UPSTREAM PR #21821: llama : add --hugepages for HugeTLB-backed weight loading (Linux)#1347
UPSTREAM PR #21821: llama : add --hugepages for HugeTLB-backed weight loading (Linux)#1347
Conversation
…ing (Linux) (flag only, not implementation) First commit to add --hugepages option (CLI). This commit only adds the structure for the flag but does not change any other code. (Commit 1/3) Full descriptions included here for convenience... --- Back model weight mappings with anonymous 2 MiB HugeTLB pages on Linux, activated by a new --hugepages CLI flag (env: LLAMA_ARG_HUGEPAGES). Primary benefit is kernel vmemmap reclamation via HugeTLB Vmemmap Optimization (HVO) — not TLB speedup. On a 128 GiB system fully backed with 2 MiB hugepages this frees ~1.75 GiB of struct page memory, turning tight-ceiling workloads from OOM into working. Mechanism: llama_mmap allocates MAP_PRIVATE|MAP_ANONYMOUS|MAP_HUGETLB| MAP_HUGE_2MB|MAP_POPULATE (zero-filled), then load_all_data populates the region per-tensor via file->read_raw before check_tensors and view allocation consume it. mprotect downgrades to PROT_READ after load. MAP_POPULATE is a race-safety guarantee (pool-short → clean ENOMEM at mmap time, not SIGBUS mid-load). Measured on qwen3 19.4 GB / Strix Halo: 1.31x cold / 4.24x warm slowdown vs baseline mmap; vmemmap reclamation confirmed via VmRSS delta (3872 kB hugepages vs 19.30 GB baseline).
This is the second commit to add huge pages support. This commit prepares the data structures and function call signatures but does not change functionality. (commit 2/3)
…ing (Linux) (**implementation**) This is the final commit of 3 to implement hugepages support. This is the implemenmtation; previous commits where preperatory. (The description below is identical to the first commit.) --- Back model weight mappings with anonymous 2 MiB HugeTLB pages on Linux, activated by a new --hugepages CLI flag (env: LLAMA_ARG_HUGEPAGES). Primary benefit is kernel vmemmap reclamation via HugeTLB Vmemmap Optimization (HVO) — not TLB speedup. On a 128 GiB system fully backed with 2 MiB hugepages this frees ~1.75 GiB of struct page memory, turning tight-ceiling workloads from OOM into working. Mechanism: llama_mmap allocates MAP_PRIVATE|MAP_ANONYMOUS|MAP_HUGETLB| MAP_HUGE_2MB|MAP_POPULATE (zero-filled), then load_all_data populates the region per-tensor via file->read_raw before check_tensors and view allocation consume it. mprotect downgrades to PROT_READ after load. MAP_POPULATE is a race-safety guarantee (pool-short → clean ENOMEM at mmap time, not SIGBUS mid-load). Measured on qwen3 19.4 GB / Strix Halo: 1.31x cold / 4.24x warm slowdown vs baseline mmap; vmemmap reclamation confirmed via VmRSS delta (3872 kB hugepages vs 19.30 GB baseline).
|
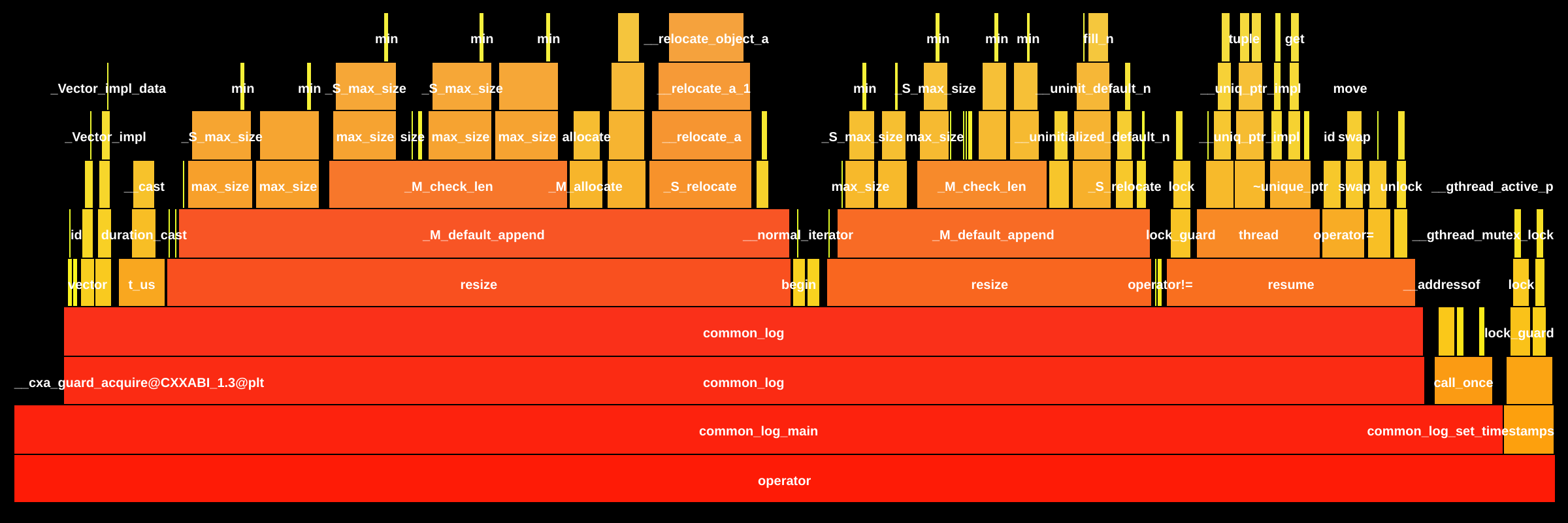
The flame graphs show the transformation from a trivial 10.7ns operation (base) to a 10-level call hierarchy (target) dominated by Additional FindingsInference hot path unaffected: All performance-critical components remain unchanged— 💬 Questions? Tag @loci-dev |
7638ab4 to
f1b46d5
Compare
Note
Source pull request: ggml-org/llama.cpp#21821
Overview
Addresses #2251 (partially — weights via
--mmappath only; I hope to address--no-mmapand KV cache in a follow-up). I realize this is a non-trivial change (even though the implementation itself it just one file / two blocks), so I'm going into a bit more detail than I usually would with a PR. :)Summary
Adds a new
--hugepagesCLI flag (env:LLAMA_ARG_HUGEPAGES) that backs model weight memory with anonymous 2 MiB HugeTLB pages on Linux.Motivation: vmemmap reclamation
(not TLB speedup,v though it may facilitate future work in this area)
When HugeTLB Vmemmap Optimization (HVO,
CONFIG_HUGETLB_PAGE_OPTIMIZE_VMEMMAP=y) is enabled, the kernel frees the per-4 KiBstruct pagemetadata within each hugepage. On a 128 GiB system this recovers ~1.75 GiB of kernel memory — enough to turn a tight-ceiling workload from OOM into working (which is what was happening to me).The flag is opt-in at runtime, so there's no cost to anyone who doesn't use it.
Why?
Each 4 KiB page costs ~64 bytes of
struct pagemetadata. With 128 GiB, that's ~2 GiB just to track pages. HugeTLB with HVO reduces this; a 2 MiB hugepage is only 4 KiB instead of 32 KiB.Here's my real-life example: Strix APU with 128 GiB RAM (unified in my case) running MiniMax m2.5 IQ4_XS. The total footprint ~127,910 MiB against ~127,342 MiB available ("normal" pages). Saving 1,792 MiB pushes available memory to ~129,134 MiB, so now the model fits with ~1 GiB to spare.
Transparent Huge Pages (
MADV_HUGEPAGE) don't help here, as THP remaps existing 4 KiB pages under a 2 MiB entry for TLB efficiency, but thestruct pagearray stays intact (and saves no memory). Only explicit HugeTLB pool allocation with HVO addresses this.I do want to be clear that currently this only works with CPU inference; that's because I haven't tackled hipMalloc. (That would open the door to directly passing memory to the GPU without reallocating.) I also am unsure of how this would work with other unified memory systems.
Approach
In #2251, @slaren suggested adding
MAP_HUGETLBto the existingmmapcall. @qdacsvx noted the kernel rejectsMAP_HUGETLBon regular descriptors (EINVAL). This PR implements what @slaren had in mind:llama_mmapallocates an anonymous region withMAP_PRIVATE | MAP_ANONYMOUS | MAP_HUGETLB | MAP_HUGE_2MB | MAP_POPULATEload_all_datapopulates the region per-tensor viafile->seek+file->read_raw(same pattern as the existing--no-mmapbranch)mprotectdowngrades toPROT_READMAP_POPULATEforces atomic pool allocation at mmap time, so if the pool is insufficient, it yields a cleanENOMEM(with a friendly diagnostic includingsysctlguidance), not a SIGBUS during load.Arg-parse rejects
--hugepagescombined with--no-mmap(wording points at a followup PR),--direct-io(the loader's existing conflict resolver would silently bypass our code), and non-Linux platforms.Anonymous mapping is the only path to HugeTLB-backed weight memory without requiring a hugetlbfs mount, copying the model, and recompiling, a la PR #12521 #12552 (issue #12444), which isn't especially user-friendly. This PR avoids all of that — just
sysctl+--hugepages.PR #7420 also used anonymous mappings inside
llama_mmap, but for direct-I/O bypass rather than hugepage backing. A concern raised there was that anonymous memory can swap under pressure. That doesn't apply here, since HugeTLB pages are inherently pinned by the kernel and cannot be swapped, reclaimed, or migrated regardless of memory pressure orRLIMIT_MEMLOCKsettings. The can be relinquished / reused, though.Tradeoffs
Warm-load time increases because
--mmapnormally shares page-cache pages zero-copy, while--hugepagesmustread_rawfile into the anonymous region.Measured on qwen3-235B-Q4 (19.4 GB), Strix Halo, Linux 6.17:
--mmapbaseline--hugepagesThe warm 4.24x is driven by Strix Halo's
copy_to_userbandwidth (~8.5 GB/s on LPDDR5X). Other platforms may see less. At the 128 GiB target scale,warm-load adds ~11 seconds per session — in exchange for the model actually fitting.
Changes
There are three primary changes (in these three commits):
--hugepages(and LLAMA_ARG_HUGEPAGES)Testing
model loads with
--hugepages, inference produces correct output(39 t/s prompt, 8.2 t/s generation on qwen3 19.4 GB)
--helpshows the flag with env var--hugepages --no-mmap,--hugepages -dio)VmRSSconfirms vmemmap reclamation: 3872 kB under--hugepagesvs 19.30 GB baselineMAP_POPULATEread_rawEINTR/short-read handling inherited from existing codeHVO verification
For users to confirm HVO is active:
Follow-ups (future work / not this PR)
--no-mmappath + KV cache + compute buffers via a newggml_backend_cpu_hugetlb_buffer_type(parallel to the existing HBM pattern). Reusesthe
--hugepagesflag.read_rawfor load parallelismposix_fadvise(POSIX_FADV_DONTNEED)on the source page cache after loadbuffer_from_host_ptris hardcodedfalsefor CUDA/HIP (ggml-cuda.cu:4710). This PR is forward-compatible with a future flip for zero-copy on unified-memory APUs.cc @ggerganov @slaren — per prior comments in #2251, I was hoping you could let me know what your take is on this approach. I know this issue matters for me. I've done my best to simplify / minimize code changes, but I am always happy to reconsider my approach as needed. (I hope it's OK to tag you; sorry if I missed a policy against it.)
Requirements
AI was used to identify the appropriate strategy, draft a harness, and draft initial code snippets. Every line was reviewed, edited as appropriate, and included in commits (with sections of code separated manually into different commits with specific focus to ensure clarity and appropriate review (e.g., CLI parameter setup, data structures / call signatures, and final implementation were all separated into separate commits during review and manual processing.)