- With recent advances in computer science, there is an increasing need to convert human motion to digital data to research human body. Skeleton motion data comprise human poses represented via joint angles or joint positions for each frame of captured motion. Three-dimensional (3D) skeleton motion data are widely used in various applications, such as virtual reality, robotics, and action recognition. However, they are often noisy and incomplete because of calibration error, sensor noise, poor sensor resolution, and occlusion due to clothing on body parts. Data-driven models have been proposed to denoise and fill incomplete 3D skeleton motion data. However, they ignore the kinematic dependencies between joints and bones, which can act as noise in determining a marker position. Inspired by a directed graph neural network, we propose a novel model to fill and denoise the markers. This model can directly extract spatial information by creating bone data from joint data and temporal information from the long short-term memory layer. In addition, the proposed model can learn the connectivity between joints via an adaptive graph. As a result, the proposed model showed good refinement performance for unseen data with a different type of noise level and missing data in the learning process.
- Three-dimensional (3D) skeleton motion data are widely used in several applications, such as human-computer interactions, virtual reality, robotics, movie production, and action recognition. The 3D skeleton data captured by motion capture devices are often noisy and incomplete because of calibration error, sensor noise, poor sensor resolution, and occlusion due to clothing on body parts. For effective data usage, data refinement should be performed beforehand. The purpose of this model is to generate clean data from corrupted data with occlusion or noise.
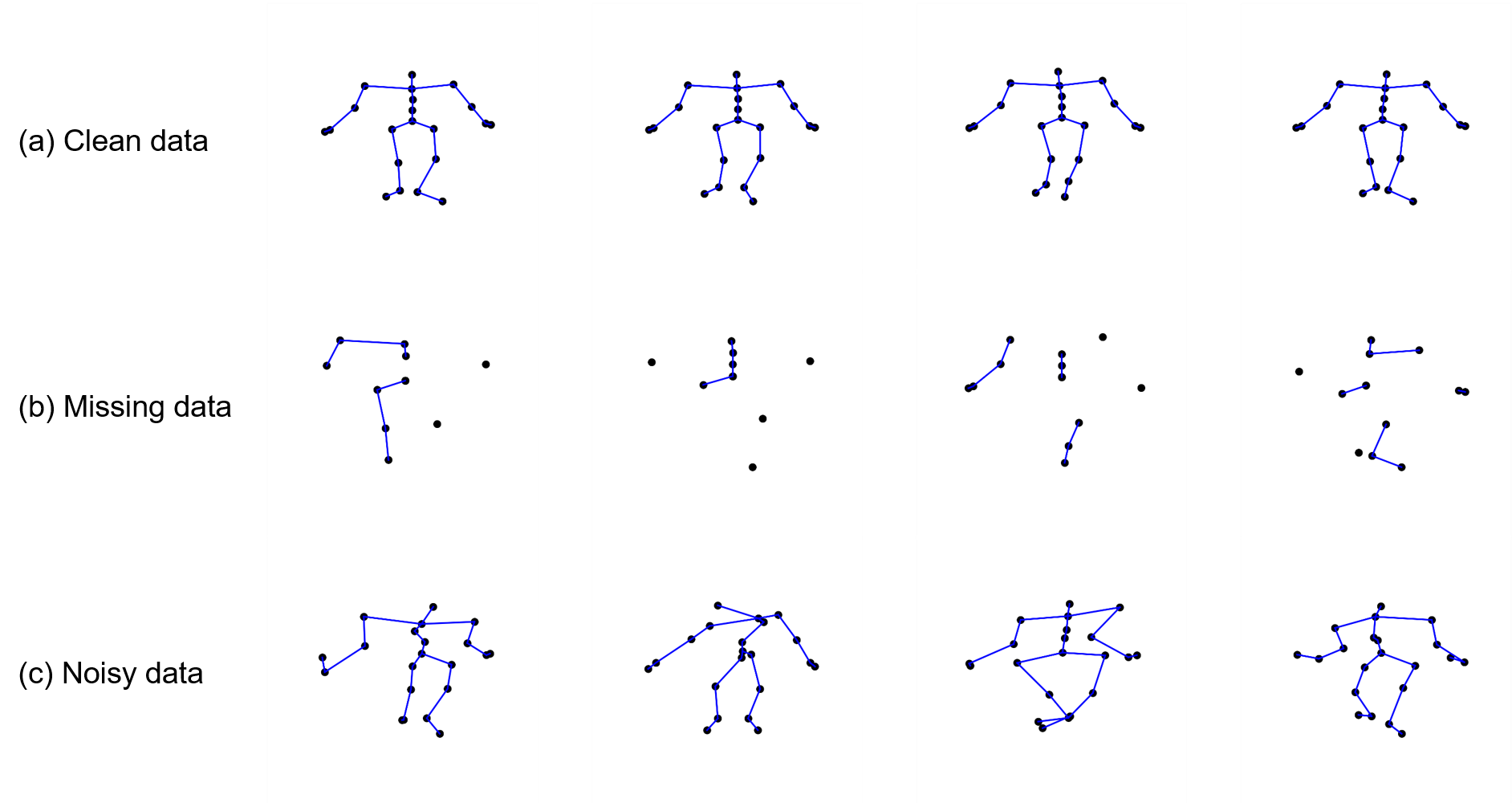
- Inspired by a directed neural network, we propose a novel model that fills and denoises skeleton motion data using the information on relevant joints by representing the skeleton data as a directed acyclic graph. This model can directly exploit spatial information by creating bone data from joint data and temporal information from the long short-term memory layer. In addition, the proposed model can learn the connectivity between joints via an adaptive graphs. As a result, the proposed model showed good refinement performance for unseen data with a different type of noise level and missing data in the learning process.
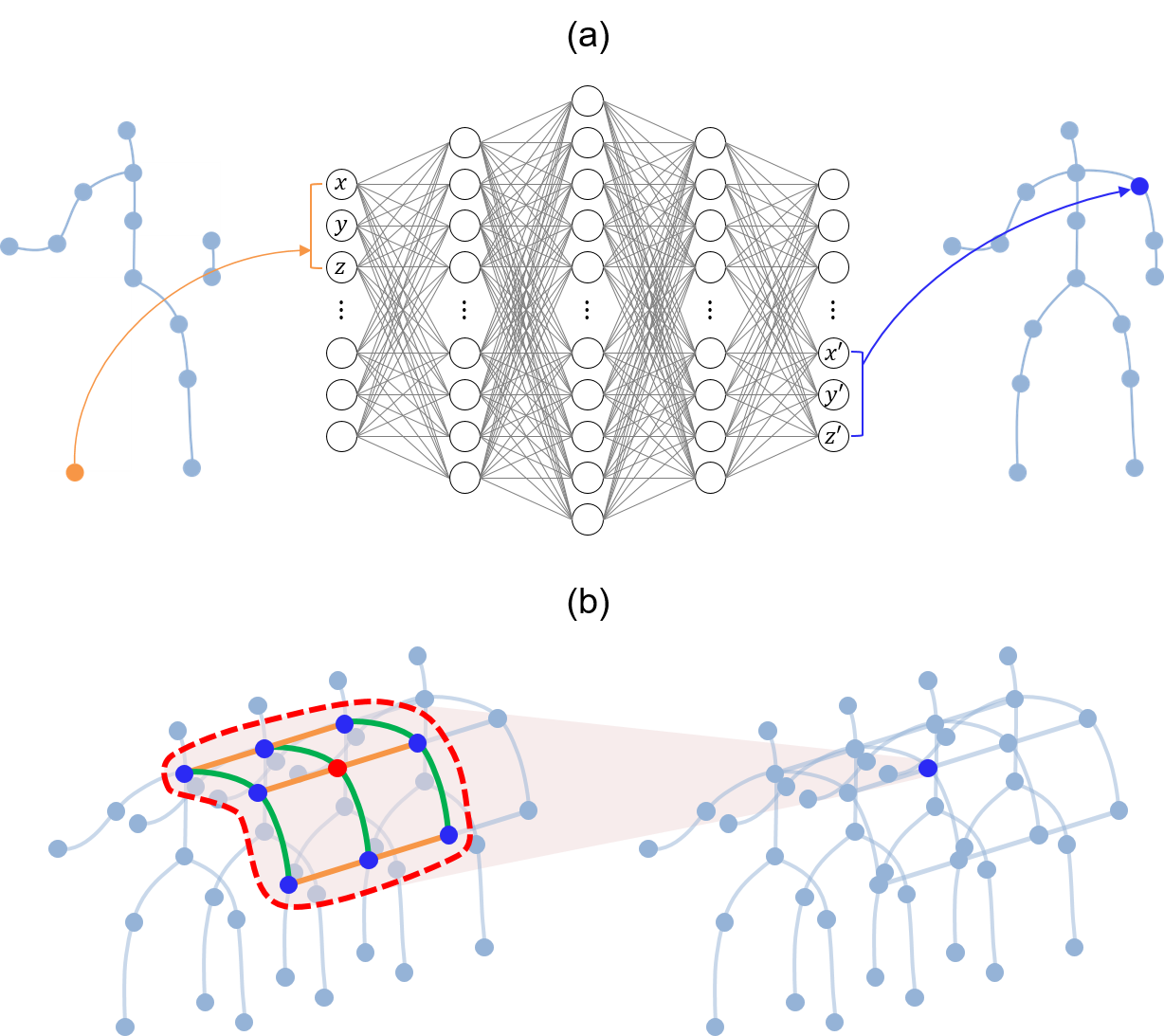
- We are writing a paper on the content of the proposed model in this paper.
- The major contributions of this study are as follows.
- To the best of our knowledge, this is the first time a directed acyclic GNN is applied to motion data refinement considering both spatial and temporal information. In addition, we demonstrate that it is highly effective in representing human motion data, even for refinement.
- The proposed model is robust because it uses neighboring joints to predict missing joints, whereas other networks can be affected by irrelevant joints with severe noise or frequently missing joints.
- The proposed model applies not only to various types of unseen data but also to input that has not been processed (e.g., rotation). Meanwhile, the previous models proceeded with data preprocessing for translation and rotation. These processes require the assumption that a particular joint must be measured, making it difficult to generalize many cases and time-consuming to preprocess. Because the proposed model considers the joint kinematic structure, it works well just by proceeding with data translation alone and can be generalized to various data.
- On the CMU mocap dataset, the proposed model exceeded the state-of-the-art performance for 3D skeleton motion data refinement using three types of losses.
- Python == 3.7.8
- numpy == 1.19.5
- Pytorch == 1.4.0
config/: Configuration of input variables for main.py.data/CMU/asfamc_21joints/: Put the data files, train_full_joint.pkl and train_missing_joint.pkl, in this path.model/bra_dgn.py: Proposed model.
- We use the CMU Motion Capture Database. With 31 markers attached to actors, the motion data were captured with an optical motion capture system. These data were converted from the joint angle representation in the original dataset to the 3D joint position, subsampled to 60 frames per second, and separated into overlapping windows of 64 frames (overlapped by 32 frames). Only 21 of the most relevant joints were preserved. The proposed model applies to not only data from 64 frames but also data from other various frames.
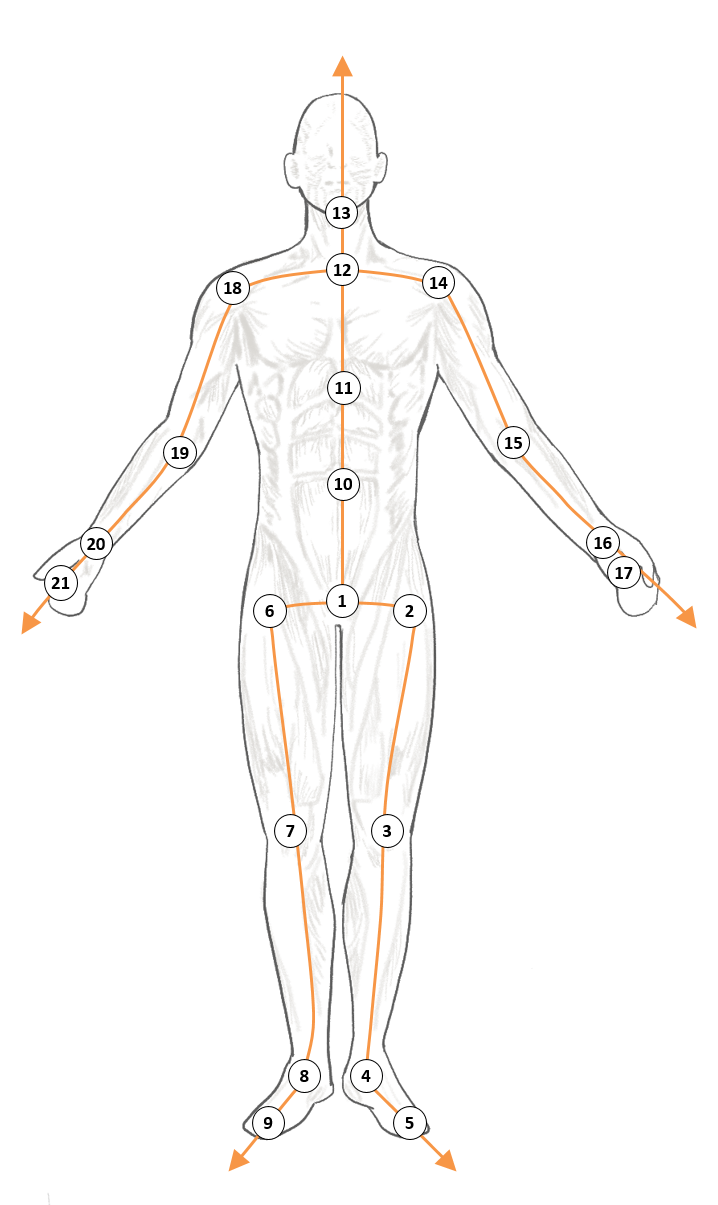
- Notably, the location and direction of skeleton motion data in the human motion data can change with the time they are captured. Similar to previous studies, not only the global translation is removed by subtracting the root joint position from the original data but also the global rotation around the Y-axis is removed. Finally, we subtracted the mean pose from the original data and divided the absolute maximum value in each coordinate direction to normalize the data into [−1, 1]. This preprocessing process helps a particular joint to exist in stochastically similar locations, making it easier for the model to predict.
- The model is trained in a total of three stages via changing the coefficients.
python3 main.py --config './config/asfamc_21joints/bra_dgn/train_bra_dgn_first.yaml' --base-lr 0.001 --device 0
python3 main.py --config './config/asfamc_21joints/bra_dgn/train_bra_dgn_second.yaml' --base-lr 0.0001 --device 0
python3 main.py --config './config/asfamc_21joints/bra_dgn/train_bra_dgn_third.yaml' --base-lr 0.0001 --device 0
python3 main.py --config './config/asfamc_21joints/bra_dgn/test_bra_dgn.yaml'
- Shi, L., Zhang, Y., Cheng, J., & Lu, H. (2019). Skeleton-based action recognition with directed graph neural networks. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (pp. 7912-7921).
- Li, S., Zhou, Y., Zhu, H., Xie, W., Zhao, Y., & Liu, X. (2019). Bidirectional recurrent autoencoder for 3D skeleton motion data refinement. Computers & Graphics, 81, 92-103.