{kind=link}
{kind=link}
This repository presents a structured Data Science Foundations project, covering the complete data lifecycle:
From database initialization and SQL data modeling
to exploratory data analysis, feature engineering, and classical machine learning.
The project is intentionally organized by real-world data roles, reflecting how modern data systems are built in professional environments.
Rather than approaching exercises as isolated tasks, this repository models the natural progression of a data product:
- Data infrastructure
- Data warehousing
- Analytical exploration
- Feature preparation
- Model training & evaluation
Each stage builds on the previous one.
.
├── 00_data_engineer
├── 01_data_warehouse
├── 02_data_analyst
├── 03_data_scientist_01
├── 04_data_scientist_02
├── db_init
├── src
├── scripts
├── etl
├── Dockerfile
├── docker-compose.yml
├── Makefile
└── requirements.txt
Each directory represents a stage in the professional data workflow.
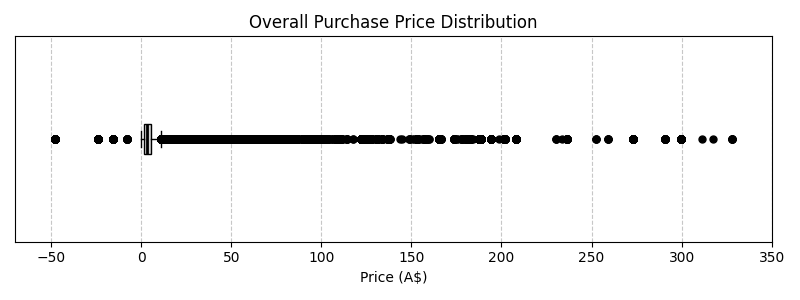
This boxplot highlights the distribution of purchase prices, revealing:
- A strong right-skewed distribution
- Significant high-value outliers
- Concentration of values within a lower price range
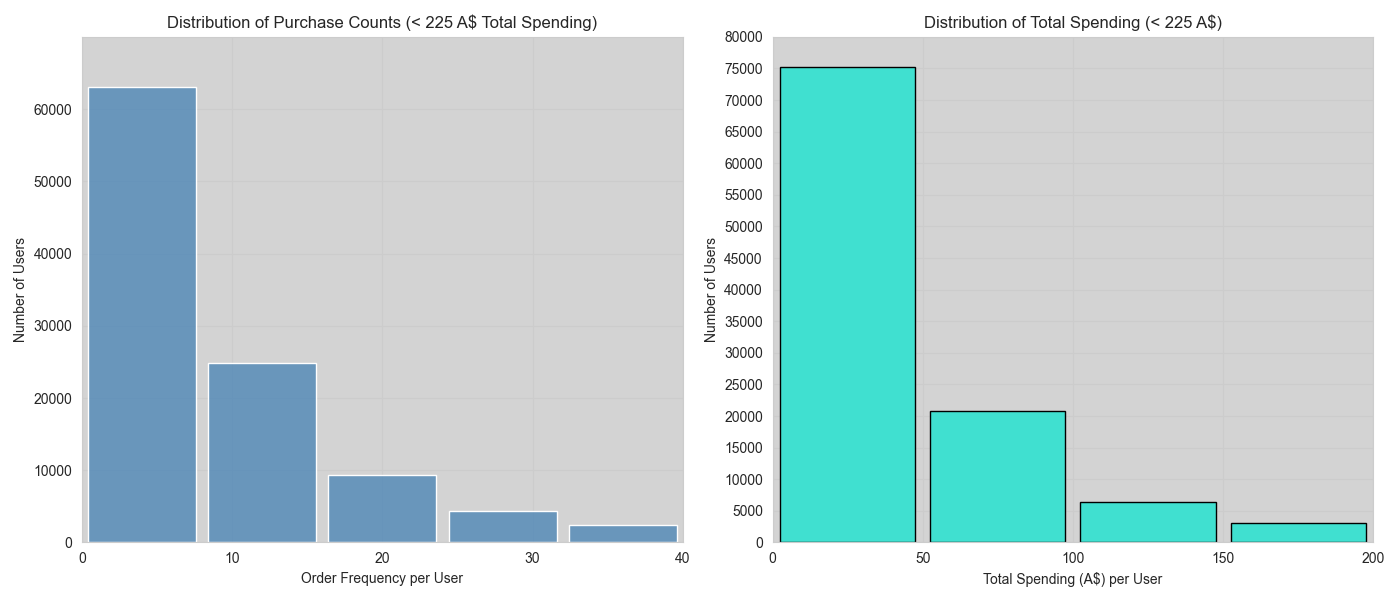
These histograms focus on users whose total spending is below 225 A$, allowing clearer observation of general purchasing behavior.
- Left: purchase frequency per user
- Right: total spending per user
Key observations:
- Most users make few purchases
- Spending is concentrated in lower ranges
- Clear long-tail behavior typical of transactional systems
- Clear separation of concerns
- Reproducibility over static artifacts
- Role-based modular structure
python3 -m venv venv
source venv/bin/activate
pip install -r requirements.txtdocker compose up --buildThis repository reflects a learning and consolidation process.
While functional and structured for clarity, minor edge cases may still exist.