SRS
This Software Requirment Specification (SRS) describes all specifications for the application "Betterzon". It includes an overview about this project and its vision, detailled information about the planned features and boundary conditions of the development process.
The project is going to be realized as a Web Application. Planned functions include:
- Searching for products, that are also listed on Amazon
- Finding a better price for the searched item
- Finding a nearby store, that has the item in stock
- Registering for the service
| Term | |
|---|---|
| SRS | Software Requirements Specification |
| Title | Date |
|---|---|
| Blog | 19/10/2020 |
| GitHub | 17/10/2020 |
| Jenkins | 19/10/2018 |
| AngularJS | 19/10/2020 |
| Use Case Diagram | 19/10/2020 |
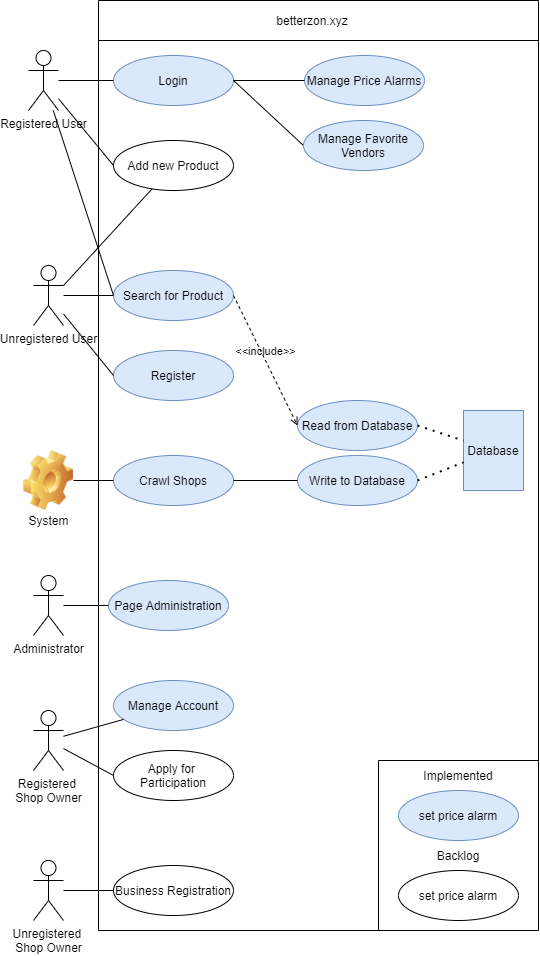
We plan to develop a website that provides you with alternative places to buy other than Amazon. In the beginning, it’s just going to be online stores that may even have better prices than Amazon for some stuff, but we also plan to extend this to your local stores in the future. That way, you can quickly see the prices compared to each other and where the next local store is that offers the same product for the same price or maybe even less.
The website consists of four main components:
- Frontend
- Backend
- Database
- Webcrawler
We aim for the same kind of users that amazon has today. So we need to make sure, that we have a very good usability.
The backend should read data from the database and serve it to the frontend.
The database stores the findings from the webcrawler. Also a history is stored.
The webcrawler crawls a predefined set of websites to extract for a predefined list of products.
The use cases are linked in the wiki.
The User interface should be intuitive and appealing. It should be lightweight and not overloaded with features so anyone is easily able to use our service.
We aim for excellent usability. Every person that is able to use websites like amazon should be able to use our website.
We can of course not guarantee that the prices we crawl are correct or up-to-date, so we can give no warranty regarding this.
99.2016%
The website should be as performant as most modern websites are, so there should not be any waiting times >1s. The web crawler will run every night so performance won't be an issue here. The website will be usable while the crawler is running as it is just adding history points to the database.
Response time should be very low, on par with other modern websites. Max. 50ms
The user traffic should not exceed 100 MBit/s. As we load pictures from a different server, the throughput is split, improving the performance for all users.
The size of the database should not exceed 100GB in the first iteration.
We plan to run the service on 2 vServers, one of which runs the webserver and database and both of them running the web crawler. The crawler will also be implemented in a way that it can easily be run on more servers if needed.
The service will be online as long as the domain belongs to us. We cannot guarantee that it will be online for a long time after the final presentation as this would imply costs for both the domain and the servers.
Standard Angular- and ExpressJS patterns will be followed.
IntelliJ Ultimate GitHub Jenkins
All platforms that can run a recent browser.
The user documentation will be a part of this project documentation and will therefore also be hosted in this wiki.
As we only use open-source tools like mariaDB and Jenkins, the only purchased components will be the domain and the servers.
The project is licensed under the MIT License.
As stated in the license, everyone is free to use the project, given that they include our copyright notice in their product.
We will follow standard code conventions for TypeScript and Python. A more detailed description of naming conventions etc. will be published as a seperate article in this wiki.
N/A