
AgentJet (AJet) is a cutting-edge, user-friendly agent RL training framework designed to optimize agents and agentic workflows (supporting any agent built with OpenAI SDK, AgentScope, Langchain, or raw HTTP requests), fine-tuning LLM weights to enhance model performance.
AgentJet (AJet) has fully-distributed swarm training capability, which means that you can deploy ajet-swarm start in GPU server(s) and then start training agents in your laptop(s)! Simply provide your agent workflow, training dataset, and reward function, and AgentJet will be ready to go!
Let's begin with the simplest example: a math agent with a tool call. This is a simple & centralized training example.
- please check out the installation guide to set up the training environment.
- tune your first model using the minimum example.
ajet --conf ./tutorial/example_math_agent/math_agent.yaml --backbone='verl'
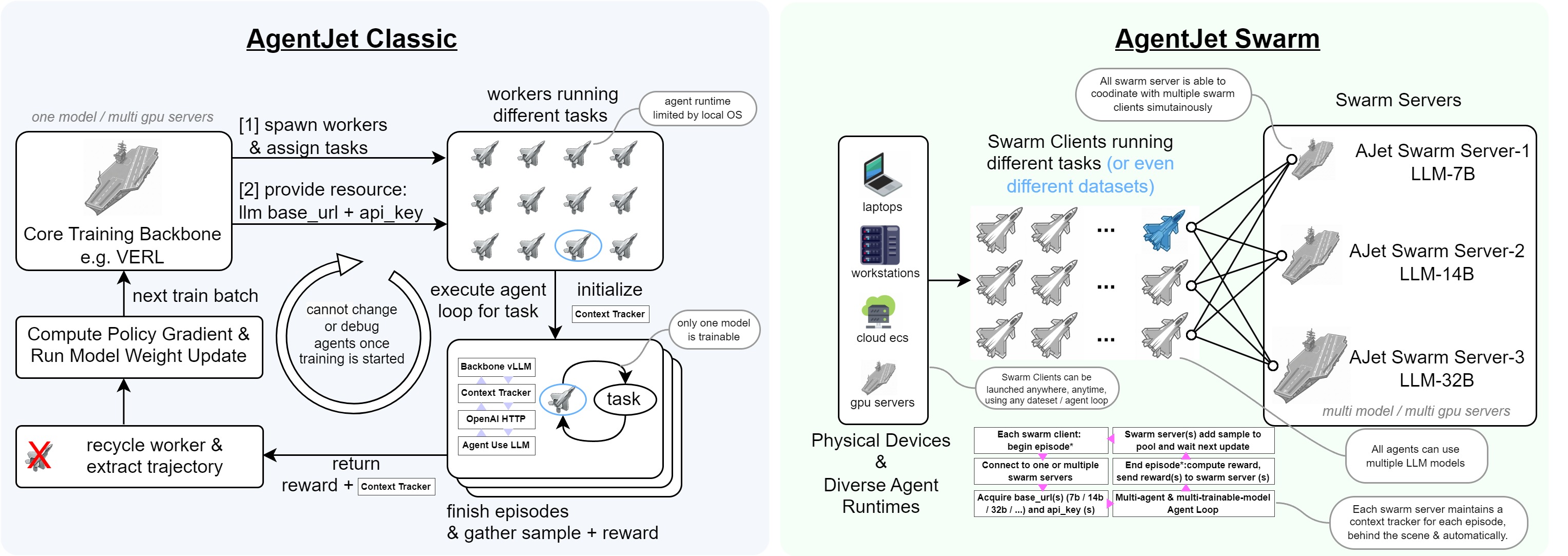
Let's begin with the simplest AgentJet Swarm example: also a math agent. In this case, you can use any GPU-less laptop to train the model remotely.
- Start swarm server and begin swarm overwatch:
ajet-swarm startandajet-swarm overwatch. - From your laptop (or swarm server localhost), run this simple script to begin training:
AJET_SWARM_URL="http://swarm-server-ip:10086" python ./tutorial/example_math_swarm/math.py

We aim to build a easy-to-learn Agent tuner that unlock more possibilities for agent developers:
- Easy and Friendly. AgentJet helps you tune models behind your agent workflows easily, optimizing your agents for top performance with minimal effort.
- Rich Tutorial Library. AgentJet provides a rich library of examples as tutorials.
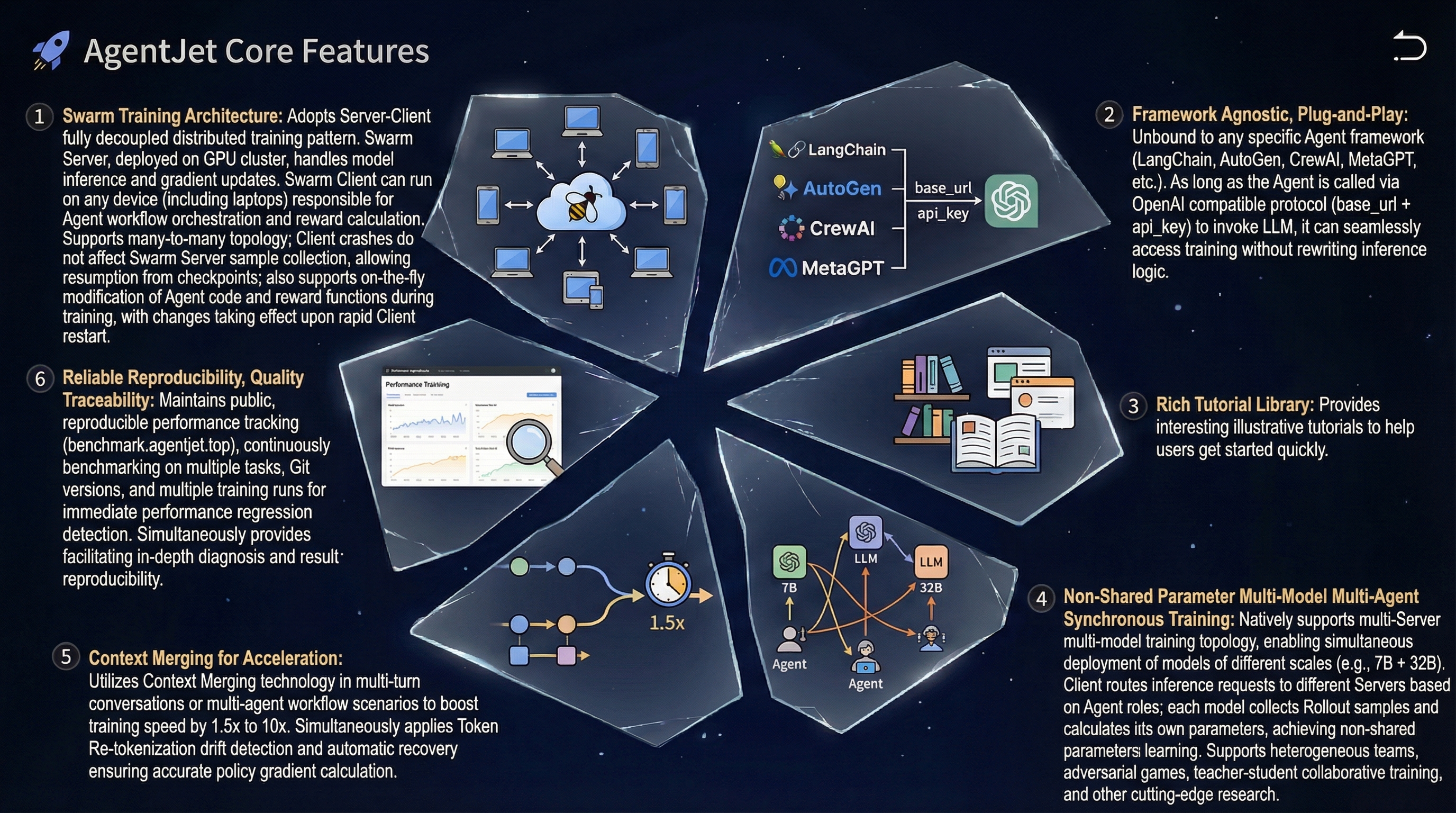
- Swarm Training. This unique feature of AgentJet opens many possibilities: deploying distributed & self-healing rollout workers, non-shared-parameter multi-agent training, multi-runtime & multi-task cocktail training. And just like Tinker, you can use AgentJet Swarm to train **models even on GPU-less laptop(s).
- Efficient and Scalable. AgentJet uses [verl] as the default backbone (
--backbone=verl). However, we also support trinity as alternative backbone, accelerating your tuning process via fully asynchronous RFT. - Flexible and Fast. AgentJet supports multi-agent workflows and adopts a context merging technique, accelerating training by 1.5x to 10x when the workflow involves multi-turn (or multi-agent) conversations.
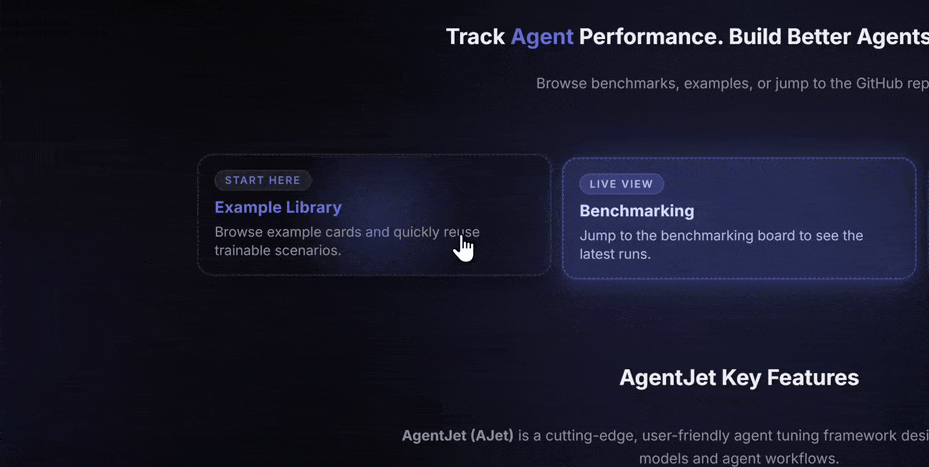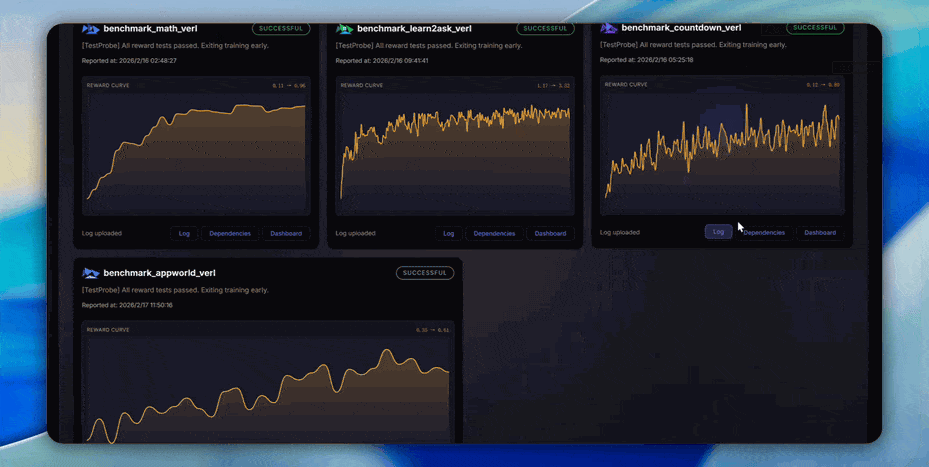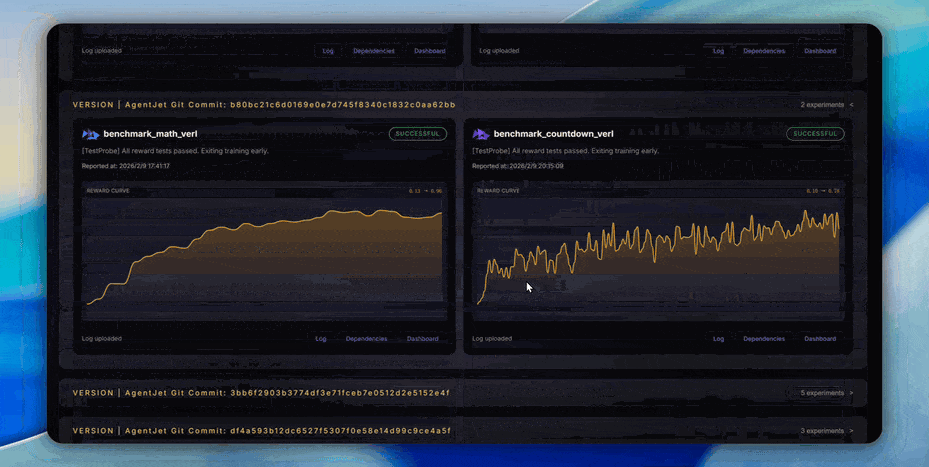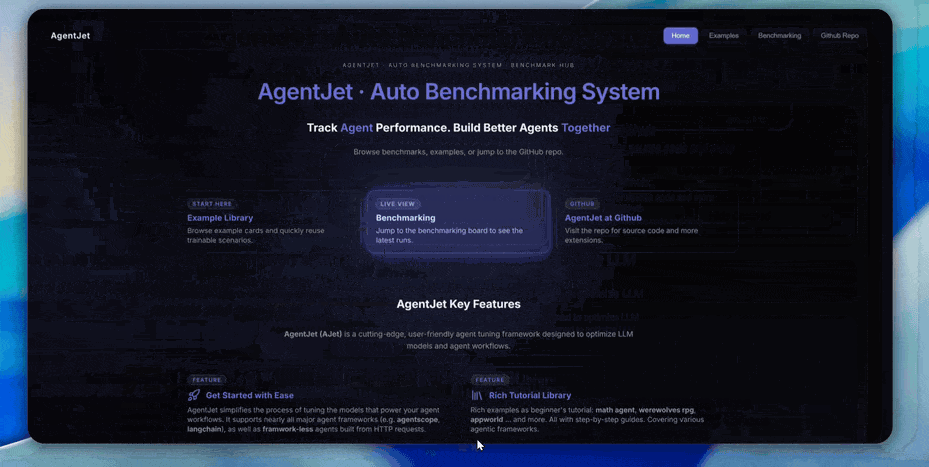
- Reliability and Reproducibility. Our team keeps track of framework performance across multiple tasks + major-git-version + training-backbones (under construction, still gathering data, coming soon).
For advanced researchers, AgentJet also provides high-resolution logging and debugging solutions:
- High-Resolution Logging: AgentJet allows users to save and inspect token-level rollout details, recording token IDs, token loss masks, and even token logprobs to facilitate workflow development and agent diagnostics.
- Fast Debugging: AgentJet also provides the
--backbone=debugoption for the best debugging experience, shortening your wait period from minutes to seconds after code changes and enabling breakpoint debugging in IDEs.
- Click here to read the installation guide.
Explore our rich library of examples to kickstart your journey:
- 🔢 Training a math agent that can write python code.
- 📱 Creating an AppWorld agent using AgentScope and training it.
- 🐺 Developing Werewolves RPG agents and training them.
- 👩🏻⚕️ Learning to ask questions like a doctor.
- 🎴 Writing a countdown game using AgentScope and solving it.
- 🚶 Solving a frozen lake walking puzzle using AgentJet.
Explore our automated benchmarking system https://benchmark.agentjet.top/:
AgentJet makes agent fine-tuning straightforward by separating the developer interface from the internal execution logic.
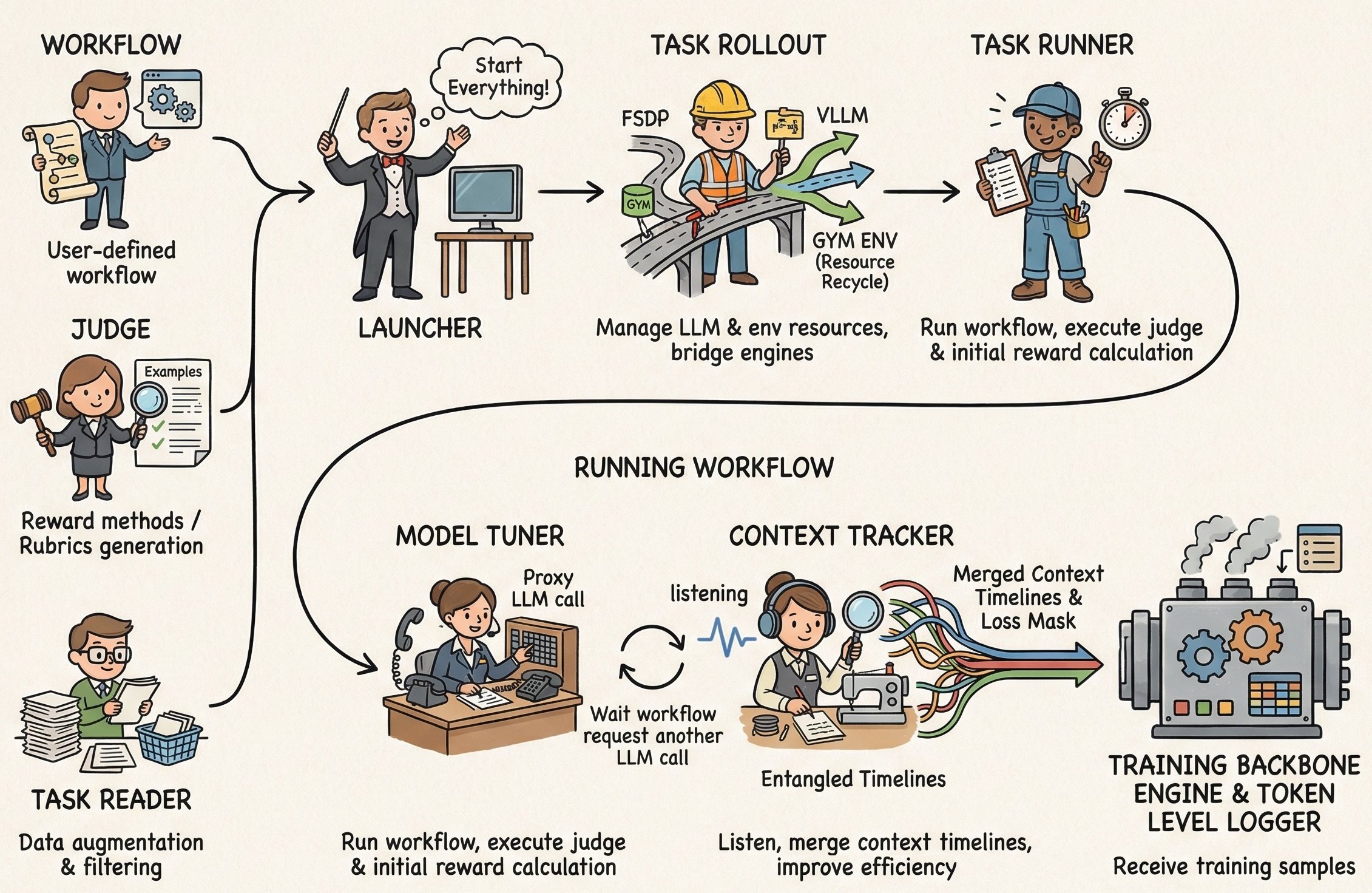
To optimize an agent, you provide three core inputs:
- Trainable Workflow: Define your agent logic by inheriting the Workflow class, supporting both simple agent setups and advanced multi-agent collaborations.
- Task Reader: Load training tasks from JSONL files, HuggingFace datasets, interactive environments, or auto-generate them from documents.
- Task Judger: Evaluates agent outputs and assigns rewards to guide training.
The internal system orchestrates several specialized modules to handle the complexities of RL training and agent interactions.
- Launcher: Manages background service processes (Ray, vLLM) and routes the backbone.
- Task Reader: Handles data ingestion, augmentation, and filtering.
- Task Rollout: Bridges LLM engines and manages the Gym environment lifecycle.
- Task Runner: Executes the Agent workflow and calculates rewards.
- Model Tuner: Forwards inference requests from the workflow to the LLM engine.
- Context Tracker: Monitors LLM calls and automatically merges shared-history timelines to improve training efficiency by 1.5x to 10x.
- Swarm Server: A data interchange center that accept OpenAI-like requests and engine instructions, activated only in AgentJet Swarm mode.
- Tutorials: From Installation to Tuning your first agent — the essential path for beginners.
- Core Components: Define your Trainable Workflow and manage Data and Reward.
- Example: Check the Example Library above for real-world cases like Math, Werewolves game and Learning to ask task.
- Deep Dive: Master advanced Configuration.
AgentJet is a constantly evolving project. We are planning to add the following features in the near future.
| Category | Feature | Status |
|---|---|---|
| Examples | Add LoRA training examples | Todo |
| Infra | Optimize configurations for long-context adaptation on smaller GPUs | In Progress |
| Capability | Multi-modal training support | Todo |
| Capability | MARL Credit assignment | Todo |
| Capability | Training dataset generation from few-shot samples | Todo |
If you use AgentJet in your research, please cite:
@software{
title = {AgentJet: A Cutting-Edge Multi-Agent Training Platform for Large Language Models.},
author = {The AgentJet Team},
url = {https://modelscope.github.io/AgentJet/},
month = {01},
year = {2026}
}
Join AgentJet DingTalk Group to share your idea