sLSTM is often described as an enhanced version of LSTM with scalar or sequence-level updates, which may include improvements to the gating mechanisms (such as exponential gating) and optimizations of the memory structure. The focus in the paper might be more on enhancing the capabilities of LSTM through algorithmic optimizations rather than employing complex network layers and structures like in code implementations.
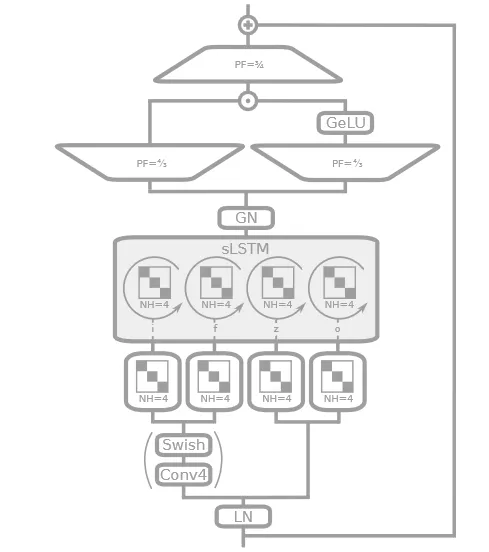
- Layer normalization (LayerNorm) is used in the code to stabilize the input of each layer.
- Causal convolution (CausalConv1D) has been introduced, which ensures the temporal order of information in sequence - data processing and avoids leakage of future information.
- A block diagonal matrix transformation (BlockDiagonal) is used to process data from different heads in parallel.
- Residual connections have been implemented, increasing the stability of the model when processing deep networks.
- The output undergoes non-linear transformation and normalization using GELU and GroupNorm.
mLSTM is described as an LSTM variant with matrix memory, capable of processing and storing more information in parallel. This typically involves a fundamental change in the memory structure, such as using matrices instead of scalars to store the cell states of LSTM.

- Similar to the sLSTMBlock, layer normalization, causal convolution, and residual connections are used.
- A unique projection strategy is employed, such as projecting to a higher-dimensional space followed by processing through activation functions and linear transformations.
- The use of matrix memory is emphasized, which in mLSTM manifests as matrix operations on the inputs and hidden states, as well as the use of BlockDiagonal for block processing.