A Content-Based Image Retrieval (CBIR) system implemented in C++ and OOP using OpenCV. The project demonstrates image search using classical visual features (SIFT, SURF, ORB, color histograms), similarity measurement, ranking, and a simple GUI demo.
- Supports multiple feature extractors:
- Color Histogram (HSV)
- Color Correlogram
- Histogram of Oriented Gradients (HOG)
- SIFT
- ORB
- Supports Bag of Visual Words (BoVW) for dimensionality reduction and compact image representation.
- Stores a forward index of image features in binary
.binfiles. - GUI tools for:
- Extracting features from a dataset
- Querying an image and ranking results by similarity
-
Offline Phase (Indexing)
- Extract features from images.
- For SIFT / ORB / HOG → cluster descriptors with K-means → build BoVW histograms.
- Save features and vocabulary into binary
.binfiles.
-
Online Phase (Query)
- User selects a query image.
- Extract features from the query image.
- Compare with the stored index using:
- Chi-square (for color features)
- L2 / Euclidean (for local/BoVW features)
- Sort and return Top-K results.
- Datasets
- CD dataset (99 train, 10 test)
- TMBuD dataset (100 train, 35 test)
- Hardware: Intel i5-9600K, 64GB RAM
- Metrics: Extraction Time, Query Time, mAP (Mean Average Precision)
- SIFT + BoVW (500 visual words) achieved the highest mAP (~0.5) but with slow query times.
- ORB is the fastest and suitable for real-time scenarios, but with lower accuracy.
- HOG is stable but yields lower mAP.
- Color Histogram / Correlogram are fast to compute but less robust to illumination changes.
- Feature extraction UI and query interface that displays Top-K results.
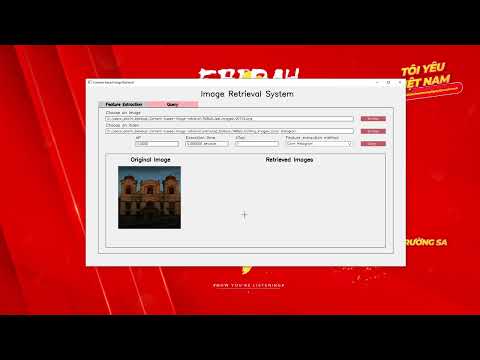
- Visual Studio 2022
- C++17
- OpenCV 4.10.0
├── Content-based image retrieval/ # Source code
├── Release/ # Executable
├── Docs/ # Reports & documentation
├── Demo/ # Video demo (use Git LFS if >100MB)
└── Dataset/ # Datasets & generated feature database
├── CD_images/ # 109 CD images
└── TMBuD/ # STANDARD subset of TMBuD (135 structure images)