A standalone, pip-installable Postgres-as-queue workflow engine, extracted from the ai_leads stack so the ~35 sibling projects can share one DRY source.
Local-cluster swift management: swiftly manage a local, self-hosted cluster of a handful of heterogeneous CPU/GPU machines and get the most out of limited resources. Turn a given machine's worker ON/OFF on demand, and load/unload models across different boxes as work shifts, so jobs land on whatever capacity is free instead of being pinned to one host that's busy or down — all on hardware you already own, with no cluster scheduler to run.
Postgres is the only hard dependency. The engine provides:
- a
SELECT … FOR UPDATE SKIP LOCKEDclaim loop woken byLISTEN node_job_ready(claim_worker), with aLeaseRenewer+ per-jobWatchdog; - lease reclaim (a dead/wedged worker's row is re-queued);
- a DAG dispatcher with a durable dispatch-event outbox (
dispatcher+node_pool); - a GPU warm-model cache that keeps one model loaded across same-model jobs
(
model_cache/gpu_model_cache/model_registry); - periodic "ingest" work on a dedicated
ingest_jobstable + a PG-native ticker (scheduler/ingest_executor); - per-host CPU/GPU/RAM telemetry →
pg_notify('hw_metrics', …)(hw_metrics); - an operator worker ON/OFF control plane: a
worker_controlstable + a per-(host, queue)WorkerControlWatcherthat hard-stops (kill in-flight + free RAM/VRAM) or parks a worker on command (worker_control; seedocs/worker_control.md).
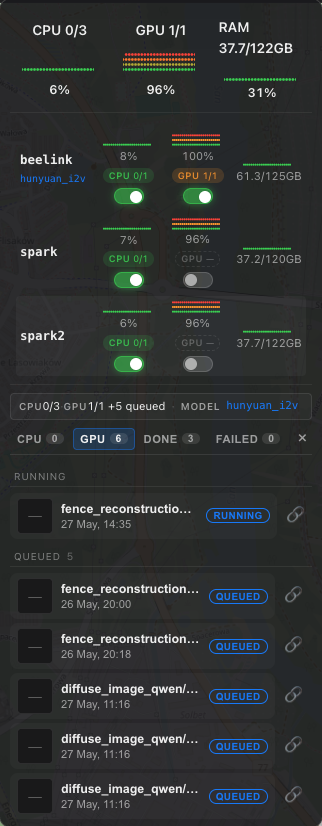
The UI is not part of this package — we ship only the core engine. The screenshot above is an example operator dashboard built on top of what the engine already emits: per-host CPU/GPU/RAM via
pg_notify('hw_metrics', …), live capacity fromworker_heartbeats, queue depth fromnode_queue.*_snapshot(), and the per-(host, queue)ON/OFF toggles backed byworker_controls.Building the front-end is left to you — and it's a great task to hand to your coding agent: point it at the
hw_metricsnotifications, the snapshot helpers, and theworker_controlAPI, and ask it to wire up a dashboard in your stack of choice.
Three independent processes run against one Postgres — the database is the
message bus. INSERTing a row is enqueuing the work; a trigger fires
pg_notify inside the writer's transaction, so there is no "queued but no wake"
window. A live worker renews its lease while a job runs; a dead/wedged worker's
lease lapses and the orchestrator re-queues the row.
flowchart LR
subgraph PROC["Three processes (separate OS processes, GIL-independent)"]
direction TB
O["<b>Orchestrator</b><br/>• bootstraps migrations<br/>• dispatch loop — DAG fan-out<br/>• drains dispatch outbox<br/>• lease-reclaim + dead-worker sweep<br/>• InputListener (resume parked nodes)"]
S["<b>Scheduler</b><br/>PG-native ticker<br/>enqueues ingest_jobs<br/>at scheduled minutes"]
W["<b>Claim worker(s)</b><br/>1 process == 1 worker<br/>LISTEN + FOR UPDATE SKIP LOCKED<br/>LeaseRenewer + Watchdogs<br/>GPU worker owns warm ModelCache"]
end
subgraph PG["Postgres — the message bus (one database)"]
direction TB
T1["workflow_runs"]
T2["workflow_node_jobs<br/>(cpu / gpu — DAG)"]
T3["ingest_jobs<br/>(host-defined queues)"]
T4["workflow_dispatch_events<br/>(durable outbox)"]
T5["worker_heartbeats<br/>worker_controls"]
end
S -- "INSERT + pg_notify(ingest_job_ready)" --> T3
O -- "INSERT + pg_notify(node_job_ready)" --> T2
T2 -. "NOTIFY wakes" .-> W
T3 -. "NOTIFY wakes" .-> W
W -- "claim → run → write (terminal status + dispatch_event) in ONE txn" --> T4
T4 -- "drain → fan out next ready nodes" --> O
O -- "reclaim lapsed leases → re-queue" --> T2
W -- "renew lease · emit heartbeat · obey ON/OFF" --> T5
Two job families share the engine: DAG node-jobs (workflow_node_jobs,
queues cpu/gpu, fanned out by the dispatcher) and standalone ingest jobs
(ingest_jobs, host-defined queues, no DAG). See CLAUDE.md for the full design
rationale.
docs/watchdogs.md— the liveness model: lease renewal, the wall-clock + no-progress watchdogs, and the orchestrator-side dead-worker detector (last-resort recovery from a GPU hardware hang).docs/worker_control.md— the operator ON/OFF control plane (hard-stop vs park a(host, queue)worker).
import queue_workflows
from queue_workflows import model_registry
from queue_workflows.model_registry import ModelSpec
from queue_workflows.scheduler import ScheduleEntry
# 1. configure (all keys optional — defaults keep ai_leads byte-compat)
queue_workflows.configure(
db_url_env="MY_DB_URL", # env var holding the DSN
video_model_ids=frozenset({"wan_i2v"}), # GPU models on the tight render budget
node_module_package="myapp.nodes", # node-module resolver prefix
container_prefix="myapp-", # cgroup attribution
)
# 2. wire the host seams
queue_workflows.set_workflow_provider(load_workflow_fn, pipeline_schema_fn)
queue_workflows.set_builtin_model_registrar(register_my_models)
queue_workflows.register_ingest_task("run_fetch_all", run_fetch_all)
queue_workflows.set_ingest_schedule([ScheduleEntry("fetch", 37, "run_fetch_all", "fetch")])
# 3. apply the engine's migration chain (idempotent), then launch
queue_workflows.db.bootstrap() # queue tables → queue_schema_version
queue_workflows.claim_worker.main(["--queue", "gpu"])Console scripts (for standalone / other-project use):
queue-claim-worker --queue=gpu
queue-scheduler
queue-orchestrator
The engine owns its schema as queue_workflows/migrations/NNNN_*.sql (shipped
as package data). queue_workflows.migrations.dir() returns the directory;
queue_workflows.db.bootstrap() applies the chain against the
queue_schema_version ledger. A host with its own domain tables runs a second
chain via db.bootstrap(migrations_dir=..., version_table=...).
The ingest path is not limited to ai_leads' fetch/load. A second consumer (a
non-DAG app — e.g. a forecast service) can route its own queue names and
carry per-job arguments — migration 0008 moved the queue allow-list from a
DB CHECK to host-side validation (mirroring task_name), added an args column,
and dropped the cpu/gpu-only worker_heartbeats CHECK.
queue_workflows.configure(
db_url_env="MY_DB_URL",
ingest_queues=frozenset({"ingest", "hydro", "hydraulic", "corrdiff"}), # NOT cpu/gpu (reserved for the DAG path)
ingest_default_budget_s=3600, # watchdog budget for these queues
)
queue_workflows.register_ingest_task("run_scenario", run_scenario) # fn(reason) OR fn(reason, args) -> dict
# parametrised + atomic with the host's own row (NOTIFY rides the caller's txn):
with my_pool.connection() as conn:
my_create_scenario(conn, scenario_id)
node_queue.enqueue_ingest_job(
task_name="run_scenario", queue="hydraulic",
args={"scenario_id": scenario_id}, conn=conn,
)
# hour-restricted cadence (no longer fires 24×/day):
ScheduleEntry("glofas", minute=30, task_name="run_glofas", queue="ingest", hours=frozenset({6}))
# queue-indicator data for the non-cpu/gpu queues:
node_queue.ingest_snapshot() # {"queues": {q: {queued, running, completed, failed, workers}}}A registered callable may be fn(reason) (args ignored, back-compat) or
fn(reason, args). Ingest workers now emit worker_heartbeats, so
ingest_snapshot()[...]["workers"] reflects live workers per queue. cpu/gpu
stay reserved for the DAG node path; ingest queues require migration version 8.
Each machine runs one worker per queue under a host_label (e.g. a box may
run both a cpu and a gpu worker). An operator can turn any one of them ON or
OFF independently — turning OFF is a hard stop: it requeues the in-flight
job (resume-style, redistributed to a healthy peer), frees RAM/VRAM, and the
worker comes back parked (idle, not claiming) until turned back ON. State is
just a row in worker_controls; a trigger wakes the worker immediately, so any
process sharing the DB can flip it.
# CLI (console script) — defaults host to the local hostname:
queue-worker-control --queue gpu --off # hard-stop this box's gpu worker
queue-worker-control --queue gpu --on --host spark # turn it back onfrom queue_workflows import worker_control
worker_control.disable_worker("spark", "gpu") # hard stop + stay off
worker_control.enable_worker("spark", "gpu") # resume in place (no restart)
worker_control.desired_state_for("spark", "gpu") # 'on' | 'off' (absent ⇒ 'on')-- or a plain SQL write from any consumer sharing the DB (the trigger wakes the worker):
INSERT INTO worker_controls (host_label, queue, desired_state, stop_policy, requested_by)
VALUES ('spark', 'gpu', 'off', 'hard', 'ops')
ON CONFLICT (host_label, queue) DO UPDATE
SET desired_state = EXCLUDED.desired_state, updated_at = now();Turning a worker off redistributes its work rather than failing it, and a
worker absent from worker_controls is treated as ON. See
docs/worker_control.md for the full design (the
os._exit(79) hard-stop contract and the extensible stop-policy seam).
pip install -e '.[test]'
QUEUE_WORKFLOWS_TEST_DB_URL=postgresql://user:pw@host:port/queue_workflows_test \
python -m pytest
The suite forces a *_test DB and applies the engine migration chain only. See
tests/conftest.py.