정했다.
-
-
Amount : 첫 번째 거래와 각 거래 사이의 경과 된 시간(초)
-
V1 ~ V28 : PCA로 얻은 미리 스케일링 된 변수들로 기밀 유지 문제로 원래 기능과 배경 정보를 제공하지 않는 비공개 된 input feature cf. 주어진 data의 feature 수는 31개였으나, 사기 거래 판별에 의미가 없다고 판단되는 index와 time값을 제외하여 총 29개의 feature를 input feature로 사용했다.
-
Input feature plotting :
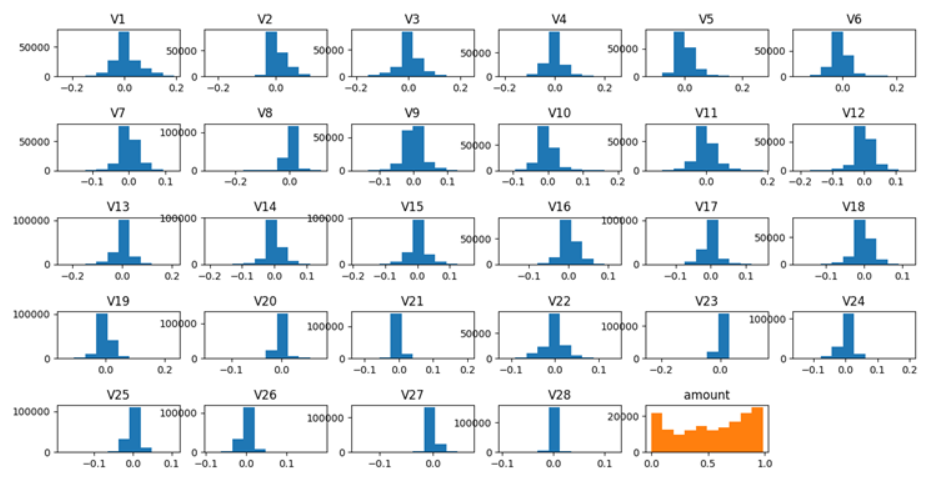
모델링에 사용해야할 29개의 input feature값을 보면 scale 차이가 심해 학습시키기에 적당하지 않음을 알 수 있다. 따라서 sklearn의 normalize함수를 이용해 모든 input feature 데이터를 -1과 1사이의 값으로 정규화를 해주었다. 위 사진은 정규화를 한 결과이다.
-
데이터 전처리
class 별 비율에 대해서는, 약 16만개의 train data 중 정상거래 data의 개수는 159198개, 사기 거래인 data의 개수가 293개로, class별 편차가 지나치게 컸다. 이런 경우, 모델이 정상 거래라고 판정하는 쪽으로 치우칠 가능성이 있어 오버 샘플링을 통해 사기 거래와 정상 거래의 비율을 어느정도 맞춰주어야 한다. 따라서 SMOTE 기법을 이용하여 정상 거래 : 사기 거래의 비율을 약 10000:18에서 1:1으로 늘려 주었다.
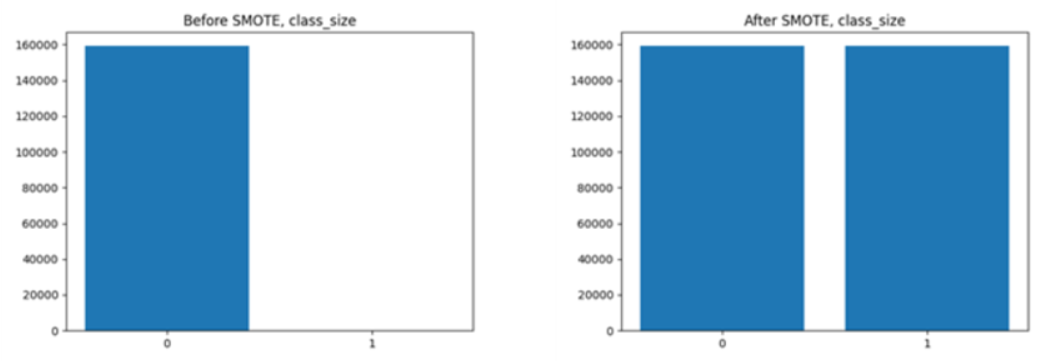
<SMOTE 전후의 정상 거래 data와 사기 거래 data 개수 비교>
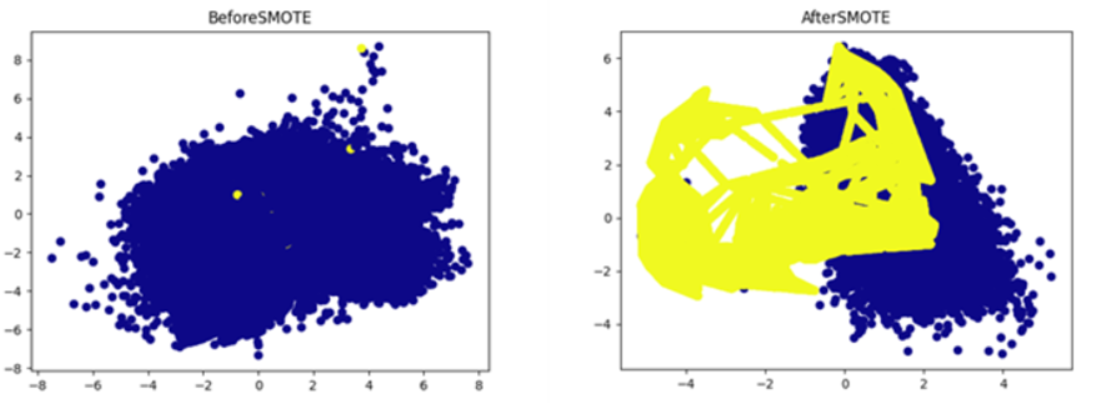
<SMOTE 전후의 data분산 정도 차이. 황색 점이 사기 거래 데이터를 의미>
정상 거래이면 0, 사기 거래이면 1을 label로 갖는다.
model = Sequential([
InputLayer(input_shape=(29,)),
Dense(15, activation='elu', name='hidden_layer'),
Dense(1, activation='sigmoid', name='output_layer')]
)
위 코드는 dnn 모델을 구현한 소스코드이다. tensorflow 라이브러리의 sequential을 이용해 입력층 1개, 은닉층 1개, 출력층 1개로 총 3개의 layer을 만들었으며, 각각의 node 수는 29개, 15개, 1개로 설정하였다. hidden layer의 activation 함수는 elu를, output layer의 activation 함수는 sigmoid를 사용하였다. Dense()는 nerual network에서 층을 추가할때 쓰이는 함수이다.
def plot_scatter_data(X,Y,name):
scaled_data=StandardScaler().fit_transform(X)
pc = PCA(n_components=2).fit_transform(scaled_data)
df = pd.DataFrame(np.c_[pc, Y], columns=['x1', 'x2', 'y'])
plt.scatter(df['x1'],df['x2'],c=df['y'],cmap=plt.cm.plasma)
plt.title(name)
plt.show()
StandardScaler() 함수를 통해 X data를 scaling한 뒤에, PCA를 통해 2차원으로 압축시킨 뒤, DataFrame을 통해 압축시킨 data와 Y data를 붙인다. 마지막으로, scatter함수를 통해, 2차원에서 클래스별로 분산된 data들을 색깔별로 plotting한다.
model.compile(loss='binary_crossentropy', optimizer=keras.optimizers.RMSprop(lr=learing_rate), metrics=['accuracy'])
위의 구현한 model을 학습시키기 전에 compile로 환경설정을 맞춰줘야한다. loss함수는 binary crossentropy으로, optimizer는 RMSprop로, 평가지표는 accuracy로 설정하였다.
training = model.fit(X, Y, epochs=100, batch_size=2000, validation_data=(x_val_normal, y_val))
fit함수는 데이터를 훈련시키는 함수입니다. X는 input data, Y는 target data (여기에서는 0또는 1의 배열) 입니다. epochs는 모델을 몇 번 훈련시킬지, 반복하는 수를 뜻하고 batch_size는 전체 데이터에서 random으로 몇 개를 뽑아서 훈련시킬지 정하는 크기입니다. validation data는 학습 반복이 끝날 때마다 훈련이 잘 되고 있는지 평가할 때 쓰이는 data라고 보면 됩니다.
model.evaluate(x_test_normal, y_test[:, 1], batch_size=x_test_normal.shape[0])
evaluate는 구축해놓은 모델을 test data로 검증을 해보는 라이브러리다. 매개변수 앞에서 부터 차례로 정규화를 거친 x_test data, 그에 대한 결과값인 y_test[:,1]을 넣어준다. batch_size는 앞서 썼던 fit 라이브러리의 batch_size와 비슷한 비율이 되도록 하였다. 그래서 test data는 train data의 크기보다 2배정도 작기 때문에 fit의 batch size보다 2배 작게 설정했다. 최종적으로 batch_size= 1000으로 결정했다.
binary classification에서 활성함수로 sigmoid 함수를 사용하는 경우, x값이 매우 크거나 매우 작을수록 sigmoid 함수의 기울기는 0으로 수렴한다. 이는 다시 말해 classification 문제에서 손실함수로 MSE를 사용하면 학습속도가 저하된다는 뜻이므로, 이번 과제에서는 손실함수로 Binary Crossentropy를 사용하였다.
중간 발표와 달리, 마지막 layer의 activation 함수는 relu에서 sigmoid로 수정하였다. 이 프로젝트의 주제는 정상거래와 사기거래임를 구분하는 것으로, output class가 0 또는 1이기 때문에 함수값이 0 또는 1로 수렴하는 sigmod를 선택했다. 현재 모델이 출력해야할 output이 어떤 형태인지에 따라 결정한 것이다. activation 함수의 원래 역할은 "복잡도"이지만, 마지막 layer의 activation 함수는 input/hidden layer들의 activation 함수와 역할이 다르다.
가설함수는 wx+b이고, 중간중간 layer에 activation 함수가 없다고 가정하자. 그럼 아무리 layer을 깊게 쌓는다고 해도 하나의 linear 연산으로 나타낼 수 있게 된다. 따라서 비선형 함수를 activation 함수로 사용하여 모델의 복잡함을 증가시켜 층을 쌓는 혜택을 얻는 것이다. 하지만 마지막 layer의 activation 함수는 다음 layer가 없으므로 값을 변형시켜 넘겨줄 필요가 없다. 따라서 프로젝트 주제인 카드 사기 거래 탐지의 특성에 맞게 sigmod함수를 쓴 것이다.
활성화 함수로 ELU를 사용했다. 활성화 함수의 후보들로 sigmoid, tanh, ReLU, ELU가 있었으나, ReLU와 ELU가 활성화함수의 단점을 최대한 보완한 함수들이라 최종적으로 이 둘을 비교하여 정하였다. ReLU는 sigmoid, tanh 함수와 비교하여 학습이 빠르며, gradient vanishing 문제를 해결했다는 장점이 있다. ELU는 이러한 ReLU의 장점을 포함하면서 Dying ReLU의 문제를 해결한 함수이다. epoch가 늘어날수록 ReLU와 ELU의 accuracy가 비슷해지기 때문에, 두 함수의 비교 기준으로 accuracy와 loss를 사용하였다. 밑의 그래프에서 나타나듯이 ELU함수의 loss가 더 낮아 최종적으로는 ELU를 activation 함수로 사용하였다.
<img src="https://user-images.githubusercontent.com/52345499/135884128-68c2bf51-7d9b-4ab3-9181-d070c22ca681.png" width="500">
<epoch값에 따른 ReLU와 ELU의 accuracy, loss 비교>
데이터를 하나하나 넣어 학습시킬 경우, 큰 cost를 갖는 data가 들어오면 overshooting이 발생할 수 있기 때문에 mini batch를 사용하여 학습 속도를 증가시키고, overshooting을 방지하였다. 평가 시에도 mini batch를 사용하여 평가 속도를 증가시켰다. 전체 데이터를 몇번 이용할 것인지를 의미하는 epoch값과 한번에 몇개의 data를 학습시킬 것인지를 의미하는 batch값은 여러 값을 직접 돌려보고 결정하였다. 모델의 가중치를 몇 번 갱신시킬 것인지를 의미하는 step값은 따로 설정하지 않아 batch size와 전체 data 개수에 따라 자동으로 결정되도록 하였다. 아래의 그래프를 보면, epoch는 100으로 고정시키고 batch size를 다르게 하면서 plotting을 해봤다. 그 결과, batch size가 100, 1000일 때와 2000일 때는 결과값이 비슷하고, 데이터 전체 크기를 batch size로 잡은 경우는 loss와 accuracy가 현저히 떨어지는 것을 볼 수 있다. batch size를 100으로 설정해서 실행시켜 봤을 때에는, batch size를 1000과 2000으로 설정해서 실행시켜 봤을 때보다, 실행시간이 훨씬 길었다. data 전체를 학습시키기 위해서, 밑에 있는 공식을 참고해, batch size를 2000으로 결정하였다.
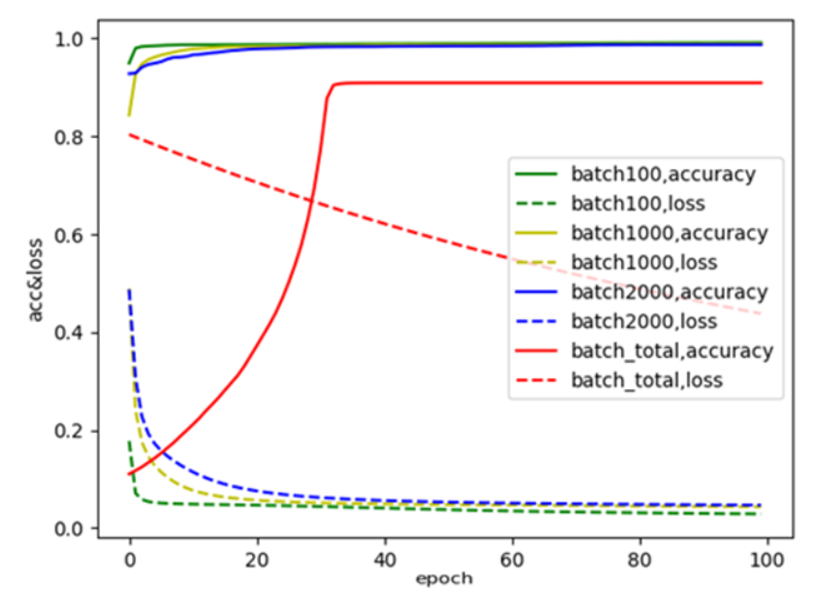
<batch size별 accuracy, loss 비교>

<smote 비율에 따른 f1 score의 값 비교>
위 사진은 smote 비율에 따른 f1 score입니다. smote를 하지 않았을 때와 smote를 했을 때를 비교해보면, smote를 했을 때가 f1 score 값이 훨씬 잘 나옴을 알 수 있습니다. 추가적으로, 최적의 smote 비율을 찾기 위해 plotting을 한 결과, 1일때 f1 score가 제일 높아 smote의 비율을 1로 정하였습니다.
learning rate가 너무 큰 경우에는 overshooting이 일어나 최소값을 찾는게 아니라 오히려 발산형 그래프가 될 수 있는 위험이 있고, learning rate가 너무 작은 경우에는 학습속도가 너무 느려서 원하는 값을 찾기 힘들 수 있다. 0.00001에서 1.0까지 learning rate값을 10배씩 증가시켜서 비교해 보았다. 그래프는 epoch에 따른 loss 추이를 나타낸 것이고 learning rate에 따라서 다양한 기울기를 관찰할 수 있었다. 0.00001과 0.0001(파랑, 주황 그래프)는 loss의 변화가 너무 느린것을 보아 학습 속도가 현저히 느리다는 것을 파악할 수 있다. 그에 비해 0.01이상의 수 부터는 학습이 제대로 진행되는지 관찰하기가 힘들어지고, learning rate가 10이상일 때는 overshooting이 일어나 값이 튀는 것을 확인할 수 있었다. 결론적으로 학습이 가장 이상적으로 진행되는 0.001 값을 learning rate로 채택하게 되었다.

<learning rate에 따른 loss 비교>
모두 동일한 조건으로 환경을 구성하고 optimizer 함수만 바꾸어 비교해 보았다. 9개의 라이브러리 중 자주 쓰이는 SGD, Adam, RMSprop 클래스를 가져왔다. 3개의 함수 또한 accuracy에서는 큰 차이를 보이지 않아서 loss를 기준으로 비교해 보았고 그 결과 RMSprop가 가장 빠르고 작은 loss를 보여서 RMSprop을 optimizer 함수로 사용하게 되었다.
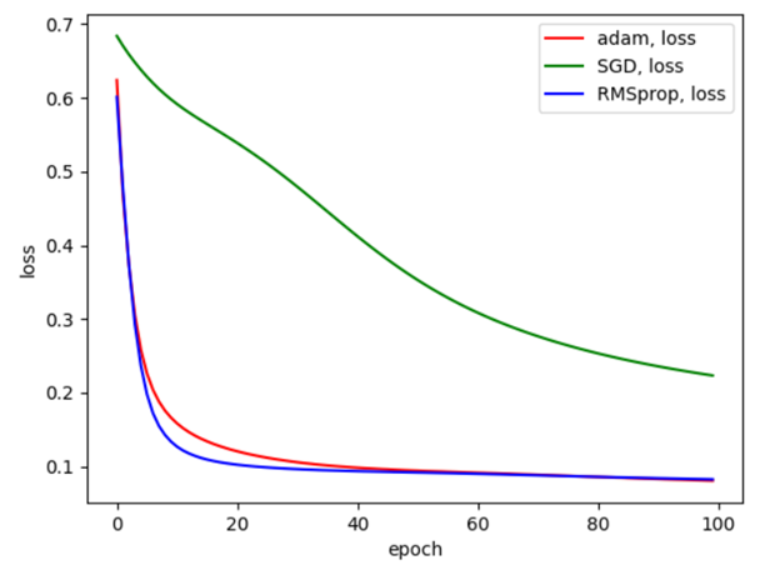
<optimizer 함수의 종류에 따른 loss 비교>
학습이 잘 되었는지, 결과를 평가하기 위해 f1-score을 사용하였다. accuracy와 loss 값만으로 결과의 성능을 예측하기에는 데이터의 특성상 데이터 불균형이 심하기 때문에 추가적인 평가 지표가 필요하였다. f1-score을 구하기 위해선 precision, recall 값이 필요하다. precision(정밀도)란, 모델이 true라고 분류한 것 중에서 실제 true인 것의 비율을 뜻한다. recall(재현율)이란, 실제 true인 것 중에서 모델이 true라고 예측한 비율을 뜻한다. 최종적으로 f1-score은 다음과 같이 구할 수 있다.
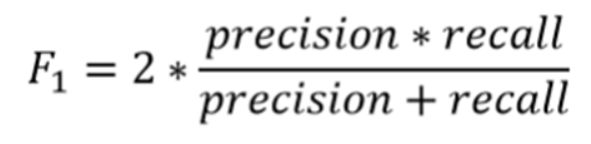
<f1 score를 구하는 공식>
밑의 사진은 epoch=100, batch=2000, smote=1 로 했을 때의 precision, recall, f1-score을 plotting 한 결과이다. train data의 plotting 그래프와 validation data의 plotting 그래프를 보면 거의 비슷한 값을 가짐을 알 수 있다. 또한 epoch가 증가할수록 precision, recall이 점차 증가되는 모습을 보아 잘 학습됨을 알 수 있다. 최종 f1-score는 0.9613으로 학습이 잘 되었음을 보여준다.
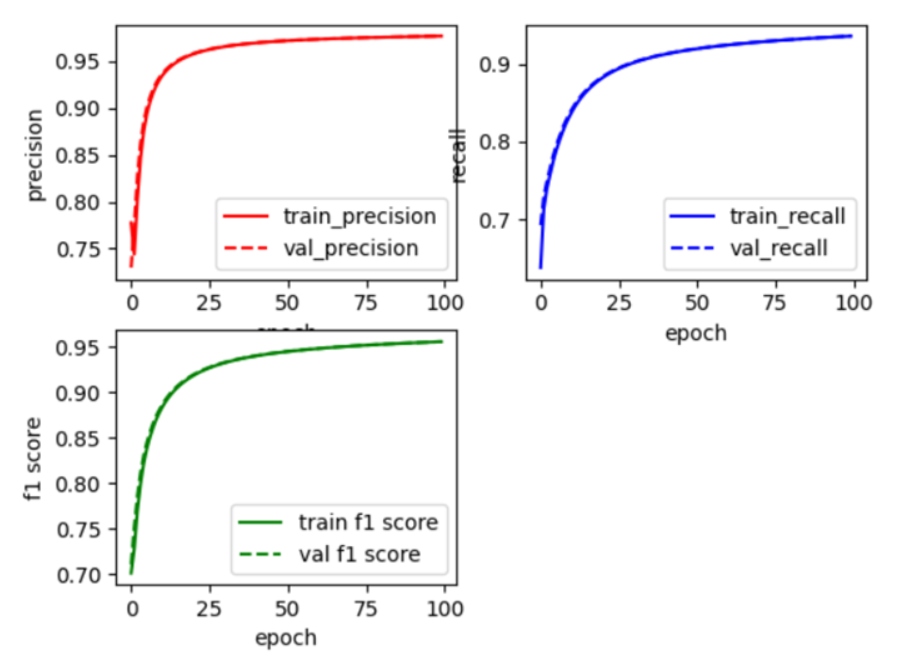
<validation data와 train data의 epoch 값에 따른 f1 score 변화>