In this project I downloaded the dataset of comments of customers of digikala from kaggle.
These coments were either positive, negativie or neutral.
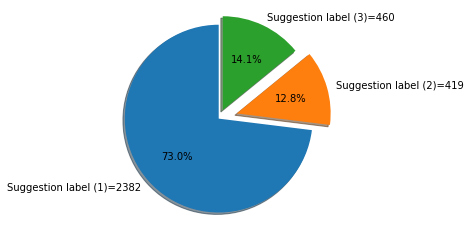
The following pie chart shows the distribution of each group.
I used the Hazm library to clean the texts. The cleaning process includs the normalization , tokenizing, removing stop words and stemming. Then I used the TfIdf vectorization to vectorize the texts.
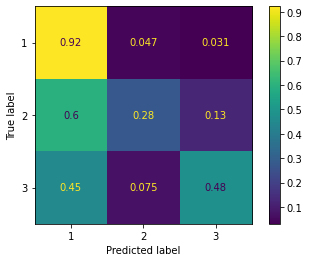
After vectorization I used the Random Forest classifier of sklearn. Here is the confusion matrix
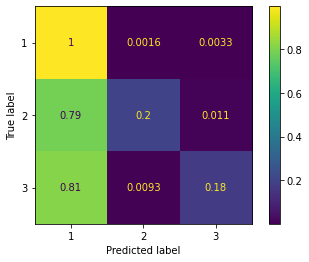
I also used the SGD classifier of sklearn and here is the confusion matrix.