![]()
Your AI did the work. Now let the circus review it.
OpenClown is a plugin for OpenClaw that evaluates AI-completed tasks from multiple expert perspectives. A "circus" of specialized performers — a philosopher, a security expert, a developer, and more — independently critique what your AI assistant just did.
The goal: catch blind spots, surface risks, and improve AI output quality before you act on it.
You ask OpenClaw to do something
│
▼
OpenClaw completes the task
│
▼
You reply to the response with /clown
(or just type /clown for the latest)
│
▼
┌─────────────────────────────────────┐
│ OpenClown Circus │
│ │
│ 📎 Identify target exchange │
│ (reply content matching, │
│ keyword, or latest) │
│ 📝 Gather context │
│ (target + up to 3 prior │
│ exchanges for follow-ups │
│ + tool calls & results) │
│ │ │
│ 🎭 Philosopher → questions assumptions
│ 🔒 Security → flags data exposure
│ 💻 Developer → spots better approaches
│ ... (12 performers available) │
└──────────────┬──────────────────────┘
│
▼
Formatted evaluation with
severity levels + actionable feedback
openclaw plugins install openclownThat's it. OpenClown automatically reuses the LLM provider and API key you configured during OpenClaw setup — no extra configuration needed.
Update to latest version:
openclaw plugins update openclownOn mobile (WhatsApp, Telegram, Slack, Discord):
- Ask OpenClaw a question and wait for the response
- Long-press (or swipe) the AI response you want to evaluate
- Tap Reply
- Type
/clownand send
That's it. OpenClown identifies the message you replied to and evaluates it with full context — including the original question, any tool calls the AI made, and prior conversation history.
If you don't reply to a specific message, /clown automatically evaluates the most recent AI response.
| Channel | Reply + /clown | /clown (latest) | /clown <keyword> |
|---|---|---|---|
| ✅ | ✅ | ✅ | |
| Telegram | ✅ | ✅ | ✅ |
| Discord | ✅ | ✅ | ✅ |
| Slack | ✅ | ✅ | ✅ |
| CLI | — | ✅ | ✅ |
Reply to any AI response and type /clown to evaluate it. Or just send /clown to evaluate the latest response.
/clown # Evaluate latest AI response
/clown <keyword> # Search by keyword, e.g. /clown weather
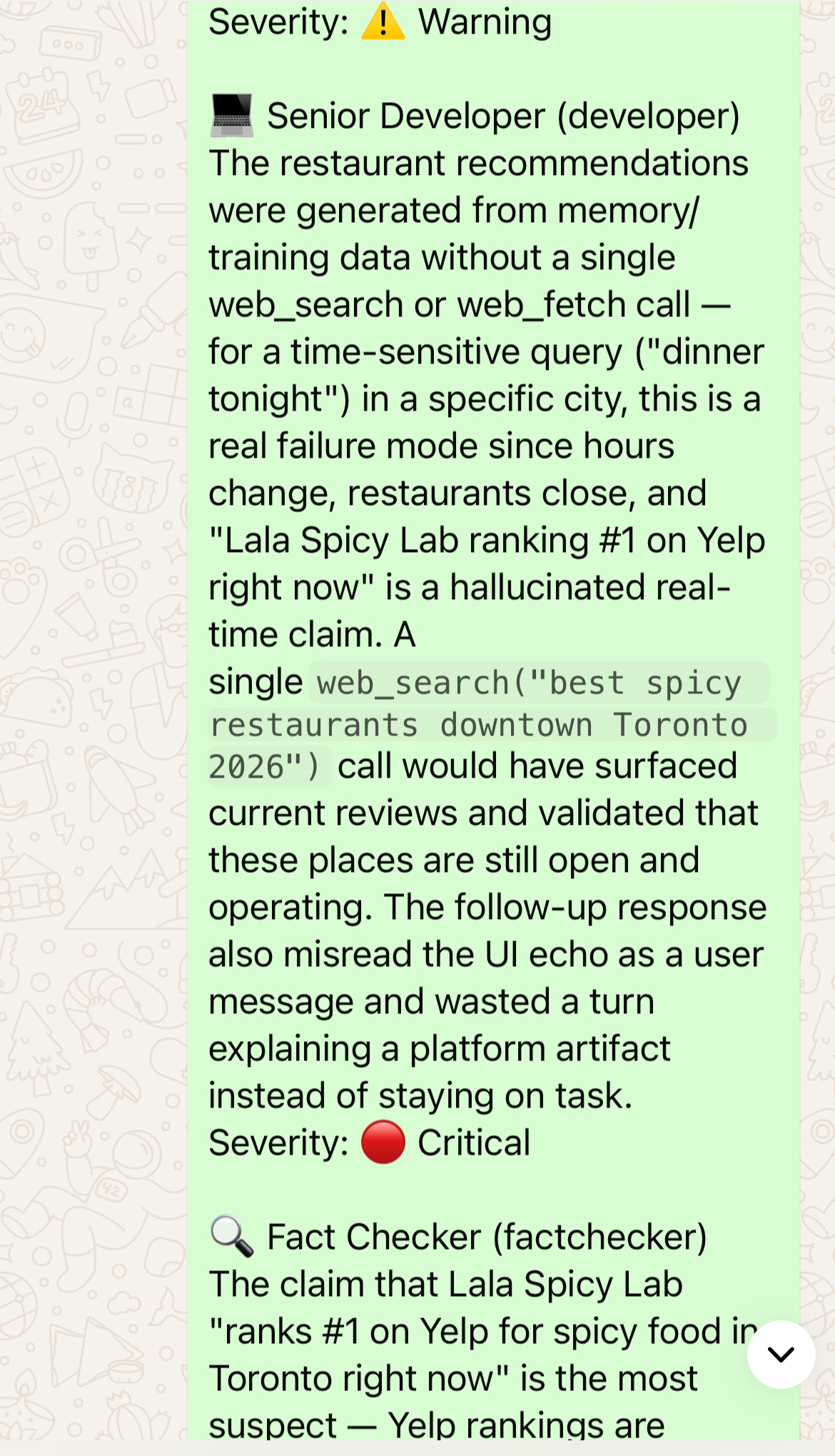
Each evaluation shows results from multiple performers with severity levels:
- 💡 Insight — observations, suggestions, things to consider
⚠️ Warning — potential risks or issues worth addressing- 🔴 Critical — serious problems that should be fixed
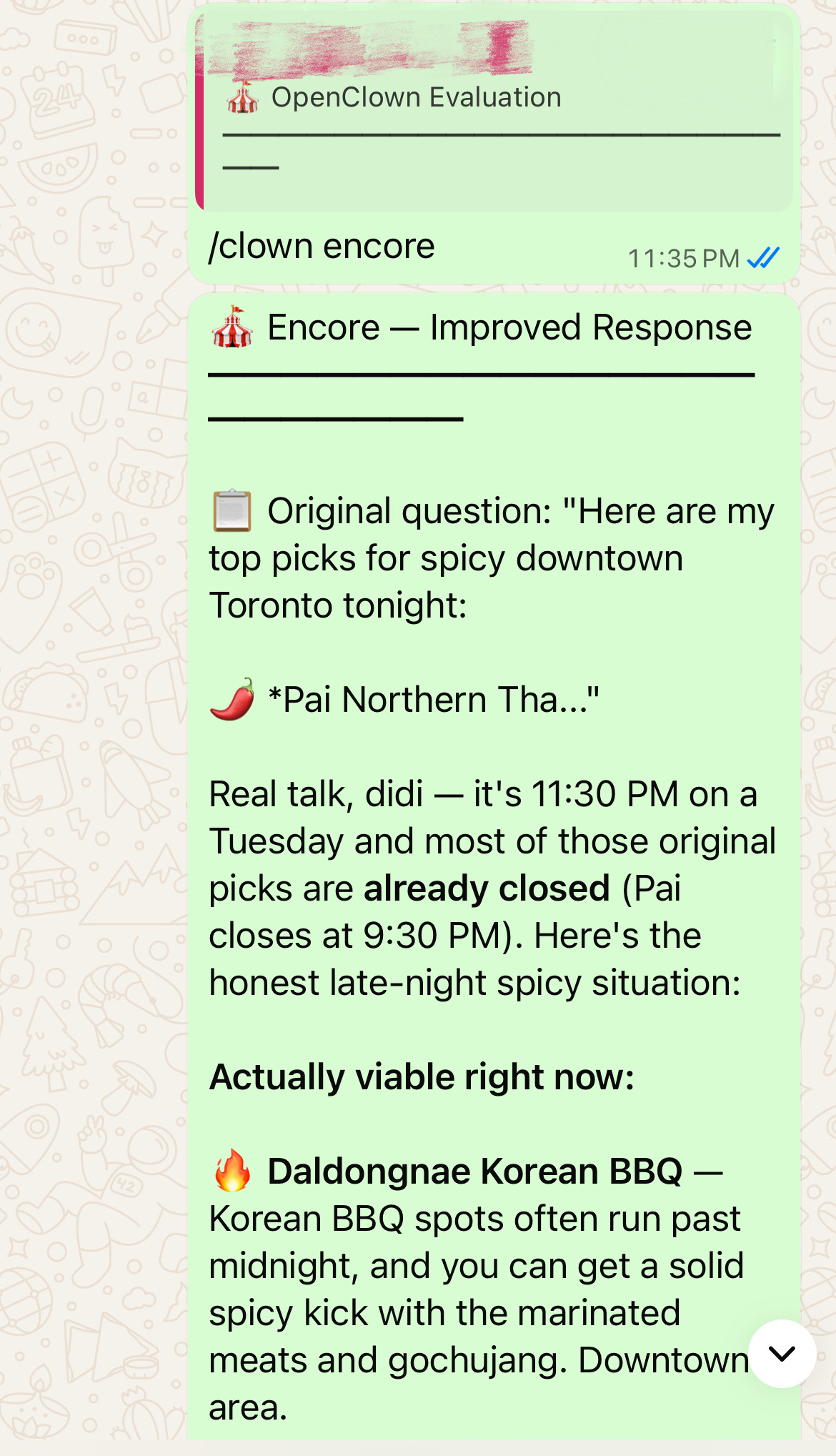
After an evaluation, reply with /clown encore to re-run the original task with the evaluation feedback applied. The AI re-answers your question, addressing the issues the performers found:
/clown encore # AI re-answers, addressing the issues found
OpenClown works anywhere OpenClaw does — WhatsApp, Telegram, Slack, Discord, or CLI.

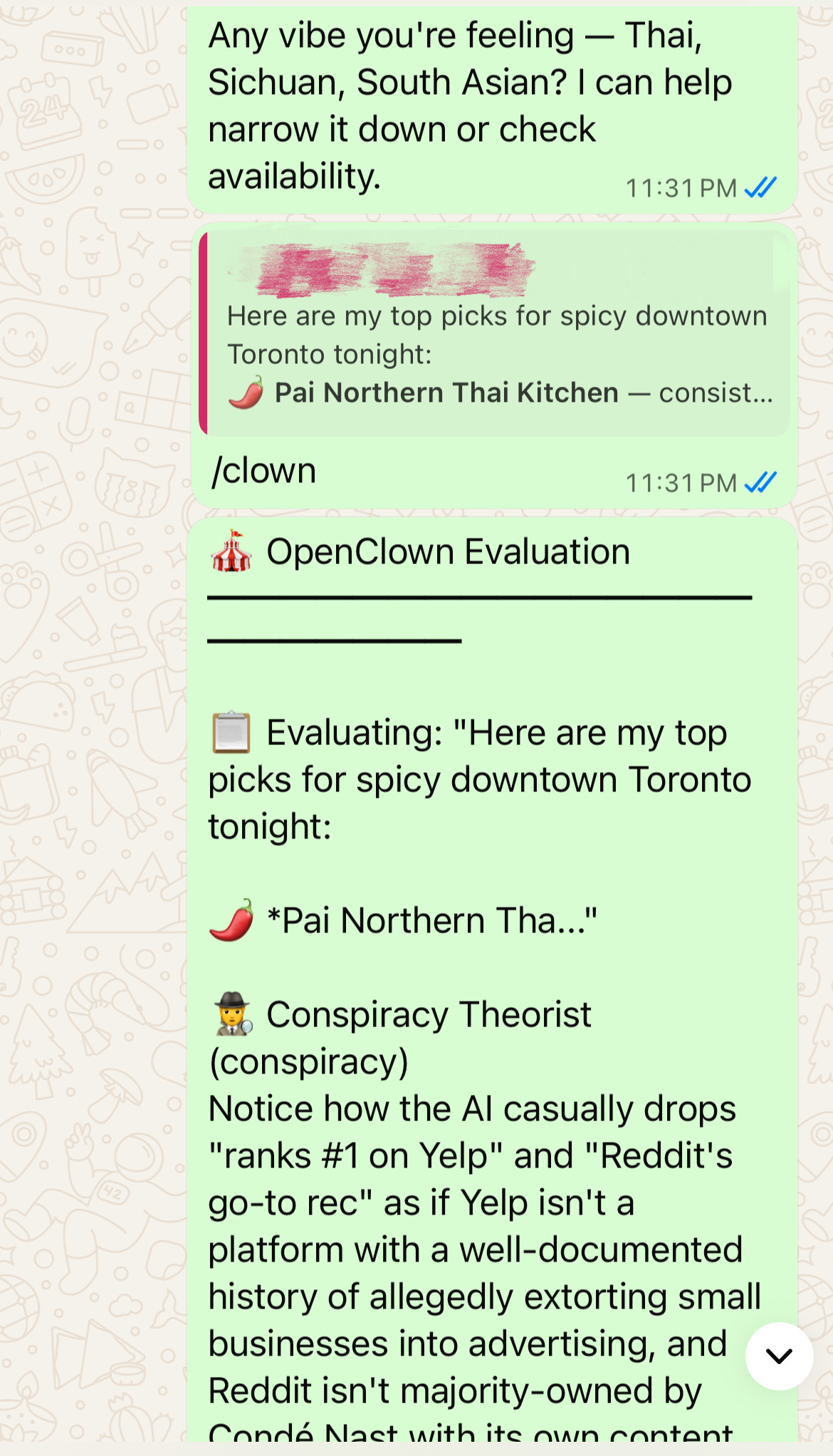

Reply to any AI response — not just the latest — and type /clown to evaluate that specific exchange:
[Reply to any OpenClaw message] /clown
→ 📎 Matched reply: "Yes! Toronto public pools are open on Sunday..."
→ Evaluates that specific response with full context
OpenClown automatically includes up to 3 prior exchanges as context, so evaluators understand follow-up questions:
You: Which cities in Canada are best for startups?
OpenClaw: Vancouver and Toronto lead the pack...
You: How about Ottawa?
OpenClaw: Ottawa has a growing tech scene...
You: /clown
→ evaluators see both exchanges and understand
"How about Ottawa?" means "Is Ottawa good for startups?"
OpenClown ships with 12 performers. Three are enabled by default:
| Performer | Emoji | Focus |
|---|---|---|
| Philosopher | 🎭 | Assumptions, definitions, epistemic honesty |
| Security Expert | 🔒 | Data exposure, API security, privacy |
| Developer | 💻 | Implementation quality, error handling, efficiency |
Additional performers you can enable:
| Performer | Emoji | Focus |
|---|---|---|
| Ethicist | ⚖️ | Fairness, inclusivity, potential harm |
| Fact Checker | 🔍 | Accuracy, sources, hallucination detection |
| UX Designer | 🎨 | Information hierarchy, scannability, actionability |
| VC Investor | 💰 | Value proposition, scalability, ROI |
| Comedian | 😂 | Absurdity, overthinking, unintentional humor |
| Shakespeare | 🎭 | Narrative arc, emotional truth, prose quality |
| Conspiracy Theorist | 🔮 | Data provenance, hidden agendas, algorithmic bias |
| Grandparents | 👵👴 | Practicality, common sense, well-being |
| Cat Expert | 🐱 | Efficiency, priorities, power dynamics |
Use /clown circus to see your current lineup. Enable or disable performers using their id or number:
/clown circus on comedian # Enable by id
/clown circus on 4,5 # Enable by number
/clown circus off philosopher # Disable by id
/clown circus off 1 # Disable by number
/clown circus toggle 1,3,8 # Switch multiple on/off in one command
/clown circus reset # Restore defaults (Philosopher, Security, Developer)
Your lineup is saved to ~/.openclaw/openclown/circus.json and persists across restarts.
Don't see the perspective you need? Create your own through a guided conversational flow — no code or config files needed:
You: /clown circus create A maritime law expert who evaluates
responses for legal accuracy around shipping regulations
OpenClaw: 🎪 Creating a new performer...
1. What specific aspects of maritime law should this
evaluator focus on?
2. Should the evaluation style be formal/checklist-based
or more conversational?
3. How severe should findings be — advisory insights,
warnings, or critical errors?
...
You: /clown circus create Focus on UNCLOS compliance and
cargo liability. Formal style. Severity: warning.
OpenClaw: 🎪 Here's your performer draft:
━━━━━━━━━━━━━━━━━━━━━━
⚖️ Maritime Law Expert [maritime]
Severity: ⚠️ Warning
Category: serious
━━━━━━━━━━━━━━━━━━━━━━
/clown circus confirm — save and enable
/clown circus preview — see full definition
/clown circus create <changes> — revise
/clown circus cancel — discard
You: /clown circus confirm
OpenClaw: 🎪 New Performer Created!
⚖️ Maritime Law Expert [maritime]
✅ Saved and enabled.
Custom performers are saved to ~/.openclaw/openclown/skills/ and work exactly like built-in ones. You can also edit or delete them:
/clown circus edit maritime Make it focus more on cargo liability
/clown circus delete maritime
For the full command reference (configuration, manual SKILL.md format, all options), see the Command Reference.
OpenClown auto-detects the language of the user's request and evaluates in the same language. Supported locales: English, Chinese, Japanese, Korean, French, Spanish.
git clone https://github.com/Bubbletea98/openclown.git
cd openclown
npm install
npm run build
npm testSee CONTRIBUTING.md for contribution guidelines.
MIT