" \
+```
+
+**MinIO Authentication**
+```
+--set minio.auth.rootUser=texera_minio \
+--set minio.auth.rootPassword=password \
+```
+
+**PostgreSQL Authentication (username is always postgres)**
+```
+--set postgresql.auth.postgresPassword=root_password \
+```
+
+> 💡 Note: If you change the PostgreSQL password, you also need to change the following and add it to the install command:
+--set lakefs.secrets.databaseConnectionString="postgres://postgres:root_password@texera-postgresql:5432/texera_lakefs?sslmode=disable" \
+
+**LakeFS Authentication**
+```
+--set lakefs.auth.username=texera-admin \
+--set lakefs.auth.accessKey=AKIAIOSFOLKFSSAMPLES \
+--set lakefs.auth.secretKey=wJalrXUtnFEMI/K7MDENG/bPxRfiCYEXAMPLEKEY \
+--set lakefs.secrets.authEncryptSecretKey=random_string_for_lakefs \
+```
+
+### Allocating Resources
+If your cluster has more available resources, you can allocate additional CPU, memory, and disks to Texera to improve the performance.
+
+**Postgres**
+
+To allocate more CPU, Memory and disk to Postgres, do:
+```
+--set postgresql.primary.resources.requests.cpu=4 \
+--set postgresql.primary.resources.requests.memory=4Gi \
+--set postgresql.primary.persistence.size=50Gi \
+```
+
+**MinIO**
+
+To increase the storage for user's input dataset, do:
+```
+--set minio.persistence.size=100Gi
+```
+
+**Computing Unit**
+
+To customize options for the computing unit, do:
+```bash
+# MAX_NUM_OF_RUNNING_COMPUTING_UNITS_PER_USER
+--set texeraEnvVars[5].value="2" \
+# CPU_OPTION_FOR_COMPUTING_UNIT
+--set texeraEnvVars[6].value="1,2,4" \
+# MEMORY_OPTION_FOR_COMPUTING_UNIT
+--set texeraEnvVars[7].value="2Gi,4Gi,16Gi" \
+# GPU_LIMIT_OPTIONS
+--set texeraEnvVars[8].value="0,1" \ # to allow 0 or 1 GPU resource to be allocated
+```
+
+### Adjusting Number of Pods
+Scale out individual services for high availability or increased performance:
+
+```
+--set webserver.numOfPods=2 \
+--set workflowCompilingService.numOfPods=2 \
+--set pythonLanguageServer.replicaCount=2 \
+```
+
+
+### Retaining User Data
+By default, all user data stored by Texera will be deleted when the cluster deployment is removed. Since user data is valuable, you can preserve all datasets and files even after uninstalling the cluster by setting:
+```
+--set persistence.removeAfterUninstall=false
+```
diff --git a/texera.wiki/Deploying-Texera-on-Google-Cloud-Platform-(GCP).md b/texera.wiki/Deploying-Texera-on-Google-Cloud-Platform-(GCP).md
new file mode 100644
index 00000000000..43c1cd8bb70
--- /dev/null
+++ b/texera.wiki/Deploying-Texera-on-Google-Cloud-Platform-(GCP).md
@@ -0,0 +1,229 @@
+## Prerequisites: Check your quota
+
+Your GCP account should be able to allocate at least 20 vCPUs and 1 TB of SSD. To check your quota, go to the [GCP Quotas](https://console.cloud.google.com/iam-admin/quotas?referrer=search&pageState=(%22allQuotasTable%22:(%22f%22:%22%255B%257B_22k_22_3A_22Name_22_2C_22t_22_3A10_2C_22v_22_3A_22_5C_22CPUs_5C_22_22_2C_22s_22_3Atrue_2C_22i_22_3A_22displayName_22%257D_2C%257B_22k_22_3A_22_22_2C_22t_22_3A10_2C_22v_22_3A_22_5C_22OR_5C_22_22_2C_22o_22_3Atrue_2C_22s_22_3Atrue%257D_2C%257B_22k_22_3A_22Name_22_2C_22t_22_3A10_2C_22v_22_3A_22_5C_22Persistent%2520Disk%2520SSD%2520%2528GB%2529_5C_22_22_2C_22s_22_3Atrue_2C_22i_22_3A_22displayName_22%257D_2C%257B_22k_22_3A_22Dimensions%2520%2528e.g.%2520location%2529_22_2C_22t_22_3A10_2C_22v_22_3A_22_5C_22region_3Aus-central1_5C_22_22_2C_22s_22_3Atrue_2C_22i_22_3A_22displayDimensions_22%257D%255D%22))) page.
+You should be able to see a pre-populated query for listing the CPUs and SSDs in the `us-central1` region by default. If you plan to deploy Texera in another region, you need to change the `Dimensions` part of the query.
+ +If your quota does not have at least 20 CPUs and 1 TB SSD, you need to request a quota increase by clicking the 3-dot button on the right -> "Edit Quota".
+
+If your quota does not have at least 20 CPUs and 1 TB SSD, you need to request a quota increase by clicking the 3-dot button on the right -> "Edit Quota".
+ +
+
+---
+## 1. Create an Autopilot GKE cluster
+
+> 💡 Note: If you already have a GKE cluster and wish to use it for deploying Texera, you can skip this step and proceed directly to Step 2.
+
+Navigate to GCP console -> Kubernetes Engine -> [Clusters](https://console.cloud.google.com/kubernetes/list/overview). Click on the `create` button.
+
+> 💡 Note: You may need to enable the Kubernetes API if you haven't done so.
+
+
+
+
+---
+## 1. Create an Autopilot GKE cluster
+
+> 💡 Note: If you already have a GKE cluster and wish to use it for deploying Texera, you can skip this step and proceed directly to Step 2.
+
+Navigate to GCP console -> Kubernetes Engine -> [Clusters](https://console.cloud.google.com/kubernetes/list/overview). Click on the `create` button.
+
+> 💡 Note: You may need to enable the Kubernetes API if you haven't done so.
+
+ +
+Use all default values to create a cluster. You can also customize the cluster accordingly if needed.
+After 15-20 minutes, you should be able to see the status of your cluster to be in a green checkmark(
+
+Use all default values to create a cluster. You can also customize the cluster accordingly if needed.
+After 15-20 minutes, you should be able to see the status of your cluster to be in a green checkmark( ) state, with 0 vCPUs and 0 memory usage.
+
) state, with 0 vCPUs and 0 memory usage.
+ +Click the three dots on the right, and choose "connect".
+
+Click the three dots on the right, and choose "connect".
+ +
+---
+
+In the pop-up window, copy the **project** and **region** to your clipboard. Then click **"Run in Cloud Shell"**.
+Press Enter for the first command shown on the terminal.
+
+
+---
+
+In the pop-up window, copy the **project** and **region** to your clipboard. Then click **"Run in Cloud Shell"**.
+Press Enter for the first command shown on the terminal.
+ +
+
+## 2. Reserve Two Static IPs (for Texera website and MinIO)
+
+After accessing your cluster using Cloud Shell, define the following variables based on your region and project in Step 1.
+```bash
+REGION=""
+PROJECT=""
+```
+
+Execute the following bash commands to reserve two Public IP addresses.
+
+```bash
+gcloud compute addresses create texera-ip --region=$REGION --project=$PROJECT
+TEXERA_IP=$(gcloud compute addresses describe texera-ip --region=$REGION --format="get(address)" --project $PROJECT)
+gcloud compute addresses create minio-ip --region=$REGION --project=$PROJECT
+MINIO_IP=$(gcloud compute addresses describe minio-ip --region=$REGION --format="get(address)" --project $PROJECT)
+```
+
+Execute the following bash commands to create two nginx controllers with helm.
+```bash
+helm repo add ingress-nginx https://kubernetes.github.io/ingress-nginx
+helm repo update
+helm install nginx-texera ingress-nginx/ingress-nginx \
+ --namespace texera --create-namespace \
+ --set controller.ingressClassResource.name=nginx \
+ --set controller.ingressClassResource.controllerValue="k8s.io/ingress-nginx" \
+ --set controller.ingressClass=nginx \
+ --set controller.service.loadBalancerIP=$TEXERA_IP \
+ --set controller.service.annotations."cloud\.google\.com/load-balancer-type"="External" \
+ --set rbac.create=true
+
+helm install nginx-minio ingress-nginx/ingress-nginx \
+ --namespace texera \
+ --set controller.ingressClassResource.name=nginx-minio \
+ --set controller.ingressClassResource.controllerValue="k8s.io/nginx-minio" \
+ --set controller.ingressClass=nginx-minio \
+ --set controller.service.loadBalancerIP=$MINIO_IP \
+ --set controller.service.annotations."cloud\.google\.com/load-balancer-type"="External" \
+ --set rbac.create=true
+```
+
+---
+
+## 3. Prepare Texera Installation
+
+Execute the following bash commands.
+
+```bash
+curl -L -o texera.zip https://github.com/Texera/texera/releases/download/1.1.0/texera-cluster-1-1-0-release.zip
+unzip texera.zip -d texera-cluster
+rm texera.zip
+helm dependency build texera-cluster
+```
+
+---
+
+## 4. Deploy Texera
+
+Execute the following bash command.
+
+```bash
+helm install texera texera-cluster --namespace texera --create-namespace \
+ --set postgresql.primary.persistence.storageClass=standard-rwo \
+ --set ingress-nginx.enabled=false \
+ --set metrics-server.enabled=false \
+ --set exampleDataLoader.enabled=false \
+ --set minio.customIngress.enabled=true \
+ --set minio.customIngress.ingressClassName=nginx-minio \
+ --set minio.customIngress.texeraHostname="http://$TEXERA_IP" \
+ --set minio.persistence.storageClass=standard-rwo \
+ --set-string lakefs.lakefsConfig="$(cat <`.
+
+
+**To remove the Texera deployment from your Kubernetes cluster, execute the following bash commands.**
+
+```
+helm uninstall texera -n texera
+helm uninstall nginx-texera -n texera
+helm uninstall nginx-minio -n texera
+```
+> Note: You also need to release the 2 allocated IP addresses on [GCP](https://console.cloud.google.com/networking/addresses/list)
+
+---
+
+## Advanced Configuration
+You can customize the deployment by adding the following --set flags to your helm install command. These flags allow you to configure authentication, resource limits, and the number of pods for Texera deployment.
+
+### Texera Credentials
+Texera relies on Postgres, MinIO and LakeFS that require credentials. You can change the default values to make your deployment more secure.
+
+**Default Texera Admin User**
+
+Texera ships with a built-in administrator account (username: texera, password: texera).
+To supply your own credentials during installation, pass the following Helm overrides:
+
+```bash
+# USER_SYS_ADMIN_USERNAME
+--set texeraEnvVars[0].value="" \
+# USER_SYS_ADMIN_PASSWORD
+--set texeraEnvVars[1].value="" \
+```
+
+**MinIO Authentication**
+```
+--set minio.auth.rootUser=texera_minio \
+--set minio.auth.rootPassword=password \
+```
+
+**PostgreSQL Authentication (username is always postgres)**
+```
+--set postgresql.auth.postgresPassword=root_password \
+```
+
+> 💡 Note: If you change the PostgreSQL password, you also need to change the following and add it to the install command:
+
+
+
+## 2. Reserve Two Static IPs (for Texera website and MinIO)
+
+After accessing your cluster using Cloud Shell, define the following variables based on your region and project in Step 1.
+```bash
+REGION=""
+PROJECT=""
+```
+
+Execute the following bash commands to reserve two Public IP addresses.
+
+```bash
+gcloud compute addresses create texera-ip --region=$REGION --project=$PROJECT
+TEXERA_IP=$(gcloud compute addresses describe texera-ip --region=$REGION --format="get(address)" --project $PROJECT)
+gcloud compute addresses create minio-ip --region=$REGION --project=$PROJECT
+MINIO_IP=$(gcloud compute addresses describe minio-ip --region=$REGION --format="get(address)" --project $PROJECT)
+```
+
+Execute the following bash commands to create two nginx controllers with helm.
+```bash
+helm repo add ingress-nginx https://kubernetes.github.io/ingress-nginx
+helm repo update
+helm install nginx-texera ingress-nginx/ingress-nginx \
+ --namespace texera --create-namespace \
+ --set controller.ingressClassResource.name=nginx \
+ --set controller.ingressClassResource.controllerValue="k8s.io/ingress-nginx" \
+ --set controller.ingressClass=nginx \
+ --set controller.service.loadBalancerIP=$TEXERA_IP \
+ --set controller.service.annotations."cloud\.google\.com/load-balancer-type"="External" \
+ --set rbac.create=true
+
+helm install nginx-minio ingress-nginx/ingress-nginx \
+ --namespace texera \
+ --set controller.ingressClassResource.name=nginx-minio \
+ --set controller.ingressClassResource.controllerValue="k8s.io/nginx-minio" \
+ --set controller.ingressClass=nginx-minio \
+ --set controller.service.loadBalancerIP=$MINIO_IP \
+ --set controller.service.annotations."cloud\.google\.com/load-balancer-type"="External" \
+ --set rbac.create=true
+```
+
+---
+
+## 3. Prepare Texera Installation
+
+Execute the following bash commands.
+
+```bash
+curl -L -o texera.zip https://github.com/Texera/texera/releases/download/1.1.0/texera-cluster-1-1-0-release.zip
+unzip texera.zip -d texera-cluster
+rm texera.zip
+helm dependency build texera-cluster
+```
+
+---
+
+## 4. Deploy Texera
+
+Execute the following bash command.
+
+```bash
+helm install texera texera-cluster --namespace texera --create-namespace \
+ --set postgresql.primary.persistence.storageClass=standard-rwo \
+ --set ingress-nginx.enabled=false \
+ --set metrics-server.enabled=false \
+ --set exampleDataLoader.enabled=false \
+ --set minio.customIngress.enabled=true \
+ --set minio.customIngress.ingressClassName=nginx-minio \
+ --set minio.customIngress.texeraHostname="http://$TEXERA_IP" \
+ --set minio.persistence.storageClass=standard-rwo \
+ --set-string lakefs.lakefsConfig="$(cat <`.
+
+
+**To remove the Texera deployment from your Kubernetes cluster, execute the following bash commands.**
+
+```
+helm uninstall texera -n texera
+helm uninstall nginx-texera -n texera
+helm uninstall nginx-minio -n texera
+```
+> Note: You also need to release the 2 allocated IP addresses on [GCP](https://console.cloud.google.com/networking/addresses/list)
+
+---
+
+## Advanced Configuration
+You can customize the deployment by adding the following --set flags to your helm install command. These flags allow you to configure authentication, resource limits, and the number of pods for Texera deployment.
+
+### Texera Credentials
+Texera relies on Postgres, MinIO and LakeFS that require credentials. You can change the default values to make your deployment more secure.
+
+**Default Texera Admin User**
+
+Texera ships with a built-in administrator account (username: texera, password: texera).
+To supply your own credentials during installation, pass the following Helm overrides:
+
+```bash
+# USER_SYS_ADMIN_USERNAME
+--set texeraEnvVars[0].value="" \
+# USER_SYS_ADMIN_PASSWORD
+--set texeraEnvVars[1].value="" \
+```
+
+**MinIO Authentication**
+```
+--set minio.auth.rootUser=texera_minio \
+--set minio.auth.rootPassword=password \
+```
+
+**PostgreSQL Authentication (username is always postgres)**
+```
+--set postgresql.auth.postgresPassword=root_password \
+```
+
+> 💡 Note: If you change the PostgreSQL password, you also need to change the following and add it to the install command:
+--set lakefs.secrets.databaseConnectionString="postgres://postgres:root_password@texera-postgresql:5432/texera_lakefs?sslmode=disable" \
+
+**LakeFS Authentication**
+```
+--set lakefs.auth.username=texera-admin \
+--set lakefs.auth.accessKey=AKIAIOSFOLKFSSAMPLES \
+--set lakefs.auth.secretKey=wJalrXUtnFEMI/K7MDENG/bPxRfiCYEXAMPLEKEY \
+--set lakefs.secrets.authEncryptSecretKey=random_string_for_lakefs \
+```
+
+### Allocating Resources
+If your cluster has more available resources, you can allocate additional CPU, memory, and disks to Texera to improve the performance.
+
+**Postgres**
+
+To allocate more CPU, Memory and disk to Postgres, do:
+```
+--set postgresql.primary.resources.requests.cpu=4 \
+--set postgresql.primary.resources.requests.memory=4Gi \
+--set postgresql.primary.persistence.size=50Gi \
+```
+
+**MinIO**
+
+To increase the storage for user's input dataset, do:
+```
+--set minio.persistence.size=100Gi
+```
+
+**Computing Unit**
+
+To customize options for the computing unit, do:
+```bash
+# MAX_NUM_OF_RUNNING_COMPUTING_UNITS_PER_USER
+--set texeraEnvVars[5].value="2" \
+# CPU_OPTION_FOR_COMPUTING_UNIT
+--set texeraEnvVars[6].value="1,2,4" \
+# MEMORY_OPTION_FOR_COMPUTING_UNIT
+--set texeraEnvVars[7].value="2Gi,4Gi,16Gi" \
+# GPU_LIMIT_OPTIONS
+--set texeraEnvVars[8].value="0,1" \ # to allow 0 or 1 GPU resource to be allocated
+```
+
+### Adjusting Number of Pods
+Scale out individual services for high availability or increased performance:
+
+```
+--set webserver.numOfPods=2 \
+--set workflowCompilingService.numOfPods=2 \
+--set pythonLanguageServer.replicaCount=2 \
+```
+
+
+### Retaining User Data
+By default, all user data stored by Texera will be deleted when the cluster deployment is removed. Since user data is valuable, you can preserve all datasets and files even after uninstalling the cluster by setting:
+```
+--set persistence.removeAfterUninstall=false
+```
\ No newline at end of file
diff --git a/texera.wiki/Guide-for-Developers.md b/texera.wiki/Guide-for-Developers.md
new file mode 100644
index 00000000000..50e68c55741
--- /dev/null
+++ b/texera.wiki/Guide-for-Developers.md
@@ -0,0 +1,352 @@
+## 0. Requirements
+
+#### **Java 11 JDK**
+
+Install `Java JDK 11 (Java Development Kit)` (recommend: `[adoptopenjdk](https://adoptium.net/installation/)`). To verify the installation, run:
+```console
+java -version
+```
+
+Next, set `JAVA_HOME`. On macOS you can run:
+```
+export JAVA_HOME=$(/usr/libexec/java_home -v 11)
+```
+On Windows, add a system environment variable called `JAVA_HOME` that points to the JDK directory.
+
+#### Python@3.12/3.11/3.10
+
+Install Python 3.12 (or 3.11/3.10) from the official site or your preferred package manager.
+
+#### **Git**
+
+On Windows, install the software from https://gitforwindows.org/. `Git Bash` is available after installing `Git`.
+
+On Mac and Linux, see https://git-scm.com/book/en/v2/Getting-Started-Installing-Git
+
+Verify the installation by:
+```console
+git --version
+```
+
+#### **sbt (Scala Build Tool)**
+
+Install `sbt` for building the project. Please refer to [sbt Reference Manual — Installing sbt](https://www.scala-sbt.org/1.x/docs/Setup.html). We recommend you to use [sdkman](https://sdkman.io/install) to install sbt.
+
+Verify the installation by:
+```console
+sbt --version
+```
+
+If the above command fails on Windows after installation, it is recommended to restart your computer.
+
+#### **node LTS Version > 18.x**
+
+Install an LTS version (not the latest) of `node`. Currently, we require LTS version > 18.x.
+
+On Windows, install from [https://nodejs.org/en/](https://nodejs.org/en/).
+
+On Mac and Linux, [use NVM to install NodeJS](https://www.linode.com/docs/guides/how-to-install-use-node-version-manager-nvm/) as it avoids permission issues.
+
+Verify the installation by:
+```console
+node -v
+```
+
+#### **Angular 16 Cli**
+
+Install the angular 16 cli globally:
+```console
+npm install -g @angular/cli@16
+```
+
+Verify the installation by:
+```console
+ng version
+```
+
+
+
+
+## 1. Setup Backend Development.
+
+
+
+### Clone and Configure Texera
+
+In the terminal, clone the Texera repo:
+```console
+git clone git@github.com:Texera/texera.git
+```
+
+Do the following changes to the configuration files:
+- Edit `common/config/src/main/resources/storage.conf` to use your Postgres credentials.
+```diff
+ jdbc {
+
+- username = "postgres"
++ username =
+ username = ${?STORAGE_JDBC_USERNAME}
+
+- password = "postgres"
++ password =
+ password = ${?STORAGE_JDBC_PASSWORD}
+ }
+```
+
+- Edit `common/config/src/main/resources/udf.conf` to use the correct python executable path(can be obtained by command `which python` or `where python`):
+```diff
+python {
+- path =
++ path = "/the/executable/path/of/python"
+}
+```
+
+### Setup PostgreSQL locally
+
+Texera uses [PostgreSQL](https://www.postgresql.org/) to manage the user data and system metadata. To install and configure it:
+Install [Postgres](https://www.postgresql.org/download/). If you are using Mac, simply execute:
+```console
+brew install postgresql
+```
+
+Install [Pgroonga](https://pgroonga.github.io/install/) for enabling full-text search, if you are using Mac, simply execute:
+```console
+brew install pgroonga
+```
+
+Execute `sql/texera_ddl.sql` to create `texera_db` database for storing user system data & metadata storage
+```console
+psql -U postgres -f "sql/texera_ddl.sql"
+```
+Execute `sql/iceberg_postgres_catalog.sql` to create the database for storing Iceberg catalogs.
+```console
+psql -U postgres -f "sql/iceberg_postgres_catalog.sql"
+```
+
+### Setup the LakeFS+Minio locally
+
+Texera requires [LakeFS](https://lakefs.io/) and S3([Minio](https://min.io/docs/minio/kubernetes/upstream/index.html) is one of the implementations) as the dataset storage. Setting up these two storage services locally are required to make Texera's dataset feature functioning.
+
+Install [Docker Desktop](https://docs.docker.com/desktop/setup/install/mac-install/) which contains both docker engine and docker compose. Make sure you launch the Docker after installing it.
+
+In the terminal, enter the directory containing the docker-compose file:
+```
+cd file-service/src/main/resources
+```
+
+Edit `docker-compose.yml` by: search for `volumes` in the file and follow the instructions in the comment. This step is required otherwise your data will be lost if containers are deleted
+
+Execute the following command to start LakeFS and Minio:
+```
+docker compose up
+```
+
+### Import the project into IntelliJ
+
+
+Before you import the project, you need to have "Scala", and "SBT Executor" plugins installed in Intellij.
+ +
+
+1. In Intellij, open `File -> New -> Project From Existing Source`, then choose the `texera` folder.
+2. In the next window, select `Import Project from external model`, then select `sbt`.
+3. In the next window, make sure `Project JDK` is set. Click OK.
+4. IntelliJ should import and build this Scala project. In the terminal under `texera`, run:
+```
+sbt clean protocGenerate
+```
+This will generate proto-specified codes. And the IntelliJ indexing should start. Wait until the indexing and importing is completed. And on the right, you can open the sbt tab and check the loaded `texera` project and couple of sub projects:
+
+
+
+
+1. In Intellij, open `File -> New -> Project From Existing Source`, then choose the `texera` folder.
+2. In the next window, select `Import Project from external model`, then select `sbt`.
+3. In the next window, make sure `Project JDK` is set. Click OK.
+4. IntelliJ should import and build this Scala project. In the terminal under `texera`, run:
+```
+sbt clean protocGenerate
+```
+This will generate proto-specified codes. And the IntelliJ indexing should start. Wait until the indexing and importing is completed. And on the right, you can open the sbt tab and check the loaded `texera` project and couple of sub projects:
+
+ +
+5. When IntelliJ prompts "Scalafmt configuration detected in this project" in the bottom right corner, select "Enable".
+If you missed the IntelliJ prompt, you can check the `Event Log` on the bottom right
+
+6. In addition to the microservices, you need to run the `JooqCodeGenerator` located at `common/dao/src/main/scala/org/apache/texera/dao/JooqCodeGenerator.scala` before starting the microservices for the first time, or each time you make changes to the database.
+
+### Run the backend micro services in IntelliJ
+The easiest way to run backend services is in IntelliJ.
+Currently we have couple of micro services for different purposes. If one microservice failed after running, it may have dependency to another microservice, so wait for other ones to start, also make sure to run LakeFS docker compose:
+
+| **Component** | **File Path** | **Purpose / Functionality** |
+|---|---|---|
+| **ConfigService** | `config-service/src/main/scala/`
+
+5. When IntelliJ prompts "Scalafmt configuration detected in this project" in the bottom right corner, select "Enable".
+If you missed the IntelliJ prompt, you can check the `Event Log` on the bottom right
+
+6. In addition to the microservices, you need to run the `JooqCodeGenerator` located at `common/dao/src/main/scala/org/apache/texera/dao/JooqCodeGenerator.scala` before starting the microservices for the first time, or each time you make changes to the database.
+
+### Run the backend micro services in IntelliJ
+The easiest way to run backend services is in IntelliJ.
+Currently we have couple of micro services for different purposes. If one microservice failed after running, it may have dependency to another microservice, so wait for other ones to start, also make sure to run LakeFS docker compose:
+
+| **Component** | **File Path** | **Purpose / Functionality** |
+|---|---|---|
+| **ConfigService** | `config-service/src/main/scala/`
`org/apache/texera/service/`
`ConfigService.scala` | Hosts the system configurations to allow the frontend to retrieve configuration data. |
+| **TexeraWebApplication** | `amber/src/main/scala/`
`org/apache/texera/web/`
`TexeraWebApplication.scala` | Provides user login, community resource read/write operations, and loads metadata for available operators. |
+| **FileService** | `file-service/src/main/scala/`
`org/apache/texera/service/`
`FileService.scala` | Provides dataset-related endpoints including dataset management, access control, and read/write operations across datasets. |
+| **WorkflowCompilingService** | `workflow-compiling-service/src/main/scala/`
`org/apache/texera/service/`
`WorkflowCompilingService.scala` | Propagates schema and checks for static errors during workflow construction. |
+| **ComputingUnitMaster** | `amber/src/main/scala/`
`org/apache/texera/web/`
`ComputingUnitMaster.scala` | Manages workflow execution and acts as the master node of the computing cluster.
**Must start before `ComputingUnitWorker`.** |
+| **ComputingUnitWorker** | `amber/src/main/scala/`
`org/apache/texera/web/`
`ComputingUnitWorker.scala` | A worker node in the computing cluster (not a web server). |
+| **ComputingUnitManagingService** | `computing-unit-managing-service/src/main/scala/`
`org/apache/texera/service/`
`ComputingUnitManagingService.scala` | Manages the lifecycle of different types of computing units and their connections to users' frontends. |
+| **AccessControlService** | `access-control-service/src/main/scala/`
`org/apache/texera/service/`
`AccessControlService.scala` | Authorize requests sent to computing unit, currently not needed to run for local development, it is only used in Kubernetes setup. |
+
+
+
+To run each of the above web service, go to the corresponding scala file(i.e. for `TexeraWebApplication`, go find TexeraWebApplication.scala), then run the main function by pressing on the green run button and wait for the process to start up.
+
+For `TexeraWebApplication`, the following message indicates that it is successfully running:
+```
+[main] [akka.remote.Remoting] Remoting now listens on addresses:
+org.eclipse.jetty.server.Server: Started
+```
+* If IntelliJ displays CreateProcess error=206, the filename or extension is too long : [add the -Didea.dynamic.classpath=true in Help | Edit Custom VM Options and restart the IDE](https://youtrack.jetbrains.com/issue/IDEA-285090)
+
+
+For `ComputingUnitMaster`, the following prompt indicates that it is successfully running:
+
+```
+---------Now we have 1 node in the cluster---------
+```
+
+### Enable Python-based Operators
+
+Texera has lots of Python-based operators like visualizations, and UDF operators. To enable them, install python dependencies by executing, you also need to install R in your system:
+```console
+cd texera
+pip install -r amber/requirements.txt -r amber/operator-requirements.txt
+```
+
+
+
+
+
+
+
+
+## 2. Launch Frontend
+
+This is for developers that work on the frontend part of the project. This step is NOT needed if you develop the backend only.
+
+Before you start, make sure the backend services are all running.
+
+### Install Angular CLI
+```console
+cd frontend
+yarn install
+```
+
+Ignore those warnings (warnings are usually marked in yellow color or start with `WARN`).
+
+### Launch Frontend in IntelliJ for local development
+
+1. Click on the Green Run button next to the `start` in `frontend/package.json`.
+2. Wait for some time and the server will get started. Open a browser and access `http://localhost:4200`. You should see the Texera UI with a canvas.\
+
+ +
+
+Every time you save the changes to the frontend code, the browser will automatically refresh to show the latest UI.
+You can also run frontend using command line:
+```console
+yarn start
+```
+
+### Launch Frontend in the production environment
+
+Run the following command
+```
+yarn run build
+```
+This command will optimize the frontend code to make it run faster. This step will take a while. After that, start the backend engine in IntelliJ and use your browser to access `http://localhost:8080`.
+
+
+
+
+
+Every time you save the changes to the frontend code, the browser will automatically refresh to show the latest UI.
+You can also run frontend using command line:
+```console
+yarn start
+```
+
+### Launch Frontend in the production environment
+
+Run the following command
+```
+yarn run build
+```
+This command will optimize the frontend code to make it run faster. This step will take a while. After that, start the backend engine in IntelliJ and use your browser to access `http://localhost:8080`.
+
+
+
+
+
+
+
+
+## 3. Email Notification (Optional)
+
+
+1. Set `smtp` in `config/src/main/resources/user-system.conf`. You need an App password if the account has 2FA.
+2. Log in to Texera with an admin account.
+3. Open the Gmail dashboard under the admin tab.
+5. Send a test email.
+
+
+
+
+
+
+## 4. Misc
+
+
+
+This part is optional; you only need to do this if you are working on a specific task.
+
+### To create a new database table and write queries using Java through Jooq
+1. Create the needed new table in MySQL and update `sql/texera_ddl.sql` to include the new table.
+2. Run `common/dao/src/main/scala/org/apache/texera/dao/JooqCodeGenerator.scala` to generate the classes for the new table.
+
+Note: Jooq creates DAO for simple operations if the requested SQL query is complex, then the developer can use the generated Table classes to implement the operation
+
+### Disable password login
+Edit `config/src/main/resources/gui.conf`, change `local-login` to `false`.
+
+### Enforce invite only
+Edit `config/src/main/resources/user-system.conf`, change `invite-only` to `true`.
+
+### Backend endpoints Role Annotation
+There are two types of permissions for the backend endpoints:
+1. @RolesAllowed(Array("Role"))
+2. @PermitAll
+Please don't leave the permission setting blank. If the permission is missing for an endpoint, it will be @PermitAll by default.
+
+### **Windows: enable long paths**
+
+Some workflows create deep directories (e.g., when writing `metadata.json` via Python/ICEBERG). On Windows, this can exceed the legacy `MAX_PATH` (~260 chars) and cause failures like:
+
+```
+[WinError 3] The system cannot find the path specified.
+```
+
+Enable long paths support (per machine) by running PowerShell **as Administrator**:
+
+```powershell
+New-ItemProperty -Path "HKLM:\SYSTEM\CurrentControlSet\Control\FileSystem" -Name "LongPathsEnabled" -Value 1 -PropertyType DWORD -Force
+```
+
+Verify the setting (expected value: `1`):
+
+```powershell
+Get-ItemProperty -Path "HKLM:\SYSTEM\CurrentControlSet\Control\FileSystem" -Name "LongPathsEnabled"
+```
+
+> If you cannot change this policy (e.g., on managed devices), keep your workspace path short (e.g., `C:\src\texera`) to reduce overall path length.
+
+### **Windows: Fix `HADOOP_HOME` errors**
+
+On Windows, if you encounter the following error when executing a workflow:
+
+```
+Caused by: java.io.FileNotFoundException: HADOOP_HOME and hadoop.home.dir are unset
+```
+
+here are the steps to solve this issue:
+
+**Steps**
+
+1. Obtain a `winutils.exe` matching your Hadoop line (Texera currently uses Hadoop 3.3.x).
+ - Suggested source (use any equivalent source approved for your environment):
+ https://github.com/cdarlint/winutils/tree/master/hadoop-3.3.5/bin
+2. Create the directory and place the binary:
+ ```
+ C:\hadoop\bin\winutils.exe
+ ```
+3. In IntelliJ, add this **VM option** to the **FileService** run configuration:
+ ```
+ -Dhadoop.home.dir="C:\hadoop"
+ ```
+4. (Optional) Also set a system environment variable and restart the IDE/terminal:
+ ```
+ HADOOP_HOME=C:\hadoop
+ ```
+
+**Notes**
+
+- This issue may happen only on **Windows**; macOS/Linux do not need `winutils.exe`.
+- Ensure the `winutils.exe` you use matches your Hadoop major/minor (e.g., 3.3.x).
+- After configuring, the prior read/write and “unset” errors should disappear.
+
+
+
\ No newline at end of file
diff --git a/texera.wiki/Guide-for-how-to-use-Texera.md b/texera.wiki/Guide-for-how-to-use-Texera.md
new file mode 100644
index 00000000000..80808f7ad5f
--- /dev/null
+++ b/texera.wiki/Guide-for-how-to-use-Texera.md
@@ -0,0 +1,41 @@
+Texera is an open-source system that supports collaborative data science at scale using Web-based workflows. This page includes instructions on how to install the system as a developer and do a simple workflow.
+
+## Prerequisites
+We assume you either went through [Single Node Instruction](https://github.com/Texera/texera/wiki/Installing-Texera-on-a-Single-Node), or the [Guide for Texera Developers](https://github.com/Texera/texera/wiki/Guide-for-Developers). And Texera is up-and-running on your laptop.
+
+## Access Texera through Browser
+Enter Texera's URL on your browser to access Texera.
+
+An admin account with username `texera` and password `texera` is pre-created by default. Input the username, password and click the `Sign in` button to login as the admin:
+
+
+### User Dashboard UI Overview
+Once logged in, you should see the below page:
+
+
+This is Texera's dashboard page. On the left navigation bar, you can switch between different resource modules, including
+- `Workflows` for workflow management
+- `Datasets` for dataset management
+- `Quota` for checking the usage statistics
+- `Admin` for managing users on the Texera system. This tab is only visible for system admins.
+
+### Workflow Workspace UI Overview
+
+
+
+1. **Operator Library/Menu**:
+
+ It is separated into multiple dropdown menus based on the operator type, e.g., Source Operator, Search Operator, etc. You can drag and drop an operator from these dropdown menus onto the Workflow Canvas.
+
+2. **Workflow Canvas**:
+
+ It is the main playground, where you can drag and drop Operators from the Operator Library onto it. Each operator is shown as a square box and connected with other operators with arrowed links which indicates the data flow.
+
+3. **Properties Editor Panel**:
+
+ The panel will show up when you highlight a specific operator (by clicking on it) in the Workflow Canvas. You can customize the properties of the selected operator, for example, set the keyword for a filter. When the selected operator is configured correctly, a green ring will surround it; while a red ring usually indicates an error in configuration or connection to other operators.
+
+4. **Result Panel**:
+
+ By default or when there is no result, it is hidden. You can click on the little UP arrow to expand this panel. When a workflow is finished running, the result panel will pop up with the data. You may slide up and down or left and right to view the data inside the panel.
+
diff --git a/texera.wiki/Guide-to-Frontend-Development-(new-gui).md b/texera.wiki/Guide-to-Frontend-Development-(new-gui).md
new file mode 100644
index 00000000000..997d9fd1575
--- /dev/null
+++ b/texera.wiki/Guide-to-Frontend-Development-(new-gui).md
@@ -0,0 +1,47 @@
+**Author: Yinan Zhou**
+
+# Introduction:
+ If you are new to Texera frontend development team or have little frontend experience using angular framework (version 6), this read intends to provide you with a simple guide of how to get started.
+
+# Preparation phase:
+ In a nutshell, angular provides modularity, scalability, and robustness to traditional frontend code design. It separates a website into different individual components that can each perform a certain level of independent tasks. It then connects different components with services so they can work collaboratively. It also provides unit testing at the component level as well as application level.
+ Other than these, angular largely inherits the traditional way of creating a web page. Each component contains four foundational files (.ts | .html | .css | spec.ts), corresponding to typescript (which is basically JavaScript with better scalability), HTML, CSS, and unit testing respectively. Just like how web pages were traditionally written, you will be coding in
+ 1) html: the structure of the component
+ 2) css: the style of the component
+ 3) typescript: the content of the component
+and additionally:
+ 4) unit tests: so that the component can be debugged in the future if it breaks
+
+Don’t be overwhelmed. You don't have to be a master in all these four fields to start working on texera frontend. If you have basic web development experience, you can jump to the next section to get started with learning angular. If you have no such experience, you should at least spend a few hours getting familiar with HTML, CSS, and JavaScript. The following links might be helpful.
+* An overview of HTML: https://www.youtube.com/watch?v=LcS5IgnAeUs
+* An overview of CSS: https://www.youtube.com/watch?v=Eogk9jWYeMk
+* Simple JavaScript example: https://www.youtube.com/watch?v=LFa9fnQGb3g
+
+The following links are documentation and examples, don't try to master all the knowledge from these websites at once, use them as dictionaries. They will be helpful when you start coding so don't waste too much time on them now.
+* HTML: https://www.w3schools.com/html/
+* Typescript: https://www.tutorialspoint.com/typescript/typescript_overview.htm
+* CSS: https://www.w3schools.com/Css/
+
+# Angular Tutorial Phase:
+At this point, you should at least be able to interpret an HTML/CSS/Typescript file with your own knowledge and the information you can find online. For the next few weeks,
+ 1) go through the tutorial provided on the Angular official website, https://angular.io/guide/quickstart
+ 2) watch tutorial videos, (ask frontend group leader to share the videos with you on google drive)
+ 3) especially pay attention to the rxjs videos, you will need them a lot.
+
+ Although these tutorial videos are helpful, it can take a long time to finish watching them. Meanwhile, it is easy to forget what you have learned if you do not practice coding it. Therefore, I recommend you begin the next phase once you finish step 1.
+
+# Frontend Code Base:
+At this point, you should know how to approach a simple angular application and interpret it using your own knowledge and the information you can find online. Download Visual Studio Code and relevant extensions, get access to Texera front-end code base (instructions can be found here). You should:
+ 1) have a general understanding of the structure of the new-gui, what components are there? What do they do? What services are connecting them.
+ 2) You should have a feature in mind that you want to implement. Locate the component and services that are relevant to the feature you want to implement. Carefully read through the code in those sections, make sure you understand what is going on behind the scene.
+ 3) Start coding, then debug, and repeat. :)
+ 4) Look for solutions in the tutorial videos I mentioned in the previous phase step 2&3 when you have questions.
+ 5) Make good use of google, stack overflow, etc. However, be aware that a lot of code examples online can be outdated since we are using the most recent version of angular with rxjs.
+
+useful tips that you should know how:
+ 1) Right-click a variable/class/method name in the code base in visual studio code, then click "Peek Definition" or "Find All References". It shows you how it was defined and where it has been used.
+ 2) Right-click web page and inspect elements
+ 3) You can Console.log(ThingsYouWantToInspect) in the code base; the logged information will appear in the console window after you do step 2.
+
+# Unit testing:
+Don’t worry about unit testing at the beginning. Finish the feature first and then write unit tests for it.
\ No newline at end of file
diff --git a/texera.wiki/Guide-to-Implement-a-Java-Native-Operator.md b/texera.wiki/Guide-to-Implement-a-Java-Native-Operator.md
new file mode 100644
index 00000000000..aa01163ddf1
--- /dev/null
+++ b/texera.wiki/Guide-to-Implement-a-Java-Native-Operator.md
@@ -0,0 +1,278 @@
+
+In this page, we'll explain the basic concepts in Texera and use examples to show how to implement an operator.
+
+### Code structure of every operator:
+
+Every operator ideally has three classes that are found in each operator package in `core\workflow-operator\src\main\scala\edu\uci\ics\amber\operator`
+* LogicalOp
+* OperatorExecutor
+* OperatorExecutorConfig
+
+### Basic concepts:
+
+A Texera user constructs a workflow using the frontend, which consists of many operators. Each operator take input data from its previous operator(s), does some computation, and outputs the results to the next operator(s).
+
+Suppose we have the following sample records, each of which has an ID and a tweet.
+```
+id tweet
+1 "today is a good day"
+2 "weather is bad during the day"
+```
+
+Each row is called a `Tuple`, and each column is called a `Field`.
+
+```scala
+// get the value of a field by column name
+tuple1.getField("id") // result: 1
+tuple1.getField("tweet") // result: "today is a good day"
+
+// get the value by column index
+tuple1.get(0) // result: 1
+```
+
+In this dataset, we have 2 columns, namely `id` of the integer type and `tweet` of the string type. This information is called a `Schema`.
+A `schema` contains a list of `attributes`, and each `attribute` has a `name` (name of the column) and a `type` (data type of the column).
+
+```scala
+schema = tuple.getSchema()
+schema.getAttributes().get(0) // Attribute("id", AttributeType.Integer)
+schema.getAttributes().get(1) // Attribute("tweet", AttributeType.String)
+```
+
+
+### Example 1: Regular Expression (regex) operator
+
+A regular expression operator matches a regular expression (regex) on each input tuple. For example, if we search the regex "weather" on the `tweet` attribute, then only tuple 2 will be the result. In other words, the regular expression operator is a kind of `filter()` operation in many programming languages.
+
+To implement a regular expression operator, you will first need to write an `LogicalOp`. The following code is part of class [`RegexOpDesc`](https://github.com/apache/texera/blob/main/core/workflow-operator/src/main/scala/edu/uci/ics/amber/operator/regex/RegexOpDesc.scala) .
+
+```scala
+class RegexOpDesc extends FilterOpDesc {
+
+ @JsonProperty(required = true)
+ @JsonSchemaTitle("attribute")
+ @JsonPropertyDescription("column to search regex on")
+ @AutofillAttributeName
+ var attribute: String = _
+
+ @JsonProperty(required = true)
+ @JsonSchemaTitle("regex")
+ @JsonPropertyDescription("regular expression")
+ var regex: String = _
+
+ @JsonProperty(required = false, defaultValue = "false")
+ @JsonSchemaTitle("Case Insensitive")
+ @JsonPropertyDescription("regex match is case sensitive")
+ var caseInsensitive: Boolean = _
+}
+```
+
+The regular expression operator needs to take 3 properties from the user, namely `attribute` (the name of the column to search on), `regex` (the regular expression itself) and `caseInsensitive` (whether case sensitive for this regular expression).
+
+The `@JsonProperty` annotation will let the system know that this property needs to come from the user input, and it will automatically generate the corresponding input form in the frontend.
+Inside `@JsonProperty`, `required = true` tells the frontend that this property is required from the user. The property also needs to provide a user-friendly title (inside `@JsonSchemaTitle` annotation) and a detailed description (inside `@JsonPropertyDescription` annotation). `@AutofillAttributeName` annotation tells the frontend to provide autocomplete on attribute name (name of the column).
+
+This operator descriptor also needs to provide information about this operator, including a user-friendly name, description, the group it belongs to, and number of input/output ports.
+```scala
+ override def operatorInfo: OperatorInfo =
+ OperatorInfo(
+ userFriendlyName = "Regular Expression",
+ operatorDescription = "Search a regular expression in a string column",
+ operatorGroupName = OperatorGroupConstants.SEARCH_GROUP,
+ numInputPorts = 1,
+ numOutputPorts = 1
+ )
+```
+
+Finally, the operator descriptor needs to specify its corresponding operator executor. An `OperatorExecutor`, or `OpExec` for short, contains the implementation of the processing logic in the operator. For the regular expression operator, it corresponds to `RegexOpExec`. The OpDesc supplies an `OpExecInitInfo` with a function that creates the corresponding operator executor `() => new RegexOpExec(this)`. When creating a PhysicalOp (e.g., using `oneToOnePhysicalOp` in this case, which is one type of physical operator that should be used in most cases), the `OpExecInitInfo` is passed in for the PhysicalOp to use.
+
+```scala
+ PhysicalOp.oneToOnePhysicalOp(
+ executionId,
+ operatorIdentifier,
+ OpExecInitInfo(_ => new RegexOpExec(this))
+ )
+```
+
+The implementation of the regular expression operator executor is rather simple. Since this operator is doing a kind of `filter()` operation, it extends a pre-defined class `FilterOpExec`. It calls `setFilterFunc` to specify the filter function used by this operator: the `matchRegex` function. In `matchRegex`, we first get the string value of a column, and then test if the value matches the regex.
+
+```scala
+class RegexOpExec(val opDesc: RegexOpDesc) extends FilterOpExec {
+ val pattern: Pattern = Pattern.compile(opDesc.regex)
+ this.setFilterFunc(this.matchRegex)
+
+ def matchRegex(tuple: Tuple): Boolean = {
+ val tupleValue = tuple.getField(opDesc.attribute).toString
+ return pattern.matcher(tupleValue).find
+ }
+}
+```
+
+This operator needs to be registered to let the system know its existence. In the `LogicalOp` class, we need to add a new entry, which specifies its operator descriptor class and a unique operator name.
+
+```scala
+@JsonSubTypes(
+ Array(
+ new Type(value = classOf[RegexOpDesc], name = "Regex"),
+ )
+)
+abstract class LogicalOp extends PortDescriptor with Serializable {
+}
+```
+
+Now this operator will be automatically available in the frontend. We can now start the system and test this operator.
+
+To add an image for this operator, go to `core/gui/src/assets/operator_images`, then add an image with the _**SAME NAME**_ as what's specified in the operator registration. The image file should be in `png` format, with a transparent background, black and white, and should be square.
+
+For example, for the regex operator, the code `new Type(value = classOf[RegexOpDesc], name = "Regex")` specified a name `Regex`, then the image file name should be `Regex.png`.
+
+
+Summary: we have gone through the steps to implement a simple regular expression operator. This operator is a type of `filter()` operation. So it's built on top of a set of pre-defined classes, `FilterOpDesc`, `FilterOpExec`, and `FilterOpExecConfig`.
+
+### Example 2: Sentiment Analysis operator
+
+A `map()` operation processes one input tuple and produces exactly one output tuple. Next, we'll briefly explain the `map()` type of operators using the Sentiment Analysis operator as an example.
+
+The sentiment analysis operator uses the Stanford NLP package to analyze the sentiment of a text. Given the example dataset above, the output of this operator looks like this:
+```
+id tweet sentiment
+1 "today is a good day" "positive"
+2 "weather is bad during the day" "negative"
+```
+
+
+The following code is the implementation of class [`SentimentAnalysisOpDesc`](https://github.com/apache/texera/blob/main/core/workflow-operator/src/main/scala/edu/uci/ics/amber/operator/huggingFace/HuggingFaceSentimentAnalysisOpDesc.scala) in Java.
+
+```java
+public class SentimentAnalysisOpDesc extends MapOpDesc {
+
+ @JsonProperty(required = true)
+ @JsonSchemaTitle("attribute")
+ @JsonPropertyDescription("column to perform sentiment analysis on")
+ @AutofillAttributeName
+ public String attribute;
+
+ @JsonProperty(value = "result attribute", required = true, defaultValue = "sentiment")
+ @JsonPropertyDescription("column name of the sentiment analysis result")
+ public String resultAttribute;
+
+ @Override
+ public OneToOneOpExecConfig operatorExecutor() {
+ return new OneToOneOpExecConfig(operatorIdentifier(), () -> new SentimentAnalysisOpExec(this));
+ }
+
+ @Override
+ public OperatorInfo operatorInfo() {
+ return new OperatorInfo(
+ "Sentiment Analysis",
+ "analysis the sentiment of a text using machine learning",
+ OperatorGroupConstants.ANALYTICS_GROUP(),
+ 1, 1
+ );
+ }
+
+ @Override
+ public Schema getOutputSchema(Schema[] schemas) {
+ if (resultAttribute == null || resultAttribute.trim().isEmpty()) {
+ return null;
+ }
+ return Schema.newBuilder().add(schemas[0]).add(resultAttribute, AttributeType.STRING).build();
+ }
+}
+```
+
+You'll notice that this operator implements a new function, `getOutputSchema`. This is because this operator adds a new column called `sentiment`. The function `getOutputSchema` returns the output schema produced by this operator given an input schema.
+
+In this implementation, `resultAttribute` is the new column name given by the user (default value is "sentiment"). If the value is empty, we return a null value to indicate that the output schema cannot be produced. The result schema includes all the attributes from the input schema, plus a new attribute of type string.
+
+The regular expression operator does not implement this function because a `filter()` operation does not add or remove any columns.
+
+The implementation of `SentimentAnalysisOpExec` extends `MapOpExec` and provides a map function. You can check the implementation in the codebase.
+
+### Generic operations
+
+In Texera, currently we have 4 pre-defined operations you can extend.
+ - `filter()`: filters out any input tuple if it doesn't satisfy a condition.
+ - `map()`: for each input tuple, transforms it to exactly one output tuple.
+ - `flatmap()`: for each input tuple, transforms it to a list of output tuples.
+ - `aggregate()`: performs an aggregation, such as sum, count, average, etc.
+
+To implement an operator, you can first check if your operator can be implemented using the 4 pre-defined operations. You can find these pre-defined operations under [`texera/workflow/common/operators`](https://github.com/Texera/texera/tree/master/core/amber/src/main/scala/edu/uci/ics/texera/workflow/common/operators). Your own operator implementation should be in [`texera/workflow/operators/youroperator`](https://github.com/Texera/texera/tree/master/core/amber/src/main/scala/edu/uci/ics/texera/workflow/operators).
+
+### Low-level OperatorExecutor API
+For more complicated operators, if they cannot be implemented using these operations, then you need to implement `OperatorExecutor` using the following low-level interface.
+
+```scala
+trait IOperatorExecutor {
+
+ def open(): Unit
+
+ def close(): Unit
+
+ def processTuple(tuple: Either[ITuple, InputExhausted], input: Int): Iterator[ITuple]
+
+}
+```
+
+The `open()` and `close()` functions allow you to initialize and dispose any resources (such as opened files), respectively. They will be called once before and after the whole execution by the engine. The important function is `processTuple`, which implements the processing logic inside the operator.
+
+The `processTuple` function takes two parameters: `tuple` and `input`. Since an operator can have multiple input ports, and each input port can have multiple input operators connected to (e.g., Union), `input: Int` indicates which input port the current tuple is coming from. The parameter `tuple` is either a `Tuple` type or an `InputExhausted` type, indicating all data from an input operator has been exhausted. It returns an `Iterator[Tuple]`, which means zero or more output tuples can be produced following this input. `processTuple` will be called whenever a new input tuple arrives, and called once if the input is exhausted. When an input port is connected to multiple input operators, this `InputExhausted` will be processed multiple times (once per input operator).
+
+## General content:
+### User input information
+Texera's backend is responsible for determining the UI information to the frontend. After receiving the information, the frontend efficiently translates and presents the content.
+* Input Box
+
+ 
+
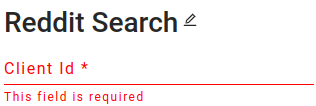
+ Here is an example of a user input box, with the name “Client Id” and its description.
+ ```python
+ @JsonProperty(required=true)
+ @JsonSchemaTitle("Client Id")
+ @JsonPropertyDescription("Client id that uses to access Reddit API")
+ var clientId: String = _
+ ```
+
+
+* Multiple selection
+
+ 
+
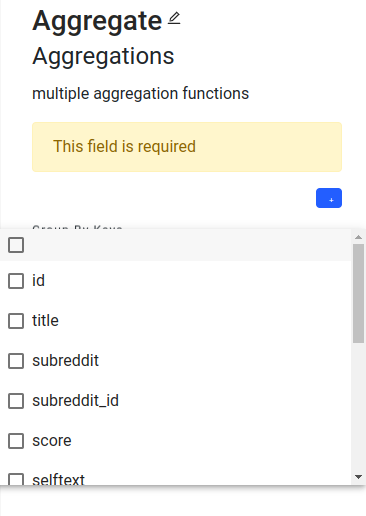
+ Here is an example of a multiple selection in the aggregate operator.
+ ```python
+ @JsonProperty(value = "attribute", required = true)
+ @JsonPropertyDescription("column to calculate average value")
+ @AutofillAttributeName
+ var attribute: String = _
+ ```
+ In the backend, we assign the attribute name list to fill the selections. Since it is multiselection, the type needs to be a list.
+* Checkbox
+
+ 
+
+ For the checkbox, we assign the data type to boolean. Here is an example in pythonUDF operator. By setting the data type to boolean, we successfully implement it as a checkbox.
+ ```python
+ @JsonProperty(required = true, defaultValue = "true")
+ @JsonSchemaTitle("Retain input columns")
+ @JsonPropertyDescription("Keep the original input columns?")
+ var retainInputColumns: Boolean = Boolean.box(false)
+ ```
+
+* List
+
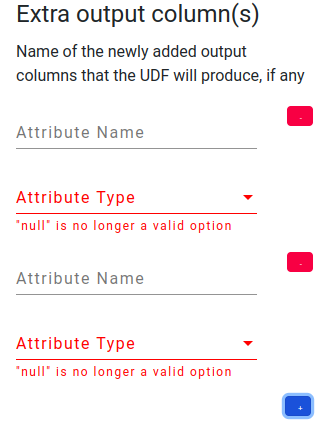
+ 
+
+ In pythonUDF operator, there is an example of a list, which is for the output schema. By clicking the blue button, we can add one more pair of attribute information. And the red button will delete such attribute information. In the backend, we have a list to hold the attribute values.
+ ```python
+ @JsonProperty
+ @JsonSchemaTitle("Extra output column(s)")
+ @JsonPropertyDescription(
+ "Name of the newly added output columns that the UDF will produce, if any"
+ )
+ var outputColumns: List[Attribute] = List()
+ ```
+
+### Registration and icon
+In the file `amber/src/main/scala/edu/uci/ics/texera/workflow/common/operators/LogicalOp.scala`, you will find a list of all registered operators, complete with their descriptor classes and names. After adding an operator's information, you can assign an icon to it. All operator icons are stored in the `/core/new-gui/src/assets/operator_images` directory. It's essential to ensure that the icon filename matches its respective operator descriptor name.
+
+
diff --git a/texera.wiki/Guide-to-Implement-a-Python-Native-Operator-(converting-from-a-Python-UDF).md b/texera.wiki/Guide-to-Implement-a-Python-Native-Operator-(converting-from-a-Python-UDF).md
new file mode 100644
index 00000000000..bb9523f65ea
--- /dev/null
+++ b/texera.wiki/Guide-to-Implement-a-Python-Native-Operator-(converting-from-a-Python-UDF).md
@@ -0,0 +1,86 @@
+In the [page for PythonUDF](https://github.com/Texera/texera/wiki/Guide-to-Use-a-Python-UDF), we introduced the basic concepts of PythonUDF and described each API. To let other users use the Python operators, it is necessary to implement it as a native operator.
+
+In this section, we will discuss how to implement a Python native operator and let future users drag and drop it on the UI. We will start by implementing a sample UDF then talk about how to convert it to a native operator.
+
+## **Starting with a Sample Python UDF**
+
+Suppose we have a sample Python UDF named `Treemap Visualizer`, as presented below:
+
+ +
+
+The UDF takes a CSV file as its input. For this example, we use a dataset of geo-location information of tweets. A sample of the dataset is shown below:
+
+
+
+
+The UDF takes a CSV file as its input. For this example, we use a dataset of geo-location information of tweets. A sample of the dataset is shown below:
+
+ +
+The `Treemap Visualizer` UDF takes the CSV file as a table (using the Table API) and outputs an HTML page that contains a treemap figure. The HTML page will be consumed by the HTML visualizer operator, and the `View Result` operator eventually displays the figure in the browser. The visualization is presented below:
+
+
+
+The `Treemap Visualizer` UDF takes the CSV file as a table (using the Table API) and outputs an HTML page that contains a treemap figure. The HTML page will be consumed by the HTML visualizer operator, and the `View Result` operator eventually displays the figure in the browser. The visualization is presented below:
+
+ +
+Now, let's take a closer look at the `Treemap Visualizer` UDF.
+As shown in the following code block, the UDF contains 3 steps:
+```python
+from pytexera import *
+
+import plotly.express as px
+import plotly.io
+import plotly
+import numpy as np
+
+
+class ProcessTableOperator(UDFTableOperator):
+
+ @overrides
+ def process_table(self, table: Table, port: int) -> Iterator[Optional[TableLike]]:
+ table = table.groupby(['geo_tag.countyName','geo_tag.stateName']).size().reset_index(name='counts')
+ #print(table)
+ fig = px.treemap(table, path=['geo_tag.stateName','geo_tag.countyName'], values='counts',
+ color='counts', hover_data=['geo_tag.countyName','geo_tag.stateName'],
+ color_continuous_scale='RdBu',
+ color_continuous_midpoint=np.average(table['counts'], weights=table['counts']))
+ fig.update_layout(margin=dict(t=50, l=25, r=25, b=25))
+ html = plotly.io.to_html(fig, include_plotlyjs='cdn', auto_play=False)
+ yield {'html': html}
+```
+
+1. It first performs an aggregation with a groupby to calculate the number of geo_tags of each US state.
+2. Then it invokes the Plotly library to create a treemap figure based on the aggregated dataset.
+3. Lastly, it converts the treemap figure object into an HTML string, by invoking the `to_html` function in the Plotly library, and yields it as the output.
+
+## **Convert the UDF into a Python Native Operator**
+
+Next we convert the `Treemap Visualizer` UDF into a native operator.
+As described in the[page for Java native operator](https://github.com/Texera/texera/wiki/Guide-to-Implement-a-Java-Native-Operator), a native operator requires the definitions of a descriptor (Desc), an executor (Exec), and a configuration (OpConfig). A Python native operator also requires these definitions, with some unique tweaks. We use the `Treemap Visualization` operator as an example to elaborate the differences:
+### Operator Descriptor (Desc)
+* Operator infomation
+
+Now, let's take a closer look at the `Treemap Visualizer` UDF.
+As shown in the following code block, the UDF contains 3 steps:
+```python
+from pytexera import *
+
+import plotly.express as px
+import plotly.io
+import plotly
+import numpy as np
+
+
+class ProcessTableOperator(UDFTableOperator):
+
+ @overrides
+ def process_table(self, table: Table, port: int) -> Iterator[Optional[TableLike]]:
+ table = table.groupby(['geo_tag.countyName','geo_tag.stateName']).size().reset_index(name='counts')
+ #print(table)
+ fig = px.treemap(table, path=['geo_tag.stateName','geo_tag.countyName'], values='counts',
+ color='counts', hover_data=['geo_tag.countyName','geo_tag.stateName'],
+ color_continuous_scale='RdBu',
+ color_continuous_midpoint=np.average(table['counts'], weights=table['counts']))
+ fig.update_layout(margin=dict(t=50, l=25, r=25, b=25))
+ html = plotly.io.to_html(fig, include_plotlyjs='cdn', auto_play=False)
+ yield {'html': html}
+```
+
+1. It first performs an aggregation with a groupby to calculate the number of geo_tags of each US state.
+2. Then it invokes the Plotly library to create a treemap figure based on the aggregated dataset.
+3. Lastly, it converts the treemap figure object into an HTML string, by invoking the `to_html` function in the Plotly library, and yields it as the output.
+
+## **Convert the UDF into a Python Native Operator**
+
+Next we convert the `Treemap Visualizer` UDF into a native operator.
+As described in the[page for Java native operator](https://github.com/Texera/texera/wiki/Guide-to-Implement-a-Java-Native-Operator), a native operator requires the definitions of a descriptor (Desc), an executor (Exec), and a configuration (OpConfig). A Python native operator also requires these definitions, with some unique tweaks. We use the `Treemap Visualization` operator as an example to elaborate the differences:
+### Operator Descriptor (Desc)
+* Operator infomation
+ The operator information is the same as a Java native operator, which contains the name, description, group, input port, and output port information.
+* Extending interface
+ Instead of implementing the `OperatorDescriptor` interface, a Python native operator implements the `PythonOperatorDescriptor` interface with overriding the `generatePythonCode` method. Our example is a `VisualizationOperator`, and we need to extend it as well.
+* Python content
+ The `generatePythonCode` method returns the actual Python code as a string, as shown below:
+
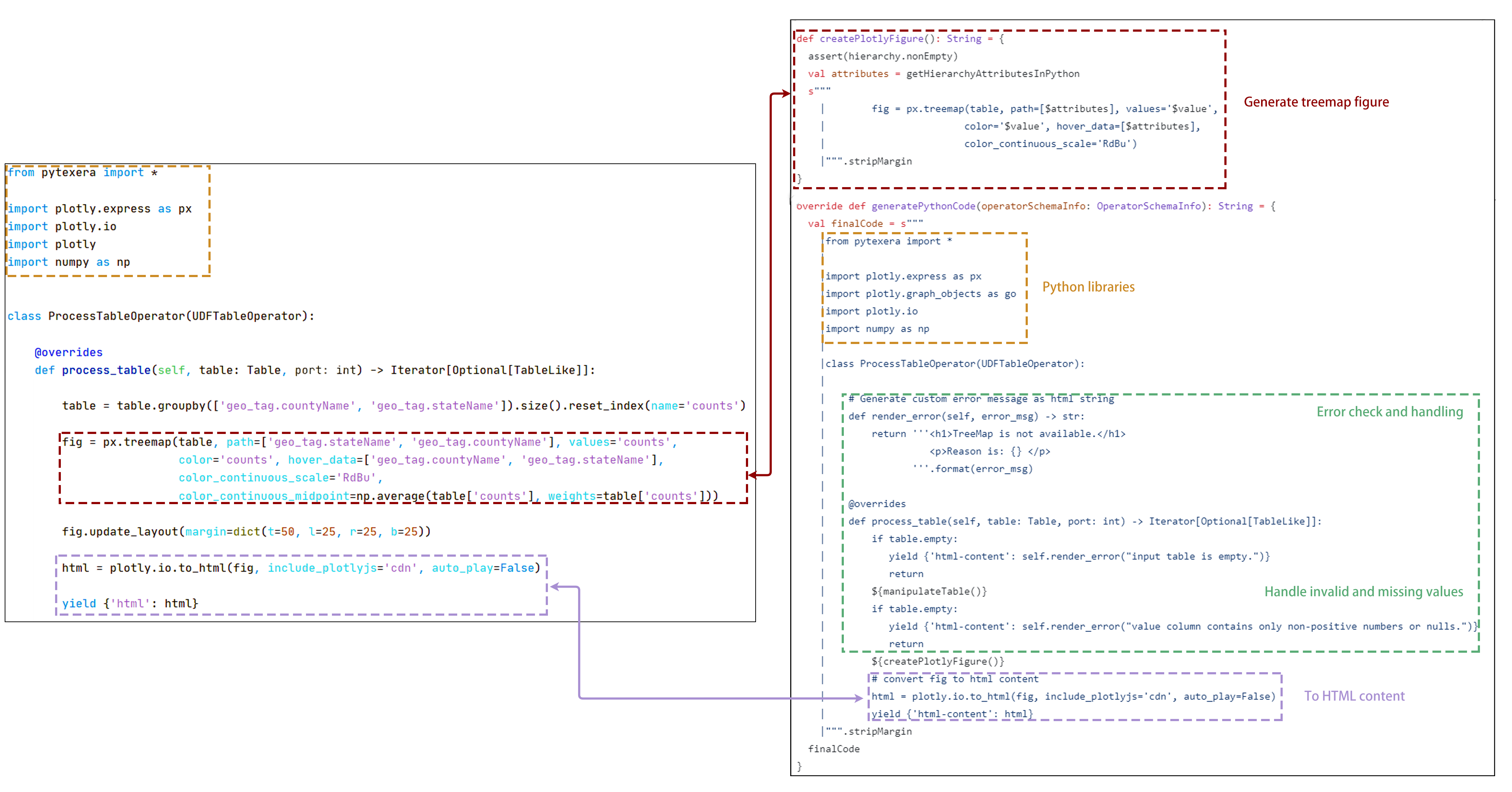
+ 
+
+ Now, let's compare the code in the PythonUDF with what we write in the descriptor. As we can see, both are responsible for generating the treemap figure and converting it into an HTML page. Additionally, we've included null-value handling and error alerts to make the operator more comprehensive.
+* Output schema
+ The Python UDF needs to define the output Schema in the property editor, while for native operators the output Schema is defined by implementing `getOutputSchema`. To do so, we use a Schema builder and add the output schema with the attribute name “html-content”.
+ ```python
+ override def getOutputSchema(schemas: Array[Schema]): Schema = {
+ Schema.newBuilder.add(new Attribute("html-content", AttributeType.STRING)).build
+ }
+ ```
+* Chart type
+ Since this operator is a visualization operator, we need to register its chart type as a `HTML_VIZ`.
+ ```python
+ override def chartType(): String = VisualizationConstants.HTML_VIZ
+ ```
+### Executor (Exec)
+In all Python native operators, the executor is simply the `PythonUDFExecutor`.
+### Operator Configuration
+In a Python native operator, it shares the same configuration as a Java native operator.
+### Registration
+It has the same process as a Java native operator.
+
+## **Test**
+
+After following all the steps above, you should be able to drag and drop the operator into the canvas. During the execution, the operator will output the expected result.
diff --git a/texera.wiki/Guide-to-Use-a-Python-UDF.md b/texera.wiki/Guide-to-Use-a-Python-UDF.md
new file mode 100644
index 00000000000..8252a94af36
--- /dev/null
+++ b/texera.wiki/Guide-to-Use-a-Python-UDF.md
@@ -0,0 +1,159 @@
+## What is Python UDF
+User-defined Functions (UDFs) provide a means to incorporate custom logic into Texera. Texera offers comprehensive Python UDF APIs, enabling users to accomplish various tasks. This guide will delve into the usage of UDFs, breaking down the process step by step.
+
+
+***
+
+
+## UDF UI and Editor
+
+
+The UDF operator offers the following interface, requiring the user to provide the following inputs: `Python code`, `worker count`, and `output schema`.
+
+
+ +
+
+
+-  Users can click on the "Edit code content" button to open the UDF code editor, where they can enter their custom Python code to define the desired operator.
+
+-
Users can click on the "Edit code content" button to open the UDF code editor, where they can enter their custom Python code to define the desired operator.
+
+-  Users have the flexibility to adjust the parallelism of the UDF operator by modifying the number of workers. The engine will then create the corresponding number of workers to execute the same operator in parallel.
+
+-
Users have the flexibility to adjust the parallelism of the UDF operator by modifying the number of workers. The engine will then create the corresponding number of workers to execute the same operator in parallel.
+
+-  Users need to provide the output schema of the UDF operator, which describes the output data's fields.
+ - The option `Retain input columns` allows users to include the input schema as the foundation for the output schema.
+ - The `Extra output column(s)` list allows users to define additional fields that should be included in the output schema.
+
+
Users need to provide the output schema of the UDF operator, which describes the output data's fields.
+ - The option `Retain input columns` allows users to include the input schema as the foundation for the output schema.
+ - The `Extra output column(s)` list allows users to define additional fields that should be included in the output schema.
+
+
+
+
+
+-  _Optionally_, users can click on the pencil icon located next to the operator name to make modifications to the name of the operator.
+
+
+***
+
+## Operator Definition
+
+### Iterator-based operator
+In Texera, all operators are implemented as iterators, including Python UDFs.
+Concepturally, a defined operator is executed as:
+
+```python
+operator = UDF() # initialize a UDF operator
+
+... # some other initialization logic
+
+# the main process loop
+while input_stream.has_more():
+ input_data = next_data()
+ output_iterator = operator.process(input_data)
+ for output_data in output_iterator:
+ send(output_data)
+
+... # some cleanup logic
+
+```
+
+### Operator Life Cycle
+The complete life cycle of a UDF operator consists of the following APIs:
+1. `open() -> None` Open a context of the operator. Usually it can be used for loading/initiating some resources, such as a file, a model, or an API client. It will be invoked once per operator.
+2. `process(data, port: int) -> Iterator[Optional[data]]` Process an input data from the given port, returning an iterator of optional data as output. It will be invoked once for every unit of data.
+3. `on_finish(port: int) -> Iterator[Optional[data]]` Callback when one input port is exhausted, returning an iterator of optional data as output. It will be invoked once per port.
+4. `close() -> None` Close the context of the operator. It will be invoked once per operator.
+
+
+### Process Data APIs
+There are three APIs to process the data in different units.
+
+1. Tuple API.
+
+```python
+
+class ProcessTupleOperator(UDFOperatorV2):
+
+ def process_tuple(self, tuple_: Tuple, port: int) -> Iterator[Optional[TupleLike]]:
+ yield tuple_
+
+```
+Tuple API takes one input tuple from a port at a time. It returns an iterator of optional `TupleLike` instances. A `TupleLike` is any data structure that supports key-value pairs, such as `pytexera.Tuple`, `dict`, `defaultdict`, `NamedTuple`, etc.
+
+Tuple API is useful for implementing functional operations which are applied to tuples one by one, such as map, reduce, and filter.
+
+2. Table API.
+```python
+
+class ProcessTableOperator(UDFTableOperator):
+
+ def process_table(self, table: Table, port: int) -> Iterator[Optional[TableLike]]:
+ yield table
+```
+Table API consumes a `Table` at a time, which consists of all the tuples from a port. It returns an iterator of optional `TableLike` instances. A `TableLike ` is a collection of `TupleLike`, and currently, we support `pytexera.Table` and `pandas.DataFrame` as a `TableLike` instance. More flexible types will be supported down the road.
+
+Table API is useful for implementing blocking operations that will consume all the data from one port, such as join, sort, and machine learning training.
+
+3. Batch API.
+```python
+
+class ProcessBatchOperator(UDFBatchOperator):
+
+ BATCH_SIZE = 10
+
+ def process_batch(self, batch: Batch, port: int) -> Iterator[Optional[BatchLike]]:
+ yield batch
+```
+Batch API consumes a batch of tuples at a time. Similar to `Table`, a `Batch` is also a collection of `Tuple`s; however, its size is defined by the `BATCH_SIZE`, and one port can have multiple batches. It returns an iterator of optional `BatchLike` instances. A `BatchLike ` is a collection of `TupleLike`, and currently, we support `pytexera.Batch` and `pandas.DataFrame` as a `BatchLike` instance. More flexible types will be supported down the road.
+
+The Batch API serves as a hybrid API combining the features of both the Tuple and Table APIs. It is particularly valuable for striking a balance between time and space considerations, offering a trade-off that optimizes efficiency.
+
+_All three APIs can return an empty iterator by `yield None`._
+
+### Schemas
+
+A UDF has an input Schema and an output Schema. The input schema is determined by the upstream operator's output schema and the engine will make sure the input data (tuple, table, or batch) matches the input schema. On the other hand, users are required to define the output schema of the UDF, and it is the user's responsibility to make sure the data output from the UDF matches the defined output schema.
+
+### Ports
+
+- Input ports:
+A UDF can take zero, one or multiple input ports, different ports can have different input schemas. Each port can take in multiple links, as long as they share the same schema.
+
+- Output ports:
+Currently, a UDF can only have exactly one output port. This means it cannot be used as a terminal operator (i.e., operator without output ports), or have more than one output port.
+
+#### 1-out UDF
+
+This UDF has zero input port and one output port. It is considered as a source operator (operator that produces data without an upstream). It has a special API:
+```python
+
+class GenerateOperator(UDFSourceOperator):
+
+ @overrides
+ def produce(self) -> Iterator[Union[TupleLike, TableLike, None]]:
+ yield
+```
+
+This `produce()` API returns an iterator of `TupleLike`, `TableLike`, or simply `None`.
+
+See [Generator Operator](https://github.com/Texera/texera/blob/master/core/amber/src/main/python/pytexera/udf/examples/generator_operator.py) for an example of 1-out UDF.
+
+
+#### 2-in UDF
+
+This UDF has two input ports, namely `model` port and `tuples` port. The `tuples` port depends on the `model` port, which means that during the execution, the `model` port will execute first, and the `tuples` port will start after the `model` port consumes all its input data.
+This dependency is particularly useful to implement machine learning inference operators, where a machine learning model is sent into the 2-in UDF through the `model` port, and becomes an operator state, then the tuples are coming in through the `tuples` port to be processed by the model.
+
+An example of 2-in UDF:
+```
+class SVMClassifier(UDFOperatorV2):
+
+
+ @overrides
+ def process_tuple(self, tuple_: Tuple, port: int) -> Iterator[Optional[TupleLike]]:
+
+ if port == 0: # models port
+ self.model = tuple_['model']
+
+ else: # tuples port
+ tuple_['pred'] = self.model.predict(tuple_['text'])
+ yield tuple_
+```
+
+_Currently, in 2-in UDF, "Retain input columns" will retain only the `tuples` port's input schema._
\ No newline at end of file
diff --git "a/texera.wiki/Guide-to-enable-the-LLM\342\200\220based-Texera-copilot.md" "b/texera.wiki/Guide-to-enable-the-LLM\342\200\220based-Texera-copilot.md"
new file mode 100644
index 00000000000..78cc69d9802
--- /dev/null
+++ "b/texera.wiki/Guide-to-enable-the-LLM\342\200\220based-Texera-copilot.md"
@@ -0,0 +1,91 @@
+This guide explains how to enable the AI Copilot feature in Texera. For detailed explanation about this feature, see https://github.com/apache/texera/pull/4020.
+
+## Prerequisites
+- Already know how to setup Texera
+- Python 3.10+
+- API key from a supported LLM provider (e.g., Anthropic, OpenAI)
+
+## Step 1: Install LiteLLM
+
+Run command:
+```bash
+pip install 'litellm[proxy]'
+```
+
+## Step 2: Configure API Keys
+
+Set your LLM provider API key as an environment variable:
+
+**For Anthropic (Claude):**
+```bash
+export ANTHROPIC_API_KEY=
+```
+
+**For OpenAI:**
+```bash
+export OPENAI_API_KEY=
+```
+
+> You can set multiple API keys if you want to use models from different providers.
+
+## Step 3: Start LiteLLM Service
+
+Start the LiteLLM proxy using the provided configuration:
+
+```bash
+litellm --config bin/litellm-config.yaml
+```
+
+By default, LiteLLM runs on `http://0.0.0.0:4000`.
+
+> To customize available models, edit `bin/litellm-config.yaml`. See [LiteLLM documentation](https://docs.litellm.ai/docs/proxy/quick_start) for more options. Also see [LiteLLM Model Configuration](https://docs.litellm.ai/docs/providers) for supported providers and model formats.
+
+## Step 4: Enable Copilot in Configuration
+
+Modify `common/config/src/main/resources/gui.conf` to enable the copilot feature:
+
+```diff
+ gui {
+ workflow-workspace {
+ # ... other settings ...
+
+ # whether AI copilot feature is enabled
+- copilot-enabled = false
++ copilot-enabled = true
+ }
+ }
+```
+
+## Step 5: Configure LiteLLM Connection (Optional)
+
+The `AccessControlService` acts as a gateway between the frontend and LiteLLM. If LiteLLM is running on a different host or port, modify `common/config/src/main/resources/llm.conf`:
+
+```diff
+ llm {
+ # Base URL for LiteLLM service
+- base-url = "http://0.0.0.0:4000"
++ base-url = "http://your-litellm-host:4000"
+
+ # Master key for LiteLLM authentication
+- master-key = ""
++ master-key = "your-master-key"
+ }
+```
+
+Alternatively, set environment variables:
+
+```bash
+export LITELLM_BASE_URL=http://your-litellm-host:4000
+export LITELLM_MASTER_KEY=your-master-key
+```
+
+## Step 6: Start Texera Services
+
+Start the **all** Texera micro services, including the `AccessControlService`.
+
+## Done!
+
+After opening any workflow, you should now see a robot icon at the bottom right. Click on it will expand a panel with all the available models:
+
+
+
diff --git a/texera.wiki/Home.md b/texera.wiki/Home.md
new file mode 100644
index 00000000000..c76e3fe6ab0
--- /dev/null
+++ b/texera.wiki/Home.md
@@ -0,0 +1,41 @@
+
+# Getting Started
+
+
+* For users, visit [Step 0 - Guide to Use Texera](https://github.com/Texera/texera/wiki/Guide-for-how-to-use-Texera).
+* For developers, visit [Step 1 - Guide to Develop Texera](https://github.com/Texera/texera/wiki/Guide-for-Developers).
+
+***
+
+# Implementing an Operator
+Texera supports operators in Java and Python natively. Additionally, Python operators can be implemented as a Python UDF for a quick extension.
+* [Step 2 - Guide to Implement a Java Native Operator](https://github.com/Texera/texera/wiki/Guide-to-Implement-a-Java-Native-Operator)
+* [Step 3 - Guide to Use a Python UDF](https://github.com/Texera/texera/wiki/Guide-to-Use-a-Python-UDF)
+* [Step 4 - Guide to Implement a Python Native Operator (converting from a Python UDF)](https://github.com/Texera/texera/wiki/Guide-to-Implement-a-Python-Native-Operator-(converting-from-a-Python-UDF))
+
+***
+# Contributing to the Project
+## 1. Create an Issue for Any Proposed Change
+To track any proposed changes to the codebase, developers should first create a corresponding issue. While we often have offline discussions, any such conversation that involves proposed code changes should be summarized and added to the relevant issue. Developers are free to use their preferred tools to create diagrams or documents, but the final outputs should be attached to the issue.
+
+## 2. Include Final Design in the Pull Request (PR) Description
+
+[Step 5 - Guide to Raise a Pull Request (PR)](https://github.com/Texera/texera/blob/master/CONTRIBUTING.md)
+
+If a design document exists for a particular feature or change, it should be included or summarized in the PR description. This ensures the context and rationale for changes are clearly visible during the review process.
+
+## 3. Store User-Facing Documentation in the docs Folder
+
+Any documentation intended to help users understand or use the system should be added to the docs folder in the main repository.
+
+## 4. Review Process and Merging Guidelines
+
+Reviewers are responsible for ensuring that each PR aligns with the design discussed in the associated issue. Any contributor can serve as a reviewer. However, only a committer can merge a PR. While a committer doesn’t have to review every PR personally, they must verify that the PR adheres to the Code Contribution Process before merging.
+
+## 5. Sync Discussions Across Channels
+
+All development-related discussions from the Texera Slack #dev channel and Texera GitHub repo should be synced to this dev mailing list to ensure transparency and continuity.
+
+***
+# Available Visualization Operator tasks
+* Plotly, a Python graphing library, has a list of basic charts, which can be found at [Plotly Python Open Source Graphing Library Basic Charts](https://plotly.com/python/basic-charts/). By following the 6 steps, you should have enough information about implementing a new Python Native Operator and raise a PR successfully. Currently, we implemented several visualization operators for the them: Scatter Plots, Line Charts, Bar Charts (Horizontal as well), Pie Charts, Bubble Charts, Dots Plots, Filled Area Plots, Gantt Chart, Hierarchy Chart (TreeMap and Sunburst). To check the latest implemented operators, please refers to [this link](https://github.com/apache/texera/tree/main/common/workflow-operator/src/main/scala/org/apache/texera/amber/operator/visualization) that contains all the existing visualization operators.
diff --git a/texera.wiki/How-to-run-Texera-on-local-Kubernetes.md b/texera.wiki/How-to-run-Texera-on-local-Kubernetes.md
new file mode 100644
index 00000000000..513a973fca4
--- /dev/null
+++ b/texera.wiki/How-to-run-Texera-on-local-Kubernetes.md
@@ -0,0 +1,132 @@
+This document explains how to run Texera on Kubernetes locally for development purposes.
+
+---
+
+## 1. Prerequisites
+
+Before you begin, you will need a local Kubernetes cluster manager. We use **Minikube** in this instruction.
+
+1. [Install Minikube](https://minikube.sigs.k8s.io/docs/start/).
+2. Start your cluster:
+ ```bash
+ minikube start
+ ```
+3. Verify that your node is running. You should see `minikube` in your node list when you run:
+ ```bash
+ kubectl get nodes
+ ```
+4. [Install Helm](https://helm.sh/docs/intro/install/).
+5. Install local path plugin:
+ ```bash
+ kubectl apply -f https://raw.githubusercontent.com/rancher/local-path-provisioner/master/deploy/local-path-storage.yaml
+ ```
+---
+
+## 2. Install Texera using Helm
+
+All the necessary Kubernetes files are located in the `bin/k8s` directory of this repository.
+
+1. Navigate to the `bin` directory:
+ ```bash
+ cd bin
+ ```
+2. Install the Texera Helm chart. This command will install all Texera services into a new `texera-dev` namespace.
+ ```bash
+ helm install texera k8s --namespace texera-dev --create-namespace
+ ```
+
+> **Note:** If you get an error about missing Helm dependencies, navigate to the `k8s` directory and run the dependency update command, then try the installation again:
+>
+> ```bash
+> cd k8s
+> helm dependency update
+> cd ..
+> helm install texera k8s --namespace texera-dev --create-namespace
+> ```
+
+---
+
+## 3. Verify the Installation
+
+Wait for the required deployments to be in the `Running` state. You can check their status by running:
+
+```bash
+kubectl get deployments -n texera-dev
+````
+
+The key deployments required to run Texera are:
+
+ * `texera-webserver`
+ * `texera-file-service`
+ * `texera-workflow-computing-unit-manager`
+
+-----
+
+## 4\. Accessing the Texera UI
+
+Once the deployments are running, you can access the Texera web interface.
+
+1. **Port-Forwarding (If Required)**
+
+ By default, the UI should be available at **http://localhost:30080**.
+
+ If you get a "connection refused" error, you may need to manually forward the ingress port. Open a new terminal and run:
+
+ ```bash
+ kubectl port-forward -n texera-dev service/texera-ingress-nginx-controller 30080:80
+ ```
+
+2. **Login**
+
+ Open http://localhost:30080 in your browser and log in using the default username and password.
+
+-----
+
+## 5\. Troubleshooting
+
+### File Upload Error
+
+If you see an error when trying to upload a file to a dataset, you may need to forward the port for MinIO (our file storage service).
+
+Run the following command in a new terminal:
+
+```bash
+kubectl port-forward -n texera-dev service/texera-minio 31000:9000
+```
+
+This maps the service's port `9000` to your local port `31000`.
+
+### Using Custom-Built Images
+
+To test custom changes, you can update the `bin/k8s/values.yaml` file to use your own Docker images. After modifying the `values.yaml` file, upgrade the Helm release to apply the changes:
+
+```bash
+helm upgrade texera k8s --namespace texera-dev
+```
+
+
+## 6. Security Recommendation
+For any deployment, especially in production, it's crucial to apply the principle of least privilege to limit potential damage from a security vulnerability. While the OS user deploying the chart needs kubectl and helm permissions, a more critical concern is the user running the application inside the containers.
+
+### Run Containers as a Non-Root User
+By default, many container images run as the root user. If an attacker exploits a vulnerability in an application (like the running code on computing unit), they would gain root privileges within the container, giving them full control to access or modify its contents and potentially attack other services.
+
+To prevent this, you should configure the Kubernetes deployments to run the processes as a specific, unprivileged user.
+
+The following is a sample template you can use:
+```yaml
+spec:
+ template:
+ spec:
+ securityContext:
+ # Run as a non-root user (e.g., user 1001)
+ runAsUser: 1001
+ runAsGroup: 1001
+ # Enforce that the container cannot run as root
+ runAsNonRoot: true
+ # Make the root filesystem read-only
+ readOnlyRootFilesystem: true
+ containers:
+ - name: texera-webserver
+ image: ...
+```
\ No newline at end of file
diff --git a/texera.wiki/Install-Texera.md b/texera.wiki/Install-Texera.md
new file mode 100644
index 00000000000..04e7ac49942
--- /dev/null
+++ b/texera.wiki/Install-Texera.md
@@ -0,0 +1,5 @@
+To install Texera, you may choose one of the two supported architectures depending on your needs:
+
+- **Single Node Deployment**: ideal for quickly starting Texera on a local machine or testing deployments serving a small number of users. See [Installing Texera on a Single Node](https://github.com/Texera/texera/wiki/Installing-Texera-on-a-Single-Node).
+
+- **Kubernetes-based Deployment**: recommended for production-level deployments at scale, supporting high availability serving a larger number of users. See [Installing Texera on a Kubernetes Cluster](https://github.com/Texera/texera/wiki/Installing-Texera-on-a-Kubernetes-Cluster).
\ No newline at end of file
diff --git a/texera.wiki/Installing-Apache-Texera-using-Docker.md b/texera.wiki/Installing-Apache-Texera-using-Docker.md
new file mode 100644
index 00000000000..a36b0cb6a26
--- /dev/null
+++ b/texera.wiki/Installing-Apache-Texera-using-Docker.md
@@ -0,0 +1,177 @@
+This document describes how to set up and run Texera on a single machine using "Docker Compose".
+
+## Prerequisites
+
+Before starting, make sure your computer meets the following requirements:
+
+| Resource Type | Minimum | Recommended |
+|-------------|---------|-------------|
+| CPU Cores | 2 | 8 |
+| Memory | 4GB | 16GB |
+| Disk Space | 20GB | 50GB |
+
+You also need to install and launch Docker Desktop on your computer. Choose the right installation link for your computer:
+
+| Operating System | Installation Link |
+|-----------------|-------------------|
+| macOS | [Docker Desktop for Mac](https://docs.docker.com/desktop/install/mac-install/) |
+| Windows | [Docker Desktop for Windows](https://docs.docker.com/desktop/install/windows-install/) |
+| Linux | [Docker Desktop for Linux](https://docs.docker.com/desktop/install/linux-install/) |
+
+After installing and launching Docker Desktop, verify that Docker and Docker Compose are available by running the following commands from the command line:
+```bash
+docker --version
+docker compose version
+```
+You should see output messages like the following (your versions may be different):
+```
+$ docker --version
+Docker version 27.5.1, build 9f9e405
+$ docker compose version
+Docker Compose version v2.23.0-desktop.1
+```
+
+
+By default, Texera services require ports **8080** and **9000** to be free. If either port is already in use, the services will fail to start.
+
+On macOS or Linux, run the following commands to check:
+
+```
+lsof -i :8080
+lsof -i :9000
+```
+
+If either command produces output, that port is occupied by another process. You will need to either stop that process or change Texera's port configuration. See [Advanced Settings > Run Texera on other ports](#run-texera-on-other-ports) for instructions.
+
+---
+
+
+## Download the docker compose tarball from the release
+
+Download by clicking [here](https://dist.apache.org/repos/dist/dev/incubator/texera/1.1.0-incubating-RC4/apache-texera-1.1.0-incubating-docker-compose.tar.gz) and extract it.
+
+## Launch Texera
+
+Enter the extracted directory and run the following command to start Texera:
+```bash
+docker compose --profile examples up
+```
+
+This command will start docker containers that host the Texera services, and pre-create two example workflows and datasets.
+
+If you don't want to have these examples pre-created, run the following command instead:
+```bash
+docker compose up
+```
+
+> If you see the error message like `unable to get image 'nginx:alpine': Cannot connect to the Docker daemon at unix:///Users/kunwoopark/.docker/run/docker.sock. Is the docker daemon running?`, please make sure Docker Desktop is installed and running
+
+> When you start Texera for the first time, it will take around 5 minutes to download needed images.
+
+
+The system should be ready around 1.5 minutes. After seeing the following startup message:
+```
+...
+=========================================
+ Texera is starting up!
+ Access at: http://localhost:8080
+=========================================
+...
+```
+
+you can open the browser and navigate to the URL shown in the message.
+
+Input the default account `texera` with password `texera`, and then click on the `Sign In` button to login:
+
_Optionally_, users can click on the pencil icon located next to the operator name to make modifications to the name of the operator.
+
+
+***
+
+## Operator Definition
+
+### Iterator-based operator
+In Texera, all operators are implemented as iterators, including Python UDFs.
+Concepturally, a defined operator is executed as:
+
+```python
+operator = UDF() # initialize a UDF operator
+
+... # some other initialization logic
+
+# the main process loop
+while input_stream.has_more():
+ input_data = next_data()
+ output_iterator = operator.process(input_data)
+ for output_data in output_iterator:
+ send(output_data)
+
+... # some cleanup logic
+
+```
+
+### Operator Life Cycle
+The complete life cycle of a UDF operator consists of the following APIs:
+1. `open() -> None` Open a context of the operator. Usually it can be used for loading/initiating some resources, such as a file, a model, or an API client. It will be invoked once per operator.
+2. `process(data, port: int) -> Iterator[Optional[data]]` Process an input data from the given port, returning an iterator of optional data as output. It will be invoked once for every unit of data.
+3. `on_finish(port: int) -> Iterator[Optional[data]]` Callback when one input port is exhausted, returning an iterator of optional data as output. It will be invoked once per port.
+4. `close() -> None` Close the context of the operator. It will be invoked once per operator.
+
+
+### Process Data APIs
+There are three APIs to process the data in different units.
+
+1. Tuple API.
+
+```python
+
+class ProcessTupleOperator(UDFOperatorV2):
+
+ def process_tuple(self, tuple_: Tuple, port: int) -> Iterator[Optional[TupleLike]]:
+ yield tuple_
+
+```
+Tuple API takes one input tuple from a port at a time. It returns an iterator of optional `TupleLike` instances. A `TupleLike` is any data structure that supports key-value pairs, such as `pytexera.Tuple`, `dict`, `defaultdict`, `NamedTuple`, etc.
+
+Tuple API is useful for implementing functional operations which are applied to tuples one by one, such as map, reduce, and filter.
+
+2. Table API.
+```python
+
+class ProcessTableOperator(UDFTableOperator):
+
+ def process_table(self, table: Table, port: int) -> Iterator[Optional[TableLike]]:
+ yield table
+```
+Table API consumes a `Table` at a time, which consists of all the tuples from a port. It returns an iterator of optional `TableLike` instances. A `TableLike ` is a collection of `TupleLike`, and currently, we support `pytexera.Table` and `pandas.DataFrame` as a `TableLike` instance. More flexible types will be supported down the road.
+
+Table API is useful for implementing blocking operations that will consume all the data from one port, such as join, sort, and machine learning training.
+
+3. Batch API.
+```python
+
+class ProcessBatchOperator(UDFBatchOperator):
+
+ BATCH_SIZE = 10
+
+ def process_batch(self, batch: Batch, port: int) -> Iterator[Optional[BatchLike]]:
+ yield batch
+```
+Batch API consumes a batch of tuples at a time. Similar to `Table`, a `Batch` is also a collection of `Tuple`s; however, its size is defined by the `BATCH_SIZE`, and one port can have multiple batches. It returns an iterator of optional `BatchLike` instances. A `BatchLike ` is a collection of `TupleLike`, and currently, we support `pytexera.Batch` and `pandas.DataFrame` as a `BatchLike` instance. More flexible types will be supported down the road.
+
+The Batch API serves as a hybrid API combining the features of both the Tuple and Table APIs. It is particularly valuable for striking a balance between time and space considerations, offering a trade-off that optimizes efficiency.
+
+_All three APIs can return an empty iterator by `yield None`._
+
+### Schemas
+
+A UDF has an input Schema and an output Schema. The input schema is determined by the upstream operator's output schema and the engine will make sure the input data (tuple, table, or batch) matches the input schema. On the other hand, users are required to define the output schema of the UDF, and it is the user's responsibility to make sure the data output from the UDF matches the defined output schema.
+
+### Ports
+
+- Input ports:
+A UDF can take zero, one or multiple input ports, different ports can have different input schemas. Each port can take in multiple links, as long as they share the same schema.
+
+- Output ports:
+Currently, a UDF can only have exactly one output port. This means it cannot be used as a terminal operator (i.e., operator without output ports), or have more than one output port.
+
+#### 1-out UDF
+
+This UDF has zero input port and one output port. It is considered as a source operator (operator that produces data without an upstream). It has a special API:
+```python
+
+class GenerateOperator(UDFSourceOperator):
+
+ @overrides
+ def produce(self) -> Iterator[Union[TupleLike, TableLike, None]]:
+ yield
+```
+
+This `produce()` API returns an iterator of `TupleLike`, `TableLike`, or simply `None`.
+
+See [Generator Operator](https://github.com/Texera/texera/blob/master/core/amber/src/main/python/pytexera/udf/examples/generator_operator.py) for an example of 1-out UDF.
+
+
+#### 2-in UDF
+
+This UDF has two input ports, namely `model` port and `tuples` port. The `tuples` port depends on the `model` port, which means that during the execution, the `model` port will execute first, and the `tuples` port will start after the `model` port consumes all its input data.
+This dependency is particularly useful to implement machine learning inference operators, where a machine learning model is sent into the 2-in UDF through the `model` port, and becomes an operator state, then the tuples are coming in through the `tuples` port to be processed by the model.
+
+An example of 2-in UDF:
+```
+class SVMClassifier(UDFOperatorV2):
+
+
+ @overrides
+ def process_tuple(self, tuple_: Tuple, port: int) -> Iterator[Optional[TupleLike]]:
+
+ if port == 0: # models port
+ self.model = tuple_['model']
+
+ else: # tuples port
+ tuple_['pred'] = self.model.predict(tuple_['text'])
+ yield tuple_
+```
+
+_Currently, in 2-in UDF, "Retain input columns" will retain only the `tuples` port's input schema._
\ No newline at end of file
diff --git "a/texera.wiki/Guide-to-enable-the-LLM\342\200\220based-Texera-copilot.md" "b/texera.wiki/Guide-to-enable-the-LLM\342\200\220based-Texera-copilot.md"
new file mode 100644
index 00000000000..78cc69d9802
--- /dev/null
+++ "b/texera.wiki/Guide-to-enable-the-LLM\342\200\220based-Texera-copilot.md"
@@ -0,0 +1,91 @@
+This guide explains how to enable the AI Copilot feature in Texera. For detailed explanation about this feature, see https://github.com/apache/texera/pull/4020.
+
+## Prerequisites
+- Already know how to setup Texera
+- Python 3.10+
+- API key from a supported LLM provider (e.g., Anthropic, OpenAI)
+
+## Step 1: Install LiteLLM
+
+Run command:
+```bash
+pip install 'litellm[proxy]'
+```
+
+## Step 2: Configure API Keys
+
+Set your LLM provider API key as an environment variable:
+
+**For Anthropic (Claude):**
+```bash
+export ANTHROPIC_API_KEY=
+```
+
+**For OpenAI:**
+```bash
+export OPENAI_API_KEY=
+```
+
+> You can set multiple API keys if you want to use models from different providers.
+
+## Step 3: Start LiteLLM Service
+
+Start the LiteLLM proxy using the provided configuration:
+
+```bash
+litellm --config bin/litellm-config.yaml
+```
+
+By default, LiteLLM runs on `http://0.0.0.0:4000`.
+
+> To customize available models, edit `bin/litellm-config.yaml`. See [LiteLLM documentation](https://docs.litellm.ai/docs/proxy/quick_start) for more options. Also see [LiteLLM Model Configuration](https://docs.litellm.ai/docs/providers) for supported providers and model formats.
+
+## Step 4: Enable Copilot in Configuration
+
+Modify `common/config/src/main/resources/gui.conf` to enable the copilot feature:
+
+```diff
+ gui {
+ workflow-workspace {
+ # ... other settings ...
+
+ # whether AI copilot feature is enabled
+- copilot-enabled = false
++ copilot-enabled = true
+ }
+ }
+```
+
+## Step 5: Configure LiteLLM Connection (Optional)
+
+The `AccessControlService` acts as a gateway between the frontend and LiteLLM. If LiteLLM is running on a different host or port, modify `common/config/src/main/resources/llm.conf`:
+
+```diff
+ llm {
+ # Base URL for LiteLLM service
+- base-url = "http://0.0.0.0:4000"
++ base-url = "http://your-litellm-host:4000"
+
+ # Master key for LiteLLM authentication
+- master-key = ""
++ master-key = "your-master-key"
+ }
+```
+
+Alternatively, set environment variables:
+
+```bash
+export LITELLM_BASE_URL=http://your-litellm-host:4000
+export LITELLM_MASTER_KEY=your-master-key
+```
+
+## Step 6: Start Texera Services
+
+Start the **all** Texera micro services, including the `AccessControlService`.
+
+## Done!
+
+After opening any workflow, you should now see a robot icon at the bottom right. Click on it will expand a panel with all the available models:
+
+
+
diff --git a/texera.wiki/Home.md b/texera.wiki/Home.md
new file mode 100644
index 00000000000..c76e3fe6ab0
--- /dev/null
+++ b/texera.wiki/Home.md
@@ -0,0 +1,41 @@
+
+# Getting Started
+
+
+* For users, visit [Step 0 - Guide to Use Texera](https://github.com/Texera/texera/wiki/Guide-for-how-to-use-Texera).
+* For developers, visit [Step 1 - Guide to Develop Texera](https://github.com/Texera/texera/wiki/Guide-for-Developers).
+
+***
+
+# Implementing an Operator
+Texera supports operators in Java and Python natively. Additionally, Python operators can be implemented as a Python UDF for a quick extension.
+* [Step 2 - Guide to Implement a Java Native Operator](https://github.com/Texera/texera/wiki/Guide-to-Implement-a-Java-Native-Operator)
+* [Step 3 - Guide to Use a Python UDF](https://github.com/Texera/texera/wiki/Guide-to-Use-a-Python-UDF)
+* [Step 4 - Guide to Implement a Python Native Operator (converting from a Python UDF)](https://github.com/Texera/texera/wiki/Guide-to-Implement-a-Python-Native-Operator-(converting-from-a-Python-UDF))
+
+***
+# Contributing to the Project
+## 1. Create an Issue for Any Proposed Change
+To track any proposed changes to the codebase, developers should first create a corresponding issue. While we often have offline discussions, any such conversation that involves proposed code changes should be summarized and added to the relevant issue. Developers are free to use their preferred tools to create diagrams or documents, but the final outputs should be attached to the issue.
+
+## 2. Include Final Design in the Pull Request (PR) Description
+
+[Step 5 - Guide to Raise a Pull Request (PR)](https://github.com/Texera/texera/blob/master/CONTRIBUTING.md)
+
+If a design document exists for a particular feature or change, it should be included or summarized in the PR description. This ensures the context and rationale for changes are clearly visible during the review process.
+
+## 3. Store User-Facing Documentation in the docs Folder
+
+Any documentation intended to help users understand or use the system should be added to the docs folder in the main repository.
+
+## 4. Review Process and Merging Guidelines
+
+Reviewers are responsible for ensuring that each PR aligns with the design discussed in the associated issue. Any contributor can serve as a reviewer. However, only a committer can merge a PR. While a committer doesn’t have to review every PR personally, they must verify that the PR adheres to the Code Contribution Process before merging.
+
+## 5. Sync Discussions Across Channels
+
+All development-related discussions from the Texera Slack #dev channel and Texera GitHub repo should be synced to this dev mailing list to ensure transparency and continuity.
+
+***
+# Available Visualization Operator tasks
+* Plotly, a Python graphing library, has a list of basic charts, which can be found at [Plotly Python Open Source Graphing Library Basic Charts](https://plotly.com/python/basic-charts/). By following the 6 steps, you should have enough information about implementing a new Python Native Operator and raise a PR successfully. Currently, we implemented several visualization operators for the them: Scatter Plots, Line Charts, Bar Charts (Horizontal as well), Pie Charts, Bubble Charts, Dots Plots, Filled Area Plots, Gantt Chart, Hierarchy Chart (TreeMap and Sunburst). To check the latest implemented operators, please refers to [this link](https://github.com/apache/texera/tree/main/common/workflow-operator/src/main/scala/org/apache/texera/amber/operator/visualization) that contains all the existing visualization operators.
diff --git a/texera.wiki/How-to-run-Texera-on-local-Kubernetes.md b/texera.wiki/How-to-run-Texera-on-local-Kubernetes.md
new file mode 100644
index 00000000000..513a973fca4
--- /dev/null
+++ b/texera.wiki/How-to-run-Texera-on-local-Kubernetes.md
@@ -0,0 +1,132 @@
+This document explains how to run Texera on Kubernetes locally for development purposes.
+
+---
+
+## 1. Prerequisites
+
+Before you begin, you will need a local Kubernetes cluster manager. We use **Minikube** in this instruction.
+
+1. [Install Minikube](https://minikube.sigs.k8s.io/docs/start/).
+2. Start your cluster:
+ ```bash
+ minikube start
+ ```
+3. Verify that your node is running. You should see `minikube` in your node list when you run:
+ ```bash
+ kubectl get nodes
+ ```
+4. [Install Helm](https://helm.sh/docs/intro/install/).
+5. Install local path plugin:
+ ```bash
+ kubectl apply -f https://raw.githubusercontent.com/rancher/local-path-provisioner/master/deploy/local-path-storage.yaml
+ ```
+---
+
+## 2. Install Texera using Helm
+
+All the necessary Kubernetes files are located in the `bin/k8s` directory of this repository.
+
+1. Navigate to the `bin` directory:
+ ```bash
+ cd bin
+ ```
+2. Install the Texera Helm chart. This command will install all Texera services into a new `texera-dev` namespace.
+ ```bash
+ helm install texera k8s --namespace texera-dev --create-namespace
+ ```
+
+> **Note:** If you get an error about missing Helm dependencies, navigate to the `k8s` directory and run the dependency update command, then try the installation again:
+>
+> ```bash
+> cd k8s
+> helm dependency update
+> cd ..
+> helm install texera k8s --namespace texera-dev --create-namespace
+> ```
+
+---
+
+## 3. Verify the Installation
+
+Wait for the required deployments to be in the `Running` state. You can check their status by running:
+
+```bash
+kubectl get deployments -n texera-dev
+````
+
+The key deployments required to run Texera are:
+
+ * `texera-webserver`
+ * `texera-file-service`
+ * `texera-workflow-computing-unit-manager`
+
+-----
+
+## 4\. Accessing the Texera UI
+
+Once the deployments are running, you can access the Texera web interface.
+
+1. **Port-Forwarding (If Required)**
+
+ By default, the UI should be available at **http://localhost:30080**.
+
+ If you get a "connection refused" error, you may need to manually forward the ingress port. Open a new terminal and run:
+
+ ```bash
+ kubectl port-forward -n texera-dev service/texera-ingress-nginx-controller 30080:80
+ ```
+
+2. **Login**
+
+ Open http://localhost:30080 in your browser and log in using the default username and password.
+
+-----
+
+## 5\. Troubleshooting
+
+### File Upload Error
+
+If you see an error when trying to upload a file to a dataset, you may need to forward the port for MinIO (our file storage service).
+
+Run the following command in a new terminal:
+
+```bash
+kubectl port-forward -n texera-dev service/texera-minio 31000:9000
+```
+
+This maps the service's port `9000` to your local port `31000`.
+
+### Using Custom-Built Images
+
+To test custom changes, you can update the `bin/k8s/values.yaml` file to use your own Docker images. After modifying the `values.yaml` file, upgrade the Helm release to apply the changes:
+
+```bash
+helm upgrade texera k8s --namespace texera-dev
+```
+
+
+## 6. Security Recommendation
+For any deployment, especially in production, it's crucial to apply the principle of least privilege to limit potential damage from a security vulnerability. While the OS user deploying the chart needs kubectl and helm permissions, a more critical concern is the user running the application inside the containers.
+
+### Run Containers as a Non-Root User
+By default, many container images run as the root user. If an attacker exploits a vulnerability in an application (like the running code on computing unit), they would gain root privileges within the container, giving them full control to access or modify its contents and potentially attack other services.
+
+To prevent this, you should configure the Kubernetes deployments to run the processes as a specific, unprivileged user.
+
+The following is a sample template you can use:
+```yaml
+spec:
+ template:
+ spec:
+ securityContext:
+ # Run as a non-root user (e.g., user 1001)
+ runAsUser: 1001
+ runAsGroup: 1001
+ # Enforce that the container cannot run as root
+ runAsNonRoot: true
+ # Make the root filesystem read-only
+ readOnlyRootFilesystem: true
+ containers:
+ - name: texera-webserver
+ image: ...
+```
\ No newline at end of file
diff --git a/texera.wiki/Install-Texera.md b/texera.wiki/Install-Texera.md
new file mode 100644
index 00000000000..04e7ac49942
--- /dev/null
+++ b/texera.wiki/Install-Texera.md
@@ -0,0 +1,5 @@
+To install Texera, you may choose one of the two supported architectures depending on your needs:
+
+- **Single Node Deployment**: ideal for quickly starting Texera on a local machine or testing deployments serving a small number of users. See [Installing Texera on a Single Node](https://github.com/Texera/texera/wiki/Installing-Texera-on-a-Single-Node).
+
+- **Kubernetes-based Deployment**: recommended for production-level deployments at scale, supporting high availability serving a larger number of users. See [Installing Texera on a Kubernetes Cluster](https://github.com/Texera/texera/wiki/Installing-Texera-on-a-Kubernetes-Cluster).
\ No newline at end of file
diff --git a/texera.wiki/Installing-Apache-Texera-using-Docker.md b/texera.wiki/Installing-Apache-Texera-using-Docker.md
new file mode 100644
index 00000000000..a36b0cb6a26
--- /dev/null
+++ b/texera.wiki/Installing-Apache-Texera-using-Docker.md
@@ -0,0 +1,177 @@
+This document describes how to set up and run Texera on a single machine using "Docker Compose".
+
+## Prerequisites
+
+Before starting, make sure your computer meets the following requirements:
+
+| Resource Type | Minimum | Recommended |
+|-------------|---------|-------------|
+| CPU Cores | 2 | 8 |
+| Memory | 4GB | 16GB |
+| Disk Space | 20GB | 50GB |
+
+You also need to install and launch Docker Desktop on your computer. Choose the right installation link for your computer:
+
+| Operating System | Installation Link |
+|-----------------|-------------------|
+| macOS | [Docker Desktop for Mac](https://docs.docker.com/desktop/install/mac-install/) |
+| Windows | [Docker Desktop for Windows](https://docs.docker.com/desktop/install/windows-install/) |
+| Linux | [Docker Desktop for Linux](https://docs.docker.com/desktop/install/linux-install/) |
+
+After installing and launching Docker Desktop, verify that Docker and Docker Compose are available by running the following commands from the command line:
+```bash
+docker --version
+docker compose version
+```
+You should see output messages like the following (your versions may be different):
+```
+$ docker --version
+Docker version 27.5.1, build 9f9e405
+$ docker compose version
+Docker Compose version v2.23.0-desktop.1
+```
+
+
+By default, Texera services require ports **8080** and **9000** to be free. If either port is already in use, the services will fail to start.
+
+On macOS or Linux, run the following commands to check:
+
+```
+lsof -i :8080
+lsof -i :9000
+```
+
+If either command produces output, that port is occupied by another process. You will need to either stop that process or change Texera's port configuration. See [Advanced Settings > Run Texera on other ports](#run-texera-on-other-ports) for instructions.
+
+---
+
+
+## Download the docker compose tarball from the release
+
+Download by clicking [here](https://dist.apache.org/repos/dist/dev/incubator/texera/1.1.0-incubating-RC4/apache-texera-1.1.0-incubating-docker-compose.tar.gz) and extract it.
+
+## Launch Texera
+
+Enter the extracted directory and run the following command to start Texera:
+```bash
+docker compose --profile examples up
+```
+
+This command will start docker containers that host the Texera services, and pre-create two example workflows and datasets.
+
+If you don't want to have these examples pre-created, run the following command instead:
+```bash
+docker compose up
+```
+
+> If you see the error message like `unable to get image 'nginx:alpine': Cannot connect to the Docker daemon at unix:///Users/kunwoopark/.docker/run/docker.sock. Is the docker daemon running?`, please make sure Docker Desktop is installed and running
+
+> When you start Texera for the first time, it will take around 5 minutes to download needed images.
+
+
+The system should be ready around 1.5 minutes. After seeing the following startup message:
+```
+...
+=========================================
+ Texera is starting up!
+ Access at: http://localhost:8080
+=========================================
+...
+```
+
+you can open the browser and navigate to the URL shown in the message.
+
+Input the default account `texera` with password `texera`, and then click on the `Sign In` button to login:
+ +
+
+## Stop, Restart, and Uninstall Texera
+
+### Stop
+Press `Ctrl+C` in the terminal to stop Texera.
+
+If you already closed the terminal, you can go to the installation folder and run:
+```bash
+docker compose stop
+```
+to stop Texera.
+
+### Restart
+Same as the way you [launch Texera](#launch-texera).
+
+### Uninstall
+To remove Texera and all its data, go to the installation folder and run:
+```bash
+docker compose down -v
+```
+> ⚠️ Warning: This will permanently delete all the data used by Texera.
+
+
+## Advanced Settings
+
+Before making any of the changes below, please [stop Texera](#stop) first. Once you finish the changes, [restart Texera](#restart) to apply them.
+
+All changes below are to the `.env` file in the installation folder, unless otherwise noted.
+
+### Run Texera on other ports
+By default, Texera uses:
+- Port 8080 for its web service
+- Port 9000 for its MinIO storage service
+
+To change these ports, open the `.env` file and update the corresponding variables:
+- For the web service port (8080): change `TEXERA_PORT=8080` to your desired port, e.g., `TEXERA_PORT=8081`.
+- For the MinIO port (9000): change `MINIO_PORT=9000` to your desired port, e.g., `MINIO_PORT=9001`.
+
+### Change the locations of Texera data
+By default, Docker manages Texera's data locations. To change them to your own locations:
+- Find the `persistent volumes` section. For each data volume you want to specify, add the following configuration:
+```yaml
+ volume_name:
+ driver: local
+ driver_opts:
+ type: none
+ o: bind
+ device: /path/to/your/local/folder
+```
+For example, to change the folder of storing `workflow_result_data` to `/Users/johndoe/texera/data`, add the following:
+```yaml
+ workflow_result_data:
+ driver: local
+ driver_opts:
+ type: none
+ o: bind
+ device: /Users/johndoe/texera/data
+```
+
+If you already launched texera and want to change the data locations, existing data volumes need to be recreated and override in the next boot-up, i.e. select `y` when running `docker compose up` again:
+```
+$ docker compose up
+? Volume "texera-single-node-release-1-1-0_workflow_result_data" exists but doesn't match configuration in compose file. Recreate (data will be lost)? (y/N)
+y // answer y to this prompt
+```
+
+## Troubleshooting
+
+### Port conflicts
+
+If Texera fails to start, a common cause is that ports 8080 or 9000 are already in use by another application. Check which ports are occupied:
+
+```
+lsof -i :8080
+lsof -i :9000
+```
+
+Stop the conflicting process, or change Texera's ports following the instructions in [Advanced Settings > Run Texera on other ports](#run-texera-on-other-ports).
+
+### Volume conflicts
+
+PostgreSQL only runs the database initialization scripts on first startup (when its data volume is empty). If you previously started Texera and then ran `docker compose down` (without `-v`), the data volume still exists. On the next `docker compose up`, the initialization is skipped, which can cause services like lakeFS to fail because their required databases were never created.
+
+To resolve this, remove all existing volumes and start fresh:
+
+```
+docker compose down -v
+docker compose up
+```
+
+> ⚠️ Warning: `docker compose down -v` permanently deletes all Texera data.
diff --git a/texera.wiki/Installing-Texera-on-a-Kubernetes-Cluster.md b/texera.wiki/Installing-Texera-on-a-Kubernetes-Cluster.md
new file mode 100644
index 00000000000..be5b305ea6a
--- /dev/null
+++ b/texera.wiki/Installing-Texera-on-a-Kubernetes-Cluster.md
@@ -0,0 +1,226 @@
+This document describes the **five main parts** that users are expected to configure when deploying Texera using this Helm chart. All other values should generally be left with their defaults unless users are aware of specific customizations needed.
+
+---
+
+## Prerequisites
+Before configuring and deploying the Texera platform, ensure the following prerequisites are met:
+
+1. **Kubernetes Cluster**: A working Kubernetes cluster (e.g., local `minikube`, or a cloud-based cluster). There should be at least 10 free CPU cores and 8 GB of RAM available.
+2. **Helm Installed**: Helm v3 or later must be installed on your system to deploy the chart.
+3. **Custom Hostnames**:
+ - In production environment with HTTPS support, two valid hostnames must be available—one for the Texera services and another for MinIO access. For example, `texera.my.org` for Texera services and `minio.my.org` for Minio should be available for deployment and external access.
+ - In testing environment, e.g. localhost or exposing services via HTTP: one valid hostname(i.e. IP address of the server or `localhost`) is enough. **Port `30080` and Port `31000` will be occupied by default in this setting**. To change the port occupation, see the below instructions.
+4. **TLS Configuration**: You should either:
+ - Have a pre-created TLS secret, or
+ - Use [cert-manager](https://cert-manager.io/docs/tutorials/) with a valid Issuer.
+
+---
+
+## Configuration Location
+All configuration options mentioned in this guide are defined in the `values.yaml` file located under the `deployment/k8s/texera-helmchart` directory.
+
+## 1. Username and Password Configuration
+Credentials are used across different components such as PostgreSQL, MinIO, and LakeFS.
+
+### PostgreSQL
+```yaml
+postgresql:
+ auth:
+ postgresPassword: root_password
+```
+- **postgresPassword**: The superuser password used during database initialization. Required by LakeFS and Texera backend services.
+
+### MinIO
+```yaml
+minio:
+ auth:
+ rootUser: texera_minio
+ rootPassword: password
+```
+- **rootUser** and **rootPassword**: Credentials used to access MinIO. These must match the S3 credentials provided to LakeFS.
+
+### LakeFS Secrets
+```yaml
+lakefs:
+ secrets:
+ authEncryptSecretKey: random_string_for_lakefs
+ databaseConnectionString: postgres://postgres:root_password@texera-postgresql:5432/texera_lakefs?sslmode=disable
+ auth:
+ username: texera-admin
+ accessKey: AKIAIOSFOLKFSSAMPLES
+ secretKey: wJalrXUtnFEMI/K7MDENG/bPxRfiCYEXAMPLEKEY
+```
+- Ensure `databaseConnectionString` includes the correct PostgreSQL credentials.
+- `auth` decides the credentials of initializing LakeFS's admin user and accessing LakeFS via API calls.
+
+### Texera Environment Variables
+```yaml
+texeraEnvVars:
+ - name: STORAGE_JDBC_USERNAME
+ value: postgres
+ - name: USER_SYS_ENABLED
+ value: "true"
+ - name: MAX_NUM_OF_RUNNING_COMPUTING_UNITS_PER_USER
+ value: "10"
+```
+- These variables must reflect the credentials you configured for PostgreSQL, i.e. the user of the PostgreSQL.
+- These variables control the behavior of the Texera system.
+---
+
+## 2. Custom Hostnames and TLS Configuration
+Customize the domain names used for accessing Texera services via Ingress. TLS is optional but recommended for production.
+
+### Ingress Hostnames and TLS
+```yaml
+ingressPaths:
+ enabled: true
+ hostname: "localhost"
+ tlsSecretName: "" # Optional TLS secret
+ issuer: "" # Optional cert-manager issuer
+```
+- **hostname**: Set this to the custom domain for your Texera deployment (e.g., `texera.example.com`).
+- **tlsSecretName**: Optional. Set to the name of a Kubernetes TLS secret if using HTTPS.
+- **issuer**: Optional. Set to a cert-manager issuer if certificates should be managed automatically.
+
+### MinIO Ingress
+```yaml
+minio:
+ ingress:
+ hostname: "localhost"
+ tlsSecretName: ""
+ issuer: ""
+```
+- These settings follow the same rules as Texera's ingress. Configure `hostname`, `tlsSecretName`, and `issuer` as needed.
+
+---
+
+## 3. CPU and Memory Resource Configuration
+Adjust resource requests to fit your cluster's capacity.
+
+### PostgreSQL
+```yaml
+postgresql:
+ primary:
+ resources:
+ requests:
+ cpu: "4"
+ memory: "4Gi"
+```
+- Tune based on expected database workload.
+
+> Other components (e.g., webserver, file service, envoy, and language servers) use default resource settings and are not expected to be changed.
+
+---
+
+## 4. Custom Storage Class Configuration
+The chart defaults to using `local-path` which may not be suitable for all clusters.
+
+### PostgreSQL
+```yaml
+postgresql:
+ primary:
+ persistence:
+ enabled: true
+ size: 10Gi
+ storageClass: local-path
+```
+
+### MinIO
+```yaml
+minio:
+ persistence:
+ enabled: true
+ size: 20Gi
+ storageClass: local-path
+```
+
+- Replace `local-path` with your cluster's preferred StorageClass (e.g., `gp2`, `standard`, etc.).
+
+---
+
+## 5. Number of Replicas
+You can scale some components by changing their replica count using the parameters below:
+
+### Components with Replica Settings
+```yaml
+webserver:
+ numOfPods: 1
+
+yWebsocketServer:
+ replicaCount: 1
+
+pythonLanguageServer:
+ replicaCount: 8
+
+envoy:
+ replicas: 1
+
+workflowComputingUnitManager:
+ numOfPods: 1
+
+workflowCompilingService:
+ numOfPods: 1
+
+fileService:
+ numOfPods: 1
+```
+- Increase these values to scale each component horizontally based on workload needs.
+
+---
+
+## 6. Custom Ports for testing environment
+By default, Texera services will occupy port `30080`, and Minio will occupy `31000`. If you want to change it, go to the corresponding sections in the `values.yaml`:
+```yaml
+minio:
+ service:
+ type: NodePort
+ nodePorts:
+ api: 31000 # change here
+```
+```yaml
+ingress-nginx:
+ controller:
+ replicaCount: 1
+ service:
+ type: NodePort
+ nodePorts:
+ http: 30080 # change here
+```
+
+---
+
+By configuring these five areas—**credentials**, **hostnames/TLS**, **resources**, **storage classes**, and **replica counts**—you can tailor the deployment to suit your environment while relying on sane defaults for all other settings.
+
+> If you are installing Texera in your local Kubernetes environment, you don't need to change any of the above configurations unless needed.
+
+---
+
+## Installing and Uninstalling Texera
+
+### Launch the Whole Stack
+Run the following command from the root directory of the repository:
+
+```bash
+helm install texera texera-helmchart --namespace texera-dev --create-namespace
+```
+
+This will:
+- Create a Helm release named `texera`
+- Create a namespace named `texera-dev`
+- Deploy all Texera components under that namespace
+
+Please wait about **1-3 minutes** for all pods to be ready. Once the deployment is complete, Texera should be accessible at:
+
+```
+http://
+```
+
+> **Note**: If you're using a non-default kubeconfig file, append `--kubeconfig /path/to/your/kubeconfig` to the Helm command.
+
+### Terminate the Whole Stack
+To uninstall Texera and clean up all related resources:
+
+```bash
+helm uninstall texera --namespace texera-dev
+```
+
diff --git a/texera.wiki/Installing-Texera-on-a-Single-Node.md b/texera.wiki/Installing-Texera-on-a-Single-Node.md
new file mode 100644
index 00000000000..8a90ac1aeee
--- /dev/null
+++ b/texera.wiki/Installing-Texera-on-a-Single-Node.md
@@ -0,0 +1 @@
+Please see our latest instruction by clicking: https://github.com/apache/texera/wiki/Installing-Apache-Texera-using-Docker
\ No newline at end of file
diff --git a/texera.wiki/Making-Contributions.md b/texera.wiki/Making-Contributions.md
new file mode 100644
index 00000000000..2f9f8539e50
--- /dev/null
+++ b/texera.wiki/Making-Contributions.md
@@ -0,0 +1,7 @@
+We welcome interested developers to participate in the project and make contributions.
+
+1. Follow the instructions at https://github.com/apache/texera/wiki/Installing-Texera-on-a-Single-Node to install Texera on your laptop using Docker. Get familiar with the system as a user.
+1. Follow the steps in https://github.com/apache/texera/wiki to get on board and raise a pull request PR). It will be reviewed by the team before it can be merged.
+1. Check issues in https://github.com/apache/texera/issues and see if you can fix some of them. Focus on the easy ones first.
+
+After making enough contributions, you may be promoted to be a committer. If you prefer, we can also add you to our Slack workspace and invite you to join our meetings.
\ No newline at end of file
diff --git a/texera.wiki/Migrate-a-Jupyter-Notebook-to-a-Texera-Workflow.md b/texera.wiki/Migrate-a-Jupyter-Notebook-to-a-Texera-Workflow.md
new file mode 100644
index 00000000000..160356ca235
--- /dev/null
+++ b/texera.wiki/Migrate-a-Jupyter-Notebook-to-a-Texera-Workflow.md
@@ -0,0 +1,185 @@
+This document provides guidelines on how to migrate a Jupyter notebook to a Texera workflow.
+
+## 1. Overview
+Jupyter Notebook is an open-source, browser-based environment for interactive computing that blends executable code with rich media in a single document. Work is organized into discrete cells that can be run individually, with each cell’s output persisted in the notebook.
+
+A Texera workflow provides an operator-centric abstraction for data-science pipelines. A workflow is a directed acyclic graph (DAG) in which every node is an operator, such as CSV Scan, Projection, Filter, Aggregate, Python UDF, or ML Model, and an edge represents the flow of data between operators.
+
+Migrating notebook code into Texera operators, then wiring those operators with links, transforms ad-hoc analyses into shareable, pipeline-oriented workflows that enable collaboration and scalable execution.
+
+
+
+## 2. Example: convert a "tweet analysis" notebook into a workflow
+
+> The [notebook](https://hub.texera.io/dashboard/user/dataset/124), [dataset](https://hub.texera.io/dashboard/user/dataset/124) and [workflow](https://hub.texera.io/dashboard/user/workspace/1162) in this example are available on [TexeraHub](https://hub.texera.io/dashboard/about).
+
+### Notebook Overview
+We will use a Tweet-Analysis notebook to demonstrate the migration process. The notebook has three cells:
+- Cell 1
+```python
+import pandas as pd
+import plotly.express as px
+
+file_path = 'clean_tweets.csv'
+df = pd.read_csv(file_path)
+df
+```
+- Cell 2
+```python
+df_projection = df[['tweet_id', 'create_at_month']]
+df_aggregated = df_projection.groupby('create_at_month').agg(**{'#tweets': ('tweet_id', 'count')}).reset_index()
+df_sorted = df_aggregated.sort_values(by='create_at_month', ascending=True)
+fig = px.bar(df_sorted,
+ x='create_at_month',
+ y='#tweets',
+ color='#tweets',
+ color_continuous_scale='thermal',
+ labels={'create_at_month': 'Month', '#tweets': '# of Tweets'})
+fig.show()
+```
+- Cell 3
+```python
+df['text_length'] = df['text'].astype(str).str.len()
+length_stats = df['text_length'].agg(['min', 'max', 'mean'])
+print(length_stats)
+```
+Below is the screenshot of the notebook after the execution:
+
+
+
+## Stop, Restart, and Uninstall Texera
+
+### Stop
+Press `Ctrl+C` in the terminal to stop Texera.
+
+If you already closed the terminal, you can go to the installation folder and run:
+```bash
+docker compose stop
+```
+to stop Texera.
+
+### Restart
+Same as the way you [launch Texera](#launch-texera).
+
+### Uninstall
+To remove Texera and all its data, go to the installation folder and run:
+```bash
+docker compose down -v
+```
+> ⚠️ Warning: This will permanently delete all the data used by Texera.
+
+
+## Advanced Settings
+
+Before making any of the changes below, please [stop Texera](#stop) first. Once you finish the changes, [restart Texera](#restart) to apply them.
+
+All changes below are to the `.env` file in the installation folder, unless otherwise noted.
+
+### Run Texera on other ports
+By default, Texera uses:
+- Port 8080 for its web service
+- Port 9000 for its MinIO storage service
+
+To change these ports, open the `.env` file and update the corresponding variables:
+- For the web service port (8080): change `TEXERA_PORT=8080` to your desired port, e.g., `TEXERA_PORT=8081`.
+- For the MinIO port (9000): change `MINIO_PORT=9000` to your desired port, e.g., `MINIO_PORT=9001`.
+
+### Change the locations of Texera data
+By default, Docker manages Texera's data locations. To change them to your own locations:
+- Find the `persistent volumes` section. For each data volume you want to specify, add the following configuration:
+```yaml
+ volume_name:
+ driver: local
+ driver_opts:
+ type: none
+ o: bind
+ device: /path/to/your/local/folder
+```
+For example, to change the folder of storing `workflow_result_data` to `/Users/johndoe/texera/data`, add the following:
+```yaml
+ workflow_result_data:
+ driver: local
+ driver_opts:
+ type: none
+ o: bind
+ device: /Users/johndoe/texera/data
+```
+
+If you already launched texera and want to change the data locations, existing data volumes need to be recreated and override in the next boot-up, i.e. select `y` when running `docker compose up` again:
+```
+$ docker compose up
+? Volume "texera-single-node-release-1-1-0_workflow_result_data" exists but doesn't match configuration in compose file. Recreate (data will be lost)? (y/N)
+y // answer y to this prompt
+```
+
+## Troubleshooting
+
+### Port conflicts
+
+If Texera fails to start, a common cause is that ports 8080 or 9000 are already in use by another application. Check which ports are occupied:
+
+```
+lsof -i :8080
+lsof -i :9000
+```
+
+Stop the conflicting process, or change Texera's ports following the instructions in [Advanced Settings > Run Texera on other ports](#run-texera-on-other-ports).
+
+### Volume conflicts
+
+PostgreSQL only runs the database initialization scripts on first startup (when its data volume is empty). If you previously started Texera and then ran `docker compose down` (without `-v`), the data volume still exists. On the next `docker compose up`, the initialization is skipped, which can cause services like lakeFS to fail because their required databases were never created.
+
+To resolve this, remove all existing volumes and start fresh:
+
+```
+docker compose down -v
+docker compose up
+```
+
+> ⚠️ Warning: `docker compose down -v` permanently deletes all Texera data.
diff --git a/texera.wiki/Installing-Texera-on-a-Kubernetes-Cluster.md b/texera.wiki/Installing-Texera-on-a-Kubernetes-Cluster.md
new file mode 100644
index 00000000000..be5b305ea6a
--- /dev/null
+++ b/texera.wiki/Installing-Texera-on-a-Kubernetes-Cluster.md
@@ -0,0 +1,226 @@
+This document describes the **five main parts** that users are expected to configure when deploying Texera using this Helm chart. All other values should generally be left with their defaults unless users are aware of specific customizations needed.
+
+---
+
+## Prerequisites
+Before configuring and deploying the Texera platform, ensure the following prerequisites are met:
+
+1. **Kubernetes Cluster**: A working Kubernetes cluster (e.g., local `minikube`, or a cloud-based cluster). There should be at least 10 free CPU cores and 8 GB of RAM available.
+2. **Helm Installed**: Helm v3 or later must be installed on your system to deploy the chart.
+3. **Custom Hostnames**:
+ - In production environment with HTTPS support, two valid hostnames must be available—one for the Texera services and another for MinIO access. For example, `texera.my.org` for Texera services and `minio.my.org` for Minio should be available for deployment and external access.
+ - In testing environment, e.g. localhost or exposing services via HTTP: one valid hostname(i.e. IP address of the server or `localhost`) is enough. **Port `30080` and Port `31000` will be occupied by default in this setting**. To change the port occupation, see the below instructions.
+4. **TLS Configuration**: You should either:
+ - Have a pre-created TLS secret, or
+ - Use [cert-manager](https://cert-manager.io/docs/tutorials/) with a valid Issuer.
+
+---
+
+## Configuration Location
+All configuration options mentioned in this guide are defined in the `values.yaml` file located under the `deployment/k8s/texera-helmchart` directory.
+
+## 1. Username and Password Configuration
+Credentials are used across different components such as PostgreSQL, MinIO, and LakeFS.
+
+### PostgreSQL
+```yaml
+postgresql:
+ auth:
+ postgresPassword: root_password
+```
+- **postgresPassword**: The superuser password used during database initialization. Required by LakeFS and Texera backend services.
+
+### MinIO
+```yaml
+minio:
+ auth:
+ rootUser: texera_minio
+ rootPassword: password
+```
+- **rootUser** and **rootPassword**: Credentials used to access MinIO. These must match the S3 credentials provided to LakeFS.
+
+### LakeFS Secrets
+```yaml
+lakefs:
+ secrets:
+ authEncryptSecretKey: random_string_for_lakefs
+ databaseConnectionString: postgres://postgres:root_password@texera-postgresql:5432/texera_lakefs?sslmode=disable
+ auth:
+ username: texera-admin
+ accessKey: AKIAIOSFOLKFSSAMPLES
+ secretKey: wJalrXUtnFEMI/K7MDENG/bPxRfiCYEXAMPLEKEY
+```
+- Ensure `databaseConnectionString` includes the correct PostgreSQL credentials.
+- `auth` decides the credentials of initializing LakeFS's admin user and accessing LakeFS via API calls.
+
+### Texera Environment Variables
+```yaml
+texeraEnvVars:
+ - name: STORAGE_JDBC_USERNAME
+ value: postgres
+ - name: USER_SYS_ENABLED
+ value: "true"
+ - name: MAX_NUM_OF_RUNNING_COMPUTING_UNITS_PER_USER
+ value: "10"
+```
+- These variables must reflect the credentials you configured for PostgreSQL, i.e. the user of the PostgreSQL.
+- These variables control the behavior of the Texera system.
+---
+
+## 2. Custom Hostnames and TLS Configuration
+Customize the domain names used for accessing Texera services via Ingress. TLS is optional but recommended for production.
+
+### Ingress Hostnames and TLS
+```yaml
+ingressPaths:
+ enabled: true
+ hostname: "localhost"
+ tlsSecretName: "" # Optional TLS secret
+ issuer: "" # Optional cert-manager issuer
+```
+- **hostname**: Set this to the custom domain for your Texera deployment (e.g., `texera.example.com`).
+- **tlsSecretName**: Optional. Set to the name of a Kubernetes TLS secret if using HTTPS.
+- **issuer**: Optional. Set to a cert-manager issuer if certificates should be managed automatically.
+
+### MinIO Ingress
+```yaml
+minio:
+ ingress:
+ hostname: "localhost"
+ tlsSecretName: ""
+ issuer: ""
+```
+- These settings follow the same rules as Texera's ingress. Configure `hostname`, `tlsSecretName`, and `issuer` as needed.
+
+---
+
+## 3. CPU and Memory Resource Configuration
+Adjust resource requests to fit your cluster's capacity.
+
+### PostgreSQL
+```yaml
+postgresql:
+ primary:
+ resources:
+ requests:
+ cpu: "4"
+ memory: "4Gi"
+```
+- Tune based on expected database workload.
+
+> Other components (e.g., webserver, file service, envoy, and language servers) use default resource settings and are not expected to be changed.
+
+---
+
+## 4. Custom Storage Class Configuration
+The chart defaults to using `local-path` which may not be suitable for all clusters.
+
+### PostgreSQL
+```yaml
+postgresql:
+ primary:
+ persistence:
+ enabled: true
+ size: 10Gi
+ storageClass: local-path
+```
+
+### MinIO
+```yaml
+minio:
+ persistence:
+ enabled: true
+ size: 20Gi
+ storageClass: local-path
+```
+
+- Replace `local-path` with your cluster's preferred StorageClass (e.g., `gp2`, `standard`, etc.).
+
+---
+
+## 5. Number of Replicas
+You can scale some components by changing their replica count using the parameters below:
+
+### Components with Replica Settings
+```yaml
+webserver:
+ numOfPods: 1
+
+yWebsocketServer:
+ replicaCount: 1
+
+pythonLanguageServer:
+ replicaCount: 8
+
+envoy:
+ replicas: 1
+
+workflowComputingUnitManager:
+ numOfPods: 1
+
+workflowCompilingService:
+ numOfPods: 1
+
+fileService:
+ numOfPods: 1
+```
+- Increase these values to scale each component horizontally based on workload needs.
+
+---
+
+## 6. Custom Ports for testing environment
+By default, Texera services will occupy port `30080`, and Minio will occupy `31000`. If you want to change it, go to the corresponding sections in the `values.yaml`:
+```yaml
+minio:
+ service:
+ type: NodePort
+ nodePorts:
+ api: 31000 # change here
+```
+```yaml
+ingress-nginx:
+ controller:
+ replicaCount: 1
+ service:
+ type: NodePort
+ nodePorts:
+ http: 30080 # change here
+```
+
+---
+
+By configuring these five areas—**credentials**, **hostnames/TLS**, **resources**, **storage classes**, and **replica counts**—you can tailor the deployment to suit your environment while relying on sane defaults for all other settings.
+
+> If you are installing Texera in your local Kubernetes environment, you don't need to change any of the above configurations unless needed.
+
+---
+
+## Installing and Uninstalling Texera
+
+### Launch the Whole Stack
+Run the following command from the root directory of the repository:
+
+```bash
+helm install texera texera-helmchart --namespace texera-dev --create-namespace
+```
+
+This will:
+- Create a Helm release named `texera`
+- Create a namespace named `texera-dev`
+- Deploy all Texera components under that namespace
+
+Please wait about **1-3 minutes** for all pods to be ready. Once the deployment is complete, Texera should be accessible at:
+
+```
+http://
+```
+
+> **Note**: If you're using a non-default kubeconfig file, append `--kubeconfig /path/to/your/kubeconfig` to the Helm command.
+
+### Terminate the Whole Stack
+To uninstall Texera and clean up all related resources:
+
+```bash
+helm uninstall texera --namespace texera-dev
+```
+
diff --git a/texera.wiki/Installing-Texera-on-a-Single-Node.md b/texera.wiki/Installing-Texera-on-a-Single-Node.md
new file mode 100644
index 00000000000..8a90ac1aeee
--- /dev/null
+++ b/texera.wiki/Installing-Texera-on-a-Single-Node.md
@@ -0,0 +1 @@
+Please see our latest instruction by clicking: https://github.com/apache/texera/wiki/Installing-Apache-Texera-using-Docker
\ No newline at end of file
diff --git a/texera.wiki/Making-Contributions.md b/texera.wiki/Making-Contributions.md
new file mode 100644
index 00000000000..2f9f8539e50
--- /dev/null
+++ b/texera.wiki/Making-Contributions.md
@@ -0,0 +1,7 @@
+We welcome interested developers to participate in the project and make contributions.
+
+1. Follow the instructions at https://github.com/apache/texera/wiki/Installing-Texera-on-a-Single-Node to install Texera on your laptop using Docker. Get familiar with the system as a user.
+1. Follow the steps in https://github.com/apache/texera/wiki to get on board and raise a pull request PR). It will be reviewed by the team before it can be merged.
+1. Check issues in https://github.com/apache/texera/issues and see if you can fix some of them. Focus on the easy ones first.
+
+After making enough contributions, you may be promoted to be a committer. If you prefer, we can also add you to our Slack workspace and invite you to join our meetings.
\ No newline at end of file
diff --git a/texera.wiki/Migrate-a-Jupyter-Notebook-to-a-Texera-Workflow.md b/texera.wiki/Migrate-a-Jupyter-Notebook-to-a-Texera-Workflow.md
new file mode 100644
index 00000000000..160356ca235
--- /dev/null
+++ b/texera.wiki/Migrate-a-Jupyter-Notebook-to-a-Texera-Workflow.md
@@ -0,0 +1,185 @@
+This document provides guidelines on how to migrate a Jupyter notebook to a Texera workflow.
+
+## 1. Overview
+Jupyter Notebook is an open-source, browser-based environment for interactive computing that blends executable code with rich media in a single document. Work is organized into discrete cells that can be run individually, with each cell’s output persisted in the notebook.
+
+A Texera workflow provides an operator-centric abstraction for data-science pipelines. A workflow is a directed acyclic graph (DAG) in which every node is an operator, such as CSV Scan, Projection, Filter, Aggregate, Python UDF, or ML Model, and an edge represents the flow of data between operators.
+
+Migrating notebook code into Texera operators, then wiring those operators with links, transforms ad-hoc analyses into shareable, pipeline-oriented workflows that enable collaboration and scalable execution.
+
+
+
+## 2. Example: convert a "tweet analysis" notebook into a workflow
+
+> The [notebook](https://hub.texera.io/dashboard/user/dataset/124), [dataset](https://hub.texera.io/dashboard/user/dataset/124) and [workflow](https://hub.texera.io/dashboard/user/workspace/1162) in this example are available on [TexeraHub](https://hub.texera.io/dashboard/about).
+
+### Notebook Overview
+We will use a Tweet-Analysis notebook to demonstrate the migration process. The notebook has three cells:
+- Cell 1
+```python
+import pandas as pd
+import plotly.express as px
+
+file_path = 'clean_tweets.csv'
+df = pd.read_csv(file_path)
+df
+```
+- Cell 2
+```python
+df_projection = df[['tweet_id', 'create_at_month']]
+df_aggregated = df_projection.groupby('create_at_month').agg(**{'#tweets': ('tweet_id', 'count')}).reset_index()
+df_sorted = df_aggregated.sort_values(by='create_at_month', ascending=True)
+fig = px.bar(df_sorted,
+ x='create_at_month',
+ y='#tweets',
+ color='#tweets',
+ color_continuous_scale='thermal',
+ labels={'create_at_month': 'Month', '#tweets': '# of Tweets'})
+fig.show()
+```
+- Cell 3
+```python
+df['text_length'] = df['text'].astype(str).str.len()
+length_stats = df['text_length'].agg(['min', 'max', 'mean'])
+print(length_stats)
+```
+Below is the screenshot of the notebook after the execution:
+ +
+
+### 2.1. Identify the data files and upload them to a Texera dataset
+From cell 1, we see the notebook reads `clean_tweets.csv`.
+```python
+#...
+file_path = 'clean_tweets.csv'
+df = pd.read_csv(file_path)
+df
+```
+
+To let Texera read the same file, create a dataset in Texera, drag-and-drop the CSV file into it, and create a version:
+
+
+
+
+### 2.1. Identify the data files and upload them to a Texera dataset
+From cell 1, we see the notebook reads `clean_tweets.csv`.
+```python
+#...
+file_path = 'clean_tweets.csv'
+df = pd.read_csv(file_path)
+df
+```
+
+To let Texera read the same file, create a dataset in Texera, drag-and-drop the CSV file into it, and create a version:
+
+ +
+ +
+
+
+
+### 2.2. Read the source data using data input operators
+After the file is in a dataset, create a workflow and add a data-input operator that reads the file.
+
+Because the file is CSV, we should use **CSVFileScanOperator** and specify the file path. Running the workflow should display the same table as Cell 1 in the result panel:
+
+
+
+
+After this step, we have successfully converted cell 1 into a Texera operator.
+
+### 2.3. Migrate data-processing logic into operators and links
+#### Case 1: Use native operators for common processing logic
+Cell 2 performs a sequence of operations after reading the data source: projection to keep only two columns, aggregation to calculate the number of tweets per month, sort based on count, and then visualizing using the bar chart:
+```python
+df_projection = df[['tweet_id', 'create_at_month']]
+df_aggregated = df_projection.groupby('create_at_month').agg(**{'#tweets': ('tweet_id', 'count')}).reset_index()
+df_sorted = df_aggregated.sort_values(by='create_at_month', ascending=True)
+fig = px.bar(df_sorted,
+ x='create_at_month',
+ y='#tweets',
+ color='#tweets',
+ color_continuous_scale='thermal',
+ labels={'create_at_month': 'Month', '#tweets': '# of Tweets'})
+fig.show()
+```
+These operations are very common in data science pipelines. And Texera provides several native operators that have the exact same functionalities and are easy to use:
+* **Projection operator** → `df[['tweet_id', 'create_at_month']]`
+* **Aggregate operator** → `groupby('create_at_month').agg(...).reset_index()`
+* **Sort operator** → `sort_values(by='create_at_month', ascending=True)`
+* **Barchart operator** → `px.bar(...)`
+
+Therefore, we can drag-n-drop these operators, connect them after the CSVFileScan. Running the workflow should display the same bar chart as in Cell 2.
+
+
+
+Now we have successfully migrate cell 2 into Texera.
+
+#### Case 2: Use UDF operators for complex processing logic
+According to cell 3, a new column is added to the original tweet data table to represent the length of the text column. After that, min, max, mean of the text_length column are calculated.
+```python
+df['text_length'] = df['text'].astype(str).str.len()
+length_stats = df['text_length'].agg(['min', 'max', 'mean'])
+print(length_stats.rename({'min': 'min_len', 'max': 'max_len', 'mean': 'avg_len'}))
+```
+
+For code that involves column addition/removal and other complex data operations, Texera supports UDF operators that allow users to write custom logic as an operator that processes the data.
+
+In this example, we can add a **PythonUDF operator** **after** the CSVScanOperator. Inside the UDF we use TableAPI as it involves the table-level column addition. Since in the `pytexera` package, Table supports most of the pandas Dataframe APIs, we can simply adjust the code in Cell 3 and put it into UDF as the processing logic. There are two ways to show the final result:
+1. Use `print` statement in the UDF code block. The result will be shown in the "Console" tab:
+```python
+from typing import Iterator, Optional
+from pytexera import *
+import pandas as pd
+class TextLengthStatsOperator(UDFTableOperator):
+ @overrides
+ def process_table(self, table: Table, port: int) -> Iterator[Optional[TableLike]]:
+ # add a new column text_length
+ table['text_length'] = table['text'].astype(str).str.len()
+
+ # Aggregate min, max, and mean
+ length_stats = table['text_length'].agg(['min', 'max', 'mean'])
+ print(length_stats)
+ yield None
+```
+
+
+
+
+
+### 2.2. Read the source data using data input operators
+After the file is in a dataset, create a workflow and add a data-input operator that reads the file.
+
+Because the file is CSV, we should use **CSVFileScanOperator** and specify the file path. Running the workflow should display the same table as Cell 1 in the result panel:
+
+
+
+
+After this step, we have successfully converted cell 1 into a Texera operator.
+
+### 2.3. Migrate data-processing logic into operators and links
+#### Case 1: Use native operators for common processing logic
+Cell 2 performs a sequence of operations after reading the data source: projection to keep only two columns, aggregation to calculate the number of tweets per month, sort based on count, and then visualizing using the bar chart:
+```python
+df_projection = df[['tweet_id', 'create_at_month']]
+df_aggregated = df_projection.groupby('create_at_month').agg(**{'#tweets': ('tweet_id', 'count')}).reset_index()
+df_sorted = df_aggregated.sort_values(by='create_at_month', ascending=True)
+fig = px.bar(df_sorted,
+ x='create_at_month',
+ y='#tweets',
+ color='#tweets',
+ color_continuous_scale='thermal',
+ labels={'create_at_month': 'Month', '#tweets': '# of Tweets'})
+fig.show()
+```
+These operations are very common in data science pipelines. And Texera provides several native operators that have the exact same functionalities and are easy to use:
+* **Projection operator** → `df[['tweet_id', 'create_at_month']]`
+* **Aggregate operator** → `groupby('create_at_month').agg(...).reset_index()`
+* **Sort operator** → `sort_values(by='create_at_month', ascending=True)`
+* **Barchart operator** → `px.bar(...)`
+
+Therefore, we can drag-n-drop these operators, connect them after the CSVFileScan. Running the workflow should display the same bar chart as in Cell 2.
+
+
+
+Now we have successfully migrate cell 2 into Texera.
+
+#### Case 2: Use UDF operators for complex processing logic
+According to cell 3, a new column is added to the original tweet data table to represent the length of the text column. After that, min, max, mean of the text_length column are calculated.
+```python
+df['text_length'] = df['text'].astype(str).str.len()
+length_stats = df['text_length'].agg(['min', 'max', 'mean'])
+print(length_stats.rename({'min': 'min_len', 'max': 'max_len', 'mean': 'avg_len'}))
+```
+
+For code that involves column addition/removal and other complex data operations, Texera supports UDF operators that allow users to write custom logic as an operator that processes the data.
+
+In this example, we can add a **PythonUDF operator** **after** the CSVScanOperator. Inside the UDF we use TableAPI as it involves the table-level column addition. Since in the `pytexera` package, Table supports most of the pandas Dataframe APIs, we can simply adjust the code in Cell 3 and put it into UDF as the processing logic. There are two ways to show the final result:
+1. Use `print` statement in the UDF code block. The result will be shown in the "Console" tab:
+```python
+from typing import Iterator, Optional
+from pytexera import *
+import pandas as pd
+class TextLengthStatsOperator(UDFTableOperator):
+ @overrides
+ def process_table(self, table: Table, port: int) -> Iterator[Optional[TableLike]]:
+ # add a new column text_length
+ table['text_length'] = table['text'].astype(str).str.len()
+
+ # Aggregate min, max, and mean
+ length_stats = table['text_length'].agg(['min', 'max', 'mean'])
+ print(length_stats)
+ yield None
+```
+ +
+2. Yield the result as a table with columns `min`, `max`, and `mean` to the downstream. Make sure to declare the output schema in the operator panel. The result will be shown in the "Result" tab:
+```python
+from typing import Iterator, Optional
+from pytexera import *
+import pandas as pd
+class TextLengthStatsOperator(UDFTableOperator):
+ @overrides
+ def process_table(self, table: Table, port: int) -> Iterator[Optional[TableLike]]:
+ # add a new column text_length
+ table['text_length'] = table['text'].astype(str).str.len()
+
+ # Aggregate min, max, and mean
+ length_stats = table['text_length'].agg(['min', 'max', 'mean'])
+ yield length_stats
+```
+
+
+2. Yield the result as a table with columns `min`, `max`, and `mean` to the downstream. Make sure to declare the output schema in the operator panel. The result will be shown in the "Result" tab:
+```python
+from typing import Iterator, Optional
+from pytexera import *
+import pandas as pd
+class TextLengthStatsOperator(UDFTableOperator):
+ @overrides
+ def process_table(self, table: Table, port: int) -> Iterator[Optional[TableLike]]:
+ # add a new column text_length
+ table['text_length'] = table['text'].astype(str).str.len()
+
+ # Aggregate min, max, and mean
+ length_stats = table['text_length'].agg(['min', 'max', 'mean'])
+ yield length_stats
+```
+ +
+
+### Step 4: Annotate some operators as ‘View Result’ to display the same results as Notebook
+Jupyter displays the output of every cell, whereas Texera shows only sink-operator outputs by default.
+
+To view intermediate results, for example, the results after SortOperator, right-click the operator, select "View Result" shown in the drop-down menu, and re-run the workflow:
+
+
+
+Texera will now show the operator’s output in the result panel.
+
+
+
+### Step 4: Annotate some operators as ‘View Result’ to display the same results as Notebook
+Jupyter displays the output of every cell, whereas Texera shows only sink-operator outputs by default.
+
+To view intermediate results, for example, the results after SortOperator, right-click the operator, select "View Result" shown in the drop-down menu, and re-run the workflow:
+
+
+
+Texera will now show the operator’s output in the result panel.
+ +
+
+## 3. Tips
+
+- **Utilize Texera native operators as much as possible**
+
+Texera contains more than 110 built-in operators that cover data loading, cleaning, wrangling, visualization, and AI/ML. Replacing custom code with native operators makes workflows clearer and usually improves performance.
+
+
+- **Identify the data dependencies in the Python code in order to connect operators**
+
+In Texera, data flows along links. Before wiring operators, review the notebook to understand which variables feed which; then reproduce those dependencies via links so the executions matches the original notebook.
+
+
+
+
+
+
+
+
+
+
+
+
+
+
diff --git a/texera.wiki/Past-GUI-screenshots.md b/texera.wiki/Past-GUI-screenshots.md
new file mode 100644
index 00000000000..6fedef68647
--- /dev/null
+++ b/texera.wiki/Past-GUI-screenshots.md
@@ -0,0 +1,61 @@
+### 1/29/2023
+Version 0.5.3
+
+
+
+## 3. Tips
+
+- **Utilize Texera native operators as much as possible**
+
+Texera contains more than 110 built-in operators that cover data loading, cleaning, wrangling, visualization, and AI/ML. Replacing custom code with native operators makes workflows clearer and usually improves performance.
+
+
+- **Identify the data dependencies in the Python code in order to connect operators**
+
+In Texera, data flows along links. Before wiring operators, review the notebook to understand which variables feed which; then reproduce those dependencies via links so the executions matches the original notebook.
+
+
+
+
+
+
+
+
+
+
+
+
+
+
diff --git a/texera.wiki/Past-GUI-screenshots.md b/texera.wiki/Past-GUI-screenshots.md
new file mode 100644
index 00000000000..6fedef68647
--- /dev/null
+++ b/texera.wiki/Past-GUI-screenshots.md
@@ -0,0 +1,61 @@
+### 1/29/2023
+Version 0.5.3
+ +
+
+### 1/27/2022
+Version 0.5.3
+
+
+
+### 1/27/2022
+Version 0.5.3
+ +
+
+### 2/1/2021
+Version 0.5.3
+
+
+
+### 2/1/2021
+Version 0.5.3
+ +
+
+### 1/29/2020
+Version 0.5.0
+
+
+
+### 1/29/2020
+Version 0.5.0
+ +
+### 2/3/2019
+Version 0.3.0
+
+third version of Texera GUI written in Angular CLI, with more modularized code base. [Issue #603](https://github.com/Texera/texera/issues/603)
+
+
+### 8/31/2017
+Version 0.2.3
+
+adding result bar, operator icon, and dropdown menu to second version. [PR #554](https://github.com/Texera/texera/pull/554)
+
+
+### 5/30/2017
+Version 0.2.2
+
+initial autocomplete feature [PR #505](https://github.com/Texera/texera/pull/505)
+
+
+### 5/7/2017
+Version 0.2.1
+
+updated color of second version [PR #481](https://github.com/Texera/texera/pull/481)
+
+
+### 4/27/2017
+Version 0.2.0
+
+second version written in Angular [Issue #327](https://github.com/Texera/texera/issues/327)
+
+
+### 2/6/2017
+Version 0.1.1
+
+updated color of first version [PR #366](https://github.com/Texera/texera/pull/366)
+
+
+### 11/28/2016:
+Version 0.1.0
+
+first version in plain JS [PR #301](https://github.com/Texera/texera/pull/301)
+
diff --git a/texera.wiki/[VOTE]-Release-Apache-Texera-(incubating)-Email-Template.md b/texera.wiki/[VOTE]-Release-Apache-Texera-(incubating)-Email-Template.md
new file mode 100644
index 00000000000..aff804fe84b
--- /dev/null
+++ b/texera.wiki/[VOTE]-Release-Apache-Texera-(incubating)-Email-Template.md
@@ -0,0 +1,85 @@
+Subject: [VOTE] Release Apache Texera (incubating) ${VERSION} RC${RC_NUM}
+
+Hi Texera Community,
+
+This is a call for vote to release Apache Texera (incubating) ${VERSION}.
+
+== Release Candidate Artifacts ==
+
+The release candidate artifacts can be found at:
+https://dist.apache.org/repos/dist/dev/incubator/texera/${RC_DIR}/
+
+The artifacts include:
+- apache-texera-${VERSION}-rc${RC_NUM}-src.tar.gz (source tarball)
+- apache-texera-${VERSION}-rc${RC_NUM}-src.tar.gz.asc (GPG signature)
+- apache-texera-${VERSION}-rc${RC_NUM}-src.tar.gz.sha512 (SHA512 checksum)
+
+== Git Tag ==
+
+The Git tag for this release candidate:
+https://github.com/apache/incubator-texera/releases/tag/${TAG_NAME}
+
+The commit hash for this tag:
+${COMMIT_HASH}
+
+== Release Notes ==
+
+Release notes can be found at:
+https://github.com/apache/incubator-texera/releases/tag/${TAG_NAME}
+
+== Keys ==
+
+The artifacts have been signed with Key [${GPG_KEY_ID}], corresponding to [${GPG_EMAIL}].
+
+The KEYS file containing the public keys can be found at:
+https://dist.apache.org/repos/dist/dev/incubator/texera/KEYS
+
+== How to Verify ==
+
+1. Download the release artifacts:
+
+ wget https://dist.apache.org/repos/dist/dev/incubator/texera/${RC_DIR}/apache-texera-${VERSION}-rc${RC_NUM}-src.tar.gz
+ wget https://dist.apache.org/repos/dist/dev/incubator/texera/${RC_DIR}/apache-texera-${VERSION}-rc${RC_NUM}-src.tar.gz.asc
+ wget https://dist.apache.org/repos/dist/dev/incubator/texera/${RC_DIR}/apache-texera-${VERSION}-rc${RC_NUM}-src.tar.gz.sha512
+
+2. Import the KEYS file and verify the GPG signature:
+
+ wget https://dist.apache.org/repos/dist/dev/incubator/texera/KEYS
+ gpg --import KEYS
+ gpg --verify apache-texera-${VERSION}-rc${RC_NUM}-src.tar.gz.asc apache-texera-${VERSION}-rc${RC_NUM}-src.tar.gz
+
+3. Verify the SHA512 checksum:
+
+ sha512sum -c apache-texera-${VERSION}-rc${RC_NUM}-src.tar.gz.sha512
+
+4. Extract and build from source:
+
+ tar -xzf apache-texera-${VERSION}-rc${RC_NUM}-src.tar.gz
+ cd apache-texera-${VERSION}-rc${RC_NUM}-src
+ # Follow build instructions in README
+
+== How to Vote ==
+
+The vote will be open for at least 72 hours.
+
+Please vote accordingly:
+
+[ ] +1 Approve the release
+[ ] 0 No opinion
+[ ] -1 Disapprove the release (please provide the reason)
+
+== Checklist for Reference ==
+
+When reviewing, please check:
+
+[ ] Download links are valid
+[ ] Checksums and PGP signatures are valid
+[ ] LICENSE and NOTICE files are correct
+[ ] All files have ASF license headers where appropriate
+[ ] No unexpected binary files
+[ ] Source tarball matches the Git tag
+[ ] Can compile from source successfully
+
+Thanks,
+[Your Name]
+Apache Texera (incubating) PPMC
\ No newline at end of file
diff --git a/texera.wiki/_Footer.md b/texera.wiki/_Footer.md
new file mode 100644
index 00000000000..25cea8adf0b
--- /dev/null
+++ b/texera.wiki/_Footer.md
@@ -0,0 +1 @@
+Copyright © 2025 The Apache Software Foundation.
\ No newline at end of file
diff --git a/texera.wiki/_Sidebar.md b/texera.wiki/_Sidebar.md
new file mode 100644
index 00000000000..3ef45d694ee
--- /dev/null
+++ b/texera.wiki/_Sidebar.md
@@ -0,0 +1,11 @@
+Getting Started
+* [Step 0 - Guide to Use Texera](https://github.com/apache/texera/wiki/Guide-for-how-to-use-Texera)
+* [Step 1 - Guide for Developers](https://github.com/apache/texera/wiki/Guide-for-Developers)
+
+Implementing an Operator
+* [Step 2 - Guide to Implement a Java Native Operator](https://github.com/apache/texera/wiki/Guide-to-Implement-a-Java-Native-Operator)
+* [Step 3 - Guide to Use a Python UDF](https://github.com/apache/texera/wiki/Guide-to-Use-a-Python-UDF)
+* [Step 4 - Guide to Implement a Python Native Operator](https://github.com/apache/texera/wiki/Guide-to-Implement-a-Python-Native-Operator-(converting-from-a-Python-UDF))
+
+Contributing to the Project
+* [Step 5 - Guide to Raise a Pull Request (PR)](https://github.com/apache/texera/blob/main/CONTRIBUTING.md)
diff --git a/texera.wiki/statics/files/CountrySalesData.csv b/texera.wiki/statics/files/CountrySalesData.csv
new file mode 100644
index 00000000000..99dd238fd48
--- /dev/null
+++ b/texera.wiki/statics/files/CountrySalesData.csv
@@ -0,0 +1,101 @@
+Region,Country,Item Type,Sales Channel,Order Priority,Order Date,Order ID,Ship Date,Units Sold,Unit Price,Unit Cost,Total Revenue,Total Cost,Total Profit
+Australia and Oceania,Tuvalu,Baby Food,Offline,H,5/28/2010,669165933,6/27/2010,9925,255.28,159.42,2533654.00,1582243.50,951410.50
+Central America and the Caribbean,Grenada,Cereal,Online,C,8/22/2012,963881480,9/15/2012,2804,205.70,117.11,576782.80,328376.44,248406.36
+Europe,Russia,Office Supplies,Offline,L,5/2/2014,341417157,5/8/2014,1779,651.21,524.96,1158502.59,933903.84,224598.75
+Sub-Saharan Africa,Sao Tome and Principe,Fruits,Online,C,6/20/2014,514321792,7/5/2014,8102,9.33,6.92,75591.66,56065.84,19525.82
+Sub-Saharan Africa,Rwanda,Office Supplies,Offline,L,2/1/2013,115456712,2/6/2013,5062,651.21,524.96,3296425.02,2657347.52,639077.50
+Australia and Oceania,Solomon Islands,Baby Food,Online,C,2/4/2015,547995746,2/21/2015,2974,255.28,159.42,759202.72,474115.08,285087.64
+Sub-Saharan Africa,Angola,Household,Offline,M,4/23/2011,135425221,4/27/2011,4187,668.27,502.54,2798046.49,2104134.98,693911.51
+Sub-Saharan Africa,Burkina Faso,Vegetables,Online,H,7/17/2012,871543967,7/27/2012,8082,154.06,90.93,1245112.92,734896.26,510216.66
+Sub-Saharan Africa,Republic of the Congo,Personal Care,Offline,M,7/14/2015,770463311,8/25/2015,6070,81.73,56.67,496101.10,343986.90,152114.20
+Sub-Saharan Africa,Senegal,Cereal,Online,H,4/18/2014,616607081,5/30/2014,6593,205.70,117.11,1356180.10,772106.23,584073.87
+Asia,Kyrgyzstan,Vegetables,Online,H,6/24/2011,814711606,7/12/2011,124,154.06,90.93,19103.44,11275.32,7828.12
+Sub-Saharan Africa,Cape Verde,Clothes,Offline,H,8/2/2014,939825713,8/19/2014,4168,109.28,35.84,455479.04,149381.12,306097.92
+Asia,Bangladesh,Clothes,Online,L,1/13/2017,187310731,3/1/2017,8263,109.28,35.84,902980.64,296145.92,606834.72
+Central America and the Caribbean,Honduras,Household,Offline,H,2/8/2017,522840487,2/13/2017,8974,668.27,502.54,5997054.98,4509793.96,1487261.02
+Asia,Mongolia,Personal Care,Offline,C,2/19/2014,832401311,2/23/2014,4901,81.73,56.67,400558.73,277739.67,122819.06
+Europe,Bulgaria,Clothes,Online,M,4/23/2012,972292029,6/3/2012,1673,109.28,35.84,182825.44,59960.32,122865.12
+Asia,Sri Lanka,Cosmetics,Offline,M,11/19/2016,419123971,12/18/2016,6952,437.20,263.33,3039414.40,1830670.16,1208744.24
+Sub-Saharan Africa,Cameroon,Beverages,Offline,C,4/1/2015,519820964,4/18/2015,5430,47.45,31.79,257653.50,172619.70,85033.80
+Asia,Turkmenistan,Household,Offline,L,12/30/2010,441619336,1/20/2011,3830,668.27,502.54,2559474.10,1924728.20,634745.90
+Australia and Oceania,East Timor,Meat,Online,L,7/31/2012,322067916,9/11/2012,5908,421.89,364.69,2492526.12,2154588.52,337937.60
+Europe,Norway,Baby Food,Online,L,5/14/2014,819028031,6/28/2014,7450,255.28,159.42,1901836.00,1187679.00,714157.00
+Europe,Portugal,Baby Food,Online,H,7/31/2015,860673511,9/3/2015,1273,255.28,159.42,324971.44,202941.66,122029.78
+Central America and the Caribbean,Honduras,Snacks,Online,L,6/30/2016,795490682,7/26/2016,2225,152.58,97.44,339490.50,216804.00,122686.50
+Australia and Oceania,New Zealand,Fruits,Online,H,9/8/2014,142278373,10/4/2014,2187,9.33,6.92,20404.71,15134.04,5270.67
+Europe,Moldova ,Personal Care,Online,L,5/7/2016,740147912,5/10/2016,5070,81.73,56.67,414371.10,287316.90,127054.20
+Europe,France,Cosmetics,Online,H,5/22/2017,898523128,6/5/2017,1815,437.20,263.33,793518.00,477943.95,315574.05
+Australia and Oceania,Kiribati,Fruits,Online,M,10/13/2014,347140347,11/10/2014,5398,9.33,6.92,50363.34,37354.16,13009.18
+Sub-Saharan Africa,Mali,Fruits,Online,L,5/7/2010,686048400,5/10/2010,5822,9.33,6.92,54319.26,40288.24,14031.02
+Europe,Norway,Beverages,Offline,C,7/18/2014,435608613,7/30/2014,5124,47.45,31.79,243133.80,162891.96,80241.84
+Sub-Saharan Africa,The Gambia,Household,Offline,L,5/26/2012,886494815,6/9/2012,2370,668.27,502.54,1583799.90,1191019.80,392780.10
+Europe,Switzerland,Cosmetics,Offline,M,9/17/2012,249693334,10/20/2012,8661,437.20,263.33,3786589.20,2280701.13,1505888.07
+Sub-Saharan Africa,South Sudan,Personal Care,Offline,C,12/29/2013,406502997,1/28/2014,2125,81.73,56.67,173676.25,120423.75,53252.50
+Australia and Oceania,Australia,Office Supplies,Online,C,10/27/2015,158535134,11/25/2015,2924,651.21,524.96,1904138.04,1534983.04,369155.00
+Asia,Myanmar,Household,Offline,H,1/16/2015,177713572,3/1/2015,8250,668.27,502.54,5513227.50,4145955.00,1367272.50
+Sub-Saharan Africa,Djibouti,Snacks,Online,M,2/25/2017,756274640,2/25/2017,7327,152.58,97.44,1117953.66,713942.88,404010.78
+Central America and the Caribbean,Costa Rica,Personal Care,Offline,L,5/8/2017,456767165,5/21/2017,6409,81.73,56.67,523807.57,363198.03,160609.54
+Middle East and North Africa,Syria,Fruits,Online,L,11/22/2011,162052476,12/3/2011,3784,9.33,6.92,35304.72,26185.28,9119.44
+Sub-Saharan Africa,The Gambia,Meat,Online,M,1/14/2017,825304400,1/23/2017,4767,421.89,364.69,2011149.63,1738477.23,272672.40
+Asia,Brunei,Office Supplies,Online,L,4/1/2012,320009267,5/8/2012,6708,651.21,524.96,4368316.68,3521431.68,846885.00
+Europe,Bulgaria,Office Supplies,Online,M,2/16/2012,189965903,2/28/2012,3987,651.21,524.96,2596374.27,2093015.52,503358.75
+Sub-Saharan Africa,Niger,Personal Care,Online,H,3/11/2017,699285638,3/28/2017,3015,81.73,56.67,246415.95,170860.05,75555.90
+Middle East and North Africa,Azerbaijan,Cosmetics,Online,M,2/6/2010,382392299,2/25/2010,7234,437.20,263.33,3162704.80,1904929.22,1257775.58
+Sub-Saharan Africa,The Gambia,Cereal,Offline,H,6/7/2012,994022214,6/8/2012,2117,205.70,117.11,435466.90,247921.87,187545.03
+Europe,Slovakia,Vegetables,Online,H,10/6/2012,759224212,11/10/2012,171,154.06,90.93,26344.26,15549.03,10795.23
+Asia,Myanmar,Clothes,Online,H,11/14/2015,223359620,11/18/2015,5930,109.28,35.84,648030.40,212531.20,435499.20
+Sub-Saharan Africa,Comoros,Cereal,Offline,H,3/29/2016,902102267,4/29/2016,962,205.70,117.11,197883.40,112659.82,85223.58
+Europe,Iceland,Cosmetics,Online,C,12/31/2016,331438481,12/31/2016,8867,437.20,263.33,3876652.40,2334947.11,1541705.29
+Europe,Switzerland,Personal Care,Online,M,12/23/2010,617667090,1/31/2011,273,81.73,56.67,22312.29,15470.91,6841.38
+Europe,Macedonia,Clothes,Offline,C,10/14/2014,787399423,11/14/2014,7842,109.28,35.84,856973.76,281057.28,575916.48
+Sub-Saharan Africa,Mauritania,Office Supplies,Offline,C,1/11/2012,837559306,1/13/2012,1266,651.21,524.96,824431.86,664599.36,159832.50
+Europe,Albania,Clothes,Online,C,2/2/2010,385383069,3/18/2010,2269,109.28,35.84,247956.32,81320.96,166635.36
+Sub-Saharan Africa,Lesotho,Fruits,Online,L,8/18/2013,918419539,9/18/2013,9606,9.33,6.92,89623.98,66473.52,23150.46
+Middle East and North Africa,Saudi Arabia,Cereal,Online,M,3/25/2013,844530045,3/28/2013,4063,205.70,117.11,835759.10,475817.93,359941.17
+Sub-Saharan Africa,Sierra Leone,Office Supplies,Offline,M,11/26/2011,441888415,1/7/2012,3457,651.21,524.96,2251232.97,1814786.72,436446.25
+Sub-Saharan Africa,Sao Tome and Principe,Fruits,Offline,H,9/17/2013,508980977,10/24/2013,7637,9.33,6.92,71253.21,52848.04,18405.17
+Sub-Saharan Africa,Cote d'Ivoire,Clothes,Online,C,6/8/2012,114606559,6/27/2012,3482,109.28,35.84,380512.96,124794.88,255718.08
+Australia and Oceania,Fiji,Clothes,Offline,C,6/30/2010,647876489,8/1/2010,9905,109.28,35.84,1082418.40,354995.20,727423.20
+Europe,Austria,Cosmetics,Offline,H,2/23/2015,868214595,3/2/2015,2847,437.20,263.33,1244708.40,749700.51,495007.89
+Europe,United Kingdom,Household,Online,L,1/5/2012,955357205,2/14/2012,282,668.27,502.54,188452.14,141716.28,46735.86
+Sub-Saharan Africa,Djibouti,Cosmetics,Offline,H,4/7/2014,259353148,4/19/2014,7215,437.20,263.33,3154398.00,1899925.95,1254472.05
+Australia and Oceania,Australia,Cereal,Offline,H,6/9/2013,450563752,7/2/2013,682,205.70,117.11,140287.40,79869.02,60418.38
+Europe,San Marino,Baby Food,Online,L,6/26/2013,569662845,7/1/2013,4750,255.28,159.42,1212580.00,757245.00,455335.00
+Sub-Saharan Africa,Cameroon,Office Supplies,Online,M,11/7/2011,177636754,11/15/2011,5518,651.21,524.96,3593376.78,2896729.28,696647.50
+Middle East and North Africa,Libya,Clothes,Offline,H,10/30/2010,705784308,11/17/2010,6116,109.28,35.84,668356.48,219197.44,449159.04
+Central America and the Caribbean,Haiti,Cosmetics,Offline,H,10/13/2013,505716836,11/16/2013,1705,437.20,263.33,745426.00,448977.65,296448.35
+Sub-Saharan Africa,Rwanda,Cosmetics,Offline,H,10/11/2013,699358165,11/25/2013,4477,437.20,263.33,1957344.40,1178928.41,778415.99
+Sub-Saharan Africa,Gabon,Personal Care,Offline,L,7/8/2012,228944623,7/9/2012,8656,81.73,56.67,707454.88,490535.52,216919.36
+Central America and the Caribbean,Belize,Clothes,Offline,M,7/25/2016,807025039,9/7/2016,5498,109.28,35.84,600821.44,197048.32,403773.12
+Europe,Lithuania,Office Supplies,Offline,H,10/24/2010,166460740,11/17/2010,8287,651.21,524.96,5396577.27,4350343.52,1046233.75
+Sub-Saharan Africa,Madagascar,Clothes,Offline,L,4/25/2015,610425555,5/28/2015,7342,109.28,35.84,802333.76,263137.28,539196.48
+Asia,Turkmenistan,Office Supplies,Online,M,4/23/2013,462405812,5/20/2013,5010,651.21,524.96,3262562.10,2630049.60,632512.50
+Middle East and North Africa,Libya,Fruits,Online,L,8/14/2015,816200339,9/30/2015,673,9.33,6.92,6279.09,4657.16,1621.93
+Sub-Saharan Africa,Democratic Republic of the Congo,Beverages,Online,C,5/26/2011,585920464,7/15/2011,5741,47.45,31.79,272410.45,182506.39,89904.06
+Sub-Saharan Africa,Djibouti,Cereal,Online,H,5/20/2017,555990016,6/17/2017,8656,205.70,117.11,1780539.20,1013704.16,766835.04
+Middle East and North Africa,Pakistan,Cosmetics,Offline,L,7/5/2013,231145322,8/16/2013,9892,437.20,263.33,4324782.40,2604860.36,1719922.04
+North America,Mexico,Household,Offline,C,11/6/2014,986435210,12/12/2014,6954,668.27,502.54,4647149.58,3494663.16,1152486.42
+Australia and Oceania,Federated States of Micronesia,Beverages,Online,C,10/28/2014,217221009,11/15/2014,9379,47.45,31.79,445033.55,298158.41,146875.14
+Asia,Laos,Vegetables,Offline,C,9/15/2011,789176547,10/23/2011,3732,154.06,90.93,574951.92,339350.76,235601.16
+Europe,Monaco,Baby Food,Offline,H,5/29/2012,688288152,6/2/2012,8614,255.28,159.42,2198981.92,1373243.88,825738.04
+Australia and Oceania,Samoa ,Cosmetics,Online,H,7/20/2013,670854651,8/7/2013,9654,437.20,263.33,4220728.80,2542187.82,1678540.98
+Europe,Spain,Household,Offline,L,10/21/2012,213487374,11/30/2012,4513,668.27,502.54,3015902.51,2267963.02,747939.49
+Middle East and North Africa,Lebanon,Clothes,Online,L,9/18/2012,663110148,10/8/2012,7884,109.28,35.84,861563.52,282562.56,579000.96
+Middle East and North Africa,Iran,Cosmetics,Online,H,11/15/2016,286959302,12/8/2016,6489,437.20,263.33,2836990.80,1708748.37,1128242.43
+Sub-Saharan Africa,Zambia,Snacks,Online,L,1/4/2011,122583663,1/5/2011,4085,152.58,97.44,623289.30,398042.40,225246.90
+Sub-Saharan Africa,Kenya,Vegetables,Online,L,3/18/2012,827844560,4/7/2012,6457,154.06,90.93,994765.42,587135.01,407630.41
+North America,Mexico,Personal Care,Offline,L,2/17/2012,430915820,3/20/2012,6422,81.73,56.67,524870.06,363934.74,160935.32
+Sub-Saharan Africa,Sao Tome and Principe,Beverages,Offline,C,1/16/2011,180283772,1/21/2011,8829,47.45,31.79,418936.05,280673.91,138262.14
+Sub-Saharan Africa,The Gambia,Baby Food,Offline,M,2/3/2014,494747245,3/20/2014,5559,255.28,159.42,1419101.52,886215.78,532885.74
+Middle East and North Africa,Kuwait,Fruits,Online,M,4/30/2012,513417565,5/18/2012,522,9.33,6.92,4870.26,3612.24,1258.02
+Europe,Slovenia,Beverages,Offline,C,10/23/2016,345718562,11/25/2016,4660,47.45,31.79,221117.00,148141.40,72975.60
+Sub-Saharan Africa,Sierra Leone,Office Supplies,Offline,H,12/6/2016,621386563,12/14/2016,948,651.21,524.96,617347.08,497662.08,119685.00
+Australia and Oceania,Australia,Beverages,Offline,H,7/7/2014,240470397,7/11/2014,9389,47.45,31.79,445508.05,298476.31,147031.74
+Middle East and North Africa,Azerbaijan,Office Supplies,Online,M,6/13/2012,423331391,7/24/2012,2021,651.21,524.96,1316095.41,1060944.16,255151.25
+Europe,Romania,Cosmetics,Online,H,11/26/2010,660643374,12/25/2010,7910,437.20,263.33,3458252.00,2082940.30,1375311.70
+Central America and the Caribbean,Nicaragua,Beverages,Offline,C,2/8/2011,963392674,3/21/2011,8156,47.45,31.79,387002.20,259279.24,127722.96
+Sub-Saharan Africa,Mali,Clothes,Online,M,7/26/2011,512878119,9/3/2011,888,109.28,35.84,97040.64,31825.92,65214.72
+Asia,Malaysia,Fruits,Offline,L,11/11/2011,810711038,12/28/2011,6267,9.33,6.92,58471.11,43367.64,15103.47
+Sub-Saharan Africa,Sierra Leone,Vegetables,Offline,C,6/1/2016,728815257,6/29/2016,1485,154.06,90.93,228779.10,135031.05,93748.05
+North America,Mexico,Personal Care,Offline,M,7/30/2015,559427106,8/8/2015,5767,81.73,56.67,471336.91,326815.89,144521.02
+Sub-Saharan Africa,Mozambique,Household,Offline,L,2/10/2012,665095412,2/15/2012,5367,668.27,502.54,3586605.09,2697132.18,889472.91
diff --git a/texera.wiki/statics/files/Workflow-step-1.png b/texera.wiki/statics/files/Workflow-step-1.png
new file mode 100644
index 00000000000..faac96eb992
Binary files /dev/null and b/texera.wiki/statics/files/Workflow-step-1.png differ
diff --git a/texera.wiki/statics/files/Workflow-step-2.png b/texera.wiki/statics/files/Workflow-step-2.png
new file mode 100644
index 00000000000..22bc7a6c7a4
Binary files /dev/null and b/texera.wiki/statics/files/Workflow-step-2.png differ
diff --git a/texera.wiki/statics/files/Workflow-step-3.png b/texera.wiki/statics/files/Workflow-step-3.png
new file mode 100644
index 00000000000..c42481a2cec
Binary files /dev/null and b/texera.wiki/statics/files/Workflow-step-3.png differ
diff --git a/texera.wiki/statics/files/Workflow-step-4.png b/texera.wiki/statics/files/Workflow-step-4.png
new file mode 100644
index 00000000000..daa429bebf4
Binary files /dev/null and b/texera.wiki/statics/files/Workflow-step-4.png differ
diff --git a/texera.wiki/statics/gifs/add-aggregation-operator.gif b/texera.wiki/statics/gifs/add-aggregation-operator.gif
new file mode 100644
index 00000000000..9dec093d480
Binary files /dev/null and b/texera.wiki/statics/gifs/add-aggregation-operator.gif differ
diff --git a/texera.wiki/statics/gifs/add-csv-scan-operator.gif b/texera.wiki/statics/gifs/add-csv-scan-operator.gif
new file mode 100644
index 00000000000..a594474ead3
Binary files /dev/null and b/texera.wiki/statics/gifs/add-csv-scan-operator.gif differ
diff --git a/texera.wiki/statics/gifs/add-regular-expression-operator.gif b/texera.wiki/statics/gifs/add-regular-expression-operator.gif
new file mode 100644
index 00000000000..ea2bf2f558b
Binary files /dev/null and b/texera.wiki/statics/gifs/add-regular-expression-operator.gif differ
diff --git a/texera.wiki/statics/gifs/add-view-result-and-run.gif b/texera.wiki/statics/gifs/add-view-result-and-run.gif
new file mode 100644
index 00000000000..433751c3340
Binary files /dev/null and b/texera.wiki/statics/gifs/add-view-result-and-run.gif differ
diff --git a/texera.wiki/statics/images/texera-web-ui-overview.png b/texera.wiki/statics/images/texera-web-ui-overview.png
new file mode 100644
index 00000000000..2fe6e09c618
Binary files /dev/null and b/texera.wiki/statics/images/texera-web-ui-overview.png differ
+
+### 2/3/2019
+Version 0.3.0
+
+third version of Texera GUI written in Angular CLI, with more modularized code base. [Issue #603](https://github.com/Texera/texera/issues/603)
+
+
+### 8/31/2017
+Version 0.2.3
+
+adding result bar, operator icon, and dropdown menu to second version. [PR #554](https://github.com/Texera/texera/pull/554)
+
+
+### 5/30/2017
+Version 0.2.2
+
+initial autocomplete feature [PR #505](https://github.com/Texera/texera/pull/505)
+
+
+### 5/7/2017
+Version 0.2.1
+
+updated color of second version [PR #481](https://github.com/Texera/texera/pull/481)
+
+
+### 4/27/2017
+Version 0.2.0
+
+second version written in Angular [Issue #327](https://github.com/Texera/texera/issues/327)
+
+
+### 2/6/2017
+Version 0.1.1
+
+updated color of first version [PR #366](https://github.com/Texera/texera/pull/366)
+
+
+### 11/28/2016:
+Version 0.1.0
+
+first version in plain JS [PR #301](https://github.com/Texera/texera/pull/301)
+
diff --git a/texera.wiki/[VOTE]-Release-Apache-Texera-(incubating)-Email-Template.md b/texera.wiki/[VOTE]-Release-Apache-Texera-(incubating)-Email-Template.md
new file mode 100644
index 00000000000..aff804fe84b
--- /dev/null
+++ b/texera.wiki/[VOTE]-Release-Apache-Texera-(incubating)-Email-Template.md
@@ -0,0 +1,85 @@
+Subject: [VOTE] Release Apache Texera (incubating) ${VERSION} RC${RC_NUM}
+
+Hi Texera Community,
+
+This is a call for vote to release Apache Texera (incubating) ${VERSION}.
+
+== Release Candidate Artifacts ==
+
+The release candidate artifacts can be found at:
+https://dist.apache.org/repos/dist/dev/incubator/texera/${RC_DIR}/
+
+The artifacts include:
+- apache-texera-${VERSION}-rc${RC_NUM}-src.tar.gz (source tarball)
+- apache-texera-${VERSION}-rc${RC_NUM}-src.tar.gz.asc (GPG signature)
+- apache-texera-${VERSION}-rc${RC_NUM}-src.tar.gz.sha512 (SHA512 checksum)
+
+== Git Tag ==
+
+The Git tag for this release candidate:
+https://github.com/apache/incubator-texera/releases/tag/${TAG_NAME}
+
+The commit hash for this tag:
+${COMMIT_HASH}
+
+== Release Notes ==
+
+Release notes can be found at:
+https://github.com/apache/incubator-texera/releases/tag/${TAG_NAME}
+
+== Keys ==
+
+The artifacts have been signed with Key [${GPG_KEY_ID}], corresponding to [${GPG_EMAIL}].
+
+The KEYS file containing the public keys can be found at:
+https://dist.apache.org/repos/dist/dev/incubator/texera/KEYS
+
+== How to Verify ==
+
+1. Download the release artifacts:
+
+ wget https://dist.apache.org/repos/dist/dev/incubator/texera/${RC_DIR}/apache-texera-${VERSION}-rc${RC_NUM}-src.tar.gz
+ wget https://dist.apache.org/repos/dist/dev/incubator/texera/${RC_DIR}/apache-texera-${VERSION}-rc${RC_NUM}-src.tar.gz.asc
+ wget https://dist.apache.org/repos/dist/dev/incubator/texera/${RC_DIR}/apache-texera-${VERSION}-rc${RC_NUM}-src.tar.gz.sha512
+
+2. Import the KEYS file and verify the GPG signature:
+
+ wget https://dist.apache.org/repos/dist/dev/incubator/texera/KEYS
+ gpg --import KEYS
+ gpg --verify apache-texera-${VERSION}-rc${RC_NUM}-src.tar.gz.asc apache-texera-${VERSION}-rc${RC_NUM}-src.tar.gz
+
+3. Verify the SHA512 checksum:
+
+ sha512sum -c apache-texera-${VERSION}-rc${RC_NUM}-src.tar.gz.sha512
+
+4. Extract and build from source:
+
+ tar -xzf apache-texera-${VERSION}-rc${RC_NUM}-src.tar.gz
+ cd apache-texera-${VERSION}-rc${RC_NUM}-src
+ # Follow build instructions in README
+
+== How to Vote ==
+
+The vote will be open for at least 72 hours.
+
+Please vote accordingly:
+
+[ ] +1 Approve the release
+[ ] 0 No opinion
+[ ] -1 Disapprove the release (please provide the reason)
+
+== Checklist for Reference ==
+
+When reviewing, please check:
+
+[ ] Download links are valid
+[ ] Checksums and PGP signatures are valid
+[ ] LICENSE and NOTICE files are correct
+[ ] All files have ASF license headers where appropriate
+[ ] No unexpected binary files
+[ ] Source tarball matches the Git tag
+[ ] Can compile from source successfully
+
+Thanks,
+[Your Name]
+Apache Texera (incubating) PPMC
\ No newline at end of file
diff --git a/texera.wiki/_Footer.md b/texera.wiki/_Footer.md
new file mode 100644
index 00000000000..25cea8adf0b
--- /dev/null
+++ b/texera.wiki/_Footer.md
@@ -0,0 +1 @@
+Copyright © 2025 The Apache Software Foundation.
\ No newline at end of file
diff --git a/texera.wiki/_Sidebar.md b/texera.wiki/_Sidebar.md
new file mode 100644
index 00000000000..3ef45d694ee
--- /dev/null
+++ b/texera.wiki/_Sidebar.md
@@ -0,0 +1,11 @@
+Getting Started
+* [Step 0 - Guide to Use Texera](https://github.com/apache/texera/wiki/Guide-for-how-to-use-Texera)
+* [Step 1 - Guide for Developers](https://github.com/apache/texera/wiki/Guide-for-Developers)
+
+Implementing an Operator
+* [Step 2 - Guide to Implement a Java Native Operator](https://github.com/apache/texera/wiki/Guide-to-Implement-a-Java-Native-Operator)
+* [Step 3 - Guide to Use a Python UDF](https://github.com/apache/texera/wiki/Guide-to-Use-a-Python-UDF)
+* [Step 4 - Guide to Implement a Python Native Operator](https://github.com/apache/texera/wiki/Guide-to-Implement-a-Python-Native-Operator-(converting-from-a-Python-UDF))
+
+Contributing to the Project
+* [Step 5 - Guide to Raise a Pull Request (PR)](https://github.com/apache/texera/blob/main/CONTRIBUTING.md)
diff --git a/texera.wiki/statics/files/CountrySalesData.csv b/texera.wiki/statics/files/CountrySalesData.csv
new file mode 100644
index 00000000000..99dd238fd48
--- /dev/null
+++ b/texera.wiki/statics/files/CountrySalesData.csv
@@ -0,0 +1,101 @@
+Region,Country,Item Type,Sales Channel,Order Priority,Order Date,Order ID,Ship Date,Units Sold,Unit Price,Unit Cost,Total Revenue,Total Cost,Total Profit
+Australia and Oceania,Tuvalu,Baby Food,Offline,H,5/28/2010,669165933,6/27/2010,9925,255.28,159.42,2533654.00,1582243.50,951410.50
+Central America and the Caribbean,Grenada,Cereal,Online,C,8/22/2012,963881480,9/15/2012,2804,205.70,117.11,576782.80,328376.44,248406.36
+Europe,Russia,Office Supplies,Offline,L,5/2/2014,341417157,5/8/2014,1779,651.21,524.96,1158502.59,933903.84,224598.75
+Sub-Saharan Africa,Sao Tome and Principe,Fruits,Online,C,6/20/2014,514321792,7/5/2014,8102,9.33,6.92,75591.66,56065.84,19525.82
+Sub-Saharan Africa,Rwanda,Office Supplies,Offline,L,2/1/2013,115456712,2/6/2013,5062,651.21,524.96,3296425.02,2657347.52,639077.50
+Australia and Oceania,Solomon Islands,Baby Food,Online,C,2/4/2015,547995746,2/21/2015,2974,255.28,159.42,759202.72,474115.08,285087.64
+Sub-Saharan Africa,Angola,Household,Offline,M,4/23/2011,135425221,4/27/2011,4187,668.27,502.54,2798046.49,2104134.98,693911.51
+Sub-Saharan Africa,Burkina Faso,Vegetables,Online,H,7/17/2012,871543967,7/27/2012,8082,154.06,90.93,1245112.92,734896.26,510216.66
+Sub-Saharan Africa,Republic of the Congo,Personal Care,Offline,M,7/14/2015,770463311,8/25/2015,6070,81.73,56.67,496101.10,343986.90,152114.20
+Sub-Saharan Africa,Senegal,Cereal,Online,H,4/18/2014,616607081,5/30/2014,6593,205.70,117.11,1356180.10,772106.23,584073.87
+Asia,Kyrgyzstan,Vegetables,Online,H,6/24/2011,814711606,7/12/2011,124,154.06,90.93,19103.44,11275.32,7828.12
+Sub-Saharan Africa,Cape Verde,Clothes,Offline,H,8/2/2014,939825713,8/19/2014,4168,109.28,35.84,455479.04,149381.12,306097.92
+Asia,Bangladesh,Clothes,Online,L,1/13/2017,187310731,3/1/2017,8263,109.28,35.84,902980.64,296145.92,606834.72
+Central America and the Caribbean,Honduras,Household,Offline,H,2/8/2017,522840487,2/13/2017,8974,668.27,502.54,5997054.98,4509793.96,1487261.02
+Asia,Mongolia,Personal Care,Offline,C,2/19/2014,832401311,2/23/2014,4901,81.73,56.67,400558.73,277739.67,122819.06
+Europe,Bulgaria,Clothes,Online,M,4/23/2012,972292029,6/3/2012,1673,109.28,35.84,182825.44,59960.32,122865.12
+Asia,Sri Lanka,Cosmetics,Offline,M,11/19/2016,419123971,12/18/2016,6952,437.20,263.33,3039414.40,1830670.16,1208744.24
+Sub-Saharan Africa,Cameroon,Beverages,Offline,C,4/1/2015,519820964,4/18/2015,5430,47.45,31.79,257653.50,172619.70,85033.80
+Asia,Turkmenistan,Household,Offline,L,12/30/2010,441619336,1/20/2011,3830,668.27,502.54,2559474.10,1924728.20,634745.90
+Australia and Oceania,East Timor,Meat,Online,L,7/31/2012,322067916,9/11/2012,5908,421.89,364.69,2492526.12,2154588.52,337937.60
+Europe,Norway,Baby Food,Online,L,5/14/2014,819028031,6/28/2014,7450,255.28,159.42,1901836.00,1187679.00,714157.00
+Europe,Portugal,Baby Food,Online,H,7/31/2015,860673511,9/3/2015,1273,255.28,159.42,324971.44,202941.66,122029.78
+Central America and the Caribbean,Honduras,Snacks,Online,L,6/30/2016,795490682,7/26/2016,2225,152.58,97.44,339490.50,216804.00,122686.50
+Australia and Oceania,New Zealand,Fruits,Online,H,9/8/2014,142278373,10/4/2014,2187,9.33,6.92,20404.71,15134.04,5270.67
+Europe,Moldova ,Personal Care,Online,L,5/7/2016,740147912,5/10/2016,5070,81.73,56.67,414371.10,287316.90,127054.20
+Europe,France,Cosmetics,Online,H,5/22/2017,898523128,6/5/2017,1815,437.20,263.33,793518.00,477943.95,315574.05
+Australia and Oceania,Kiribati,Fruits,Online,M,10/13/2014,347140347,11/10/2014,5398,9.33,6.92,50363.34,37354.16,13009.18
+Sub-Saharan Africa,Mali,Fruits,Online,L,5/7/2010,686048400,5/10/2010,5822,9.33,6.92,54319.26,40288.24,14031.02
+Europe,Norway,Beverages,Offline,C,7/18/2014,435608613,7/30/2014,5124,47.45,31.79,243133.80,162891.96,80241.84
+Sub-Saharan Africa,The Gambia,Household,Offline,L,5/26/2012,886494815,6/9/2012,2370,668.27,502.54,1583799.90,1191019.80,392780.10
+Europe,Switzerland,Cosmetics,Offline,M,9/17/2012,249693334,10/20/2012,8661,437.20,263.33,3786589.20,2280701.13,1505888.07
+Sub-Saharan Africa,South Sudan,Personal Care,Offline,C,12/29/2013,406502997,1/28/2014,2125,81.73,56.67,173676.25,120423.75,53252.50
+Australia and Oceania,Australia,Office Supplies,Online,C,10/27/2015,158535134,11/25/2015,2924,651.21,524.96,1904138.04,1534983.04,369155.00
+Asia,Myanmar,Household,Offline,H,1/16/2015,177713572,3/1/2015,8250,668.27,502.54,5513227.50,4145955.00,1367272.50
+Sub-Saharan Africa,Djibouti,Snacks,Online,M,2/25/2017,756274640,2/25/2017,7327,152.58,97.44,1117953.66,713942.88,404010.78
+Central America and the Caribbean,Costa Rica,Personal Care,Offline,L,5/8/2017,456767165,5/21/2017,6409,81.73,56.67,523807.57,363198.03,160609.54
+Middle East and North Africa,Syria,Fruits,Online,L,11/22/2011,162052476,12/3/2011,3784,9.33,6.92,35304.72,26185.28,9119.44
+Sub-Saharan Africa,The Gambia,Meat,Online,M,1/14/2017,825304400,1/23/2017,4767,421.89,364.69,2011149.63,1738477.23,272672.40
+Asia,Brunei,Office Supplies,Online,L,4/1/2012,320009267,5/8/2012,6708,651.21,524.96,4368316.68,3521431.68,846885.00
+Europe,Bulgaria,Office Supplies,Online,M,2/16/2012,189965903,2/28/2012,3987,651.21,524.96,2596374.27,2093015.52,503358.75
+Sub-Saharan Africa,Niger,Personal Care,Online,H,3/11/2017,699285638,3/28/2017,3015,81.73,56.67,246415.95,170860.05,75555.90
+Middle East and North Africa,Azerbaijan,Cosmetics,Online,M,2/6/2010,382392299,2/25/2010,7234,437.20,263.33,3162704.80,1904929.22,1257775.58
+Sub-Saharan Africa,The Gambia,Cereal,Offline,H,6/7/2012,994022214,6/8/2012,2117,205.70,117.11,435466.90,247921.87,187545.03
+Europe,Slovakia,Vegetables,Online,H,10/6/2012,759224212,11/10/2012,171,154.06,90.93,26344.26,15549.03,10795.23
+Asia,Myanmar,Clothes,Online,H,11/14/2015,223359620,11/18/2015,5930,109.28,35.84,648030.40,212531.20,435499.20
+Sub-Saharan Africa,Comoros,Cereal,Offline,H,3/29/2016,902102267,4/29/2016,962,205.70,117.11,197883.40,112659.82,85223.58
+Europe,Iceland,Cosmetics,Online,C,12/31/2016,331438481,12/31/2016,8867,437.20,263.33,3876652.40,2334947.11,1541705.29
+Europe,Switzerland,Personal Care,Online,M,12/23/2010,617667090,1/31/2011,273,81.73,56.67,22312.29,15470.91,6841.38
+Europe,Macedonia,Clothes,Offline,C,10/14/2014,787399423,11/14/2014,7842,109.28,35.84,856973.76,281057.28,575916.48
+Sub-Saharan Africa,Mauritania,Office Supplies,Offline,C,1/11/2012,837559306,1/13/2012,1266,651.21,524.96,824431.86,664599.36,159832.50
+Europe,Albania,Clothes,Online,C,2/2/2010,385383069,3/18/2010,2269,109.28,35.84,247956.32,81320.96,166635.36
+Sub-Saharan Africa,Lesotho,Fruits,Online,L,8/18/2013,918419539,9/18/2013,9606,9.33,6.92,89623.98,66473.52,23150.46
+Middle East and North Africa,Saudi Arabia,Cereal,Online,M,3/25/2013,844530045,3/28/2013,4063,205.70,117.11,835759.10,475817.93,359941.17
+Sub-Saharan Africa,Sierra Leone,Office Supplies,Offline,M,11/26/2011,441888415,1/7/2012,3457,651.21,524.96,2251232.97,1814786.72,436446.25
+Sub-Saharan Africa,Sao Tome and Principe,Fruits,Offline,H,9/17/2013,508980977,10/24/2013,7637,9.33,6.92,71253.21,52848.04,18405.17
+Sub-Saharan Africa,Cote d'Ivoire,Clothes,Online,C,6/8/2012,114606559,6/27/2012,3482,109.28,35.84,380512.96,124794.88,255718.08
+Australia and Oceania,Fiji,Clothes,Offline,C,6/30/2010,647876489,8/1/2010,9905,109.28,35.84,1082418.40,354995.20,727423.20
+Europe,Austria,Cosmetics,Offline,H,2/23/2015,868214595,3/2/2015,2847,437.20,263.33,1244708.40,749700.51,495007.89
+Europe,United Kingdom,Household,Online,L,1/5/2012,955357205,2/14/2012,282,668.27,502.54,188452.14,141716.28,46735.86
+Sub-Saharan Africa,Djibouti,Cosmetics,Offline,H,4/7/2014,259353148,4/19/2014,7215,437.20,263.33,3154398.00,1899925.95,1254472.05
+Australia and Oceania,Australia,Cereal,Offline,H,6/9/2013,450563752,7/2/2013,682,205.70,117.11,140287.40,79869.02,60418.38
+Europe,San Marino,Baby Food,Online,L,6/26/2013,569662845,7/1/2013,4750,255.28,159.42,1212580.00,757245.00,455335.00
+Sub-Saharan Africa,Cameroon,Office Supplies,Online,M,11/7/2011,177636754,11/15/2011,5518,651.21,524.96,3593376.78,2896729.28,696647.50
+Middle East and North Africa,Libya,Clothes,Offline,H,10/30/2010,705784308,11/17/2010,6116,109.28,35.84,668356.48,219197.44,449159.04
+Central America and the Caribbean,Haiti,Cosmetics,Offline,H,10/13/2013,505716836,11/16/2013,1705,437.20,263.33,745426.00,448977.65,296448.35
+Sub-Saharan Africa,Rwanda,Cosmetics,Offline,H,10/11/2013,699358165,11/25/2013,4477,437.20,263.33,1957344.40,1178928.41,778415.99
+Sub-Saharan Africa,Gabon,Personal Care,Offline,L,7/8/2012,228944623,7/9/2012,8656,81.73,56.67,707454.88,490535.52,216919.36
+Central America and the Caribbean,Belize,Clothes,Offline,M,7/25/2016,807025039,9/7/2016,5498,109.28,35.84,600821.44,197048.32,403773.12
+Europe,Lithuania,Office Supplies,Offline,H,10/24/2010,166460740,11/17/2010,8287,651.21,524.96,5396577.27,4350343.52,1046233.75
+Sub-Saharan Africa,Madagascar,Clothes,Offline,L,4/25/2015,610425555,5/28/2015,7342,109.28,35.84,802333.76,263137.28,539196.48
+Asia,Turkmenistan,Office Supplies,Online,M,4/23/2013,462405812,5/20/2013,5010,651.21,524.96,3262562.10,2630049.60,632512.50
+Middle East and North Africa,Libya,Fruits,Online,L,8/14/2015,816200339,9/30/2015,673,9.33,6.92,6279.09,4657.16,1621.93
+Sub-Saharan Africa,Democratic Republic of the Congo,Beverages,Online,C,5/26/2011,585920464,7/15/2011,5741,47.45,31.79,272410.45,182506.39,89904.06
+Sub-Saharan Africa,Djibouti,Cereal,Online,H,5/20/2017,555990016,6/17/2017,8656,205.70,117.11,1780539.20,1013704.16,766835.04
+Middle East and North Africa,Pakistan,Cosmetics,Offline,L,7/5/2013,231145322,8/16/2013,9892,437.20,263.33,4324782.40,2604860.36,1719922.04
+North America,Mexico,Household,Offline,C,11/6/2014,986435210,12/12/2014,6954,668.27,502.54,4647149.58,3494663.16,1152486.42
+Australia and Oceania,Federated States of Micronesia,Beverages,Online,C,10/28/2014,217221009,11/15/2014,9379,47.45,31.79,445033.55,298158.41,146875.14
+Asia,Laos,Vegetables,Offline,C,9/15/2011,789176547,10/23/2011,3732,154.06,90.93,574951.92,339350.76,235601.16
+Europe,Monaco,Baby Food,Offline,H,5/29/2012,688288152,6/2/2012,8614,255.28,159.42,2198981.92,1373243.88,825738.04
+Australia and Oceania,Samoa ,Cosmetics,Online,H,7/20/2013,670854651,8/7/2013,9654,437.20,263.33,4220728.80,2542187.82,1678540.98
+Europe,Spain,Household,Offline,L,10/21/2012,213487374,11/30/2012,4513,668.27,502.54,3015902.51,2267963.02,747939.49
+Middle East and North Africa,Lebanon,Clothes,Online,L,9/18/2012,663110148,10/8/2012,7884,109.28,35.84,861563.52,282562.56,579000.96
+Middle East and North Africa,Iran,Cosmetics,Online,H,11/15/2016,286959302,12/8/2016,6489,437.20,263.33,2836990.80,1708748.37,1128242.43
+Sub-Saharan Africa,Zambia,Snacks,Online,L,1/4/2011,122583663,1/5/2011,4085,152.58,97.44,623289.30,398042.40,225246.90
+Sub-Saharan Africa,Kenya,Vegetables,Online,L,3/18/2012,827844560,4/7/2012,6457,154.06,90.93,994765.42,587135.01,407630.41
+North America,Mexico,Personal Care,Offline,L,2/17/2012,430915820,3/20/2012,6422,81.73,56.67,524870.06,363934.74,160935.32
+Sub-Saharan Africa,Sao Tome and Principe,Beverages,Offline,C,1/16/2011,180283772,1/21/2011,8829,47.45,31.79,418936.05,280673.91,138262.14
+Sub-Saharan Africa,The Gambia,Baby Food,Offline,M,2/3/2014,494747245,3/20/2014,5559,255.28,159.42,1419101.52,886215.78,532885.74
+Middle East and North Africa,Kuwait,Fruits,Online,M,4/30/2012,513417565,5/18/2012,522,9.33,6.92,4870.26,3612.24,1258.02
+Europe,Slovenia,Beverages,Offline,C,10/23/2016,345718562,11/25/2016,4660,47.45,31.79,221117.00,148141.40,72975.60
+Sub-Saharan Africa,Sierra Leone,Office Supplies,Offline,H,12/6/2016,621386563,12/14/2016,948,651.21,524.96,617347.08,497662.08,119685.00
+Australia and Oceania,Australia,Beverages,Offline,H,7/7/2014,240470397,7/11/2014,9389,47.45,31.79,445508.05,298476.31,147031.74
+Middle East and North Africa,Azerbaijan,Office Supplies,Online,M,6/13/2012,423331391,7/24/2012,2021,651.21,524.96,1316095.41,1060944.16,255151.25
+Europe,Romania,Cosmetics,Online,H,11/26/2010,660643374,12/25/2010,7910,437.20,263.33,3458252.00,2082940.30,1375311.70
+Central America and the Caribbean,Nicaragua,Beverages,Offline,C,2/8/2011,963392674,3/21/2011,8156,47.45,31.79,387002.20,259279.24,127722.96
+Sub-Saharan Africa,Mali,Clothes,Online,M,7/26/2011,512878119,9/3/2011,888,109.28,35.84,97040.64,31825.92,65214.72
+Asia,Malaysia,Fruits,Offline,L,11/11/2011,810711038,12/28/2011,6267,9.33,6.92,58471.11,43367.64,15103.47
+Sub-Saharan Africa,Sierra Leone,Vegetables,Offline,C,6/1/2016,728815257,6/29/2016,1485,154.06,90.93,228779.10,135031.05,93748.05
+North America,Mexico,Personal Care,Offline,M,7/30/2015,559427106,8/8/2015,5767,81.73,56.67,471336.91,326815.89,144521.02
+Sub-Saharan Africa,Mozambique,Household,Offline,L,2/10/2012,665095412,2/15/2012,5367,668.27,502.54,3586605.09,2697132.18,889472.91
diff --git a/texera.wiki/statics/files/Workflow-step-1.png b/texera.wiki/statics/files/Workflow-step-1.png
new file mode 100644
index 00000000000..faac96eb992
Binary files /dev/null and b/texera.wiki/statics/files/Workflow-step-1.png differ
diff --git a/texera.wiki/statics/files/Workflow-step-2.png b/texera.wiki/statics/files/Workflow-step-2.png
new file mode 100644
index 00000000000..22bc7a6c7a4
Binary files /dev/null and b/texera.wiki/statics/files/Workflow-step-2.png differ
diff --git a/texera.wiki/statics/files/Workflow-step-3.png b/texera.wiki/statics/files/Workflow-step-3.png
new file mode 100644
index 00000000000..c42481a2cec
Binary files /dev/null and b/texera.wiki/statics/files/Workflow-step-3.png differ
diff --git a/texera.wiki/statics/files/Workflow-step-4.png b/texera.wiki/statics/files/Workflow-step-4.png
new file mode 100644
index 00000000000..daa429bebf4
Binary files /dev/null and b/texera.wiki/statics/files/Workflow-step-4.png differ
diff --git a/texera.wiki/statics/gifs/add-aggregation-operator.gif b/texera.wiki/statics/gifs/add-aggregation-operator.gif
new file mode 100644
index 00000000000..9dec093d480
Binary files /dev/null and b/texera.wiki/statics/gifs/add-aggregation-operator.gif differ
diff --git a/texera.wiki/statics/gifs/add-csv-scan-operator.gif b/texera.wiki/statics/gifs/add-csv-scan-operator.gif
new file mode 100644
index 00000000000..a594474ead3
Binary files /dev/null and b/texera.wiki/statics/gifs/add-csv-scan-operator.gif differ
diff --git a/texera.wiki/statics/gifs/add-regular-expression-operator.gif b/texera.wiki/statics/gifs/add-regular-expression-operator.gif
new file mode 100644
index 00000000000..ea2bf2f558b
Binary files /dev/null and b/texera.wiki/statics/gifs/add-regular-expression-operator.gif differ
diff --git a/texera.wiki/statics/gifs/add-view-result-and-run.gif b/texera.wiki/statics/gifs/add-view-result-and-run.gif
new file mode 100644
index 00000000000..433751c3340
Binary files /dev/null and b/texera.wiki/statics/gifs/add-view-result-and-run.gif differ
diff --git a/texera.wiki/statics/images/texera-web-ui-overview.png b/texera.wiki/statics/images/texera-web-ui-overview.png
new file mode 100644
index 00000000000..2fe6e09c618
Binary files /dev/null and b/texera.wiki/statics/images/texera-web-ui-overview.png differ