

很高興能有機會主持 CS50 的第三週的讀書會,而本周的學習重點將是帶大家認識演算法
learn how to think algorithmically
以下將針對本週的學習內容作重點整理,希望對各位有幫助😁
| method | Big O | Big Ω (Omega) |
|---|---|---|
| Linear Search | O(n) | Ω(1) |
| Binary Search | O(log n) | Ω(1) |
當我們在做搜尋的時候,課程中老師介紹了兩種常見(實用)的演算法:
- Linear Search (線性搜尋)
概念: 從頭開(或從尾)始進行,逐一查找想要的資料結果(有點像書本在翻頁,可以一頁一頁翻或兩頁兩頁翻)
適合的情境: 資料母體未經排序或整理(未建立資料的存放規則)
最佳情境: 已知欲搜尋的結果很靠近資料母體的頭尾兩側
泛用性: 如果懶得先對母體資料做整理,確實 Linear Search 不失為一個不錯的做法!
- Binary Search (二元搜尋)
概念: 從資料母體的正中間開始進行,根據前一次的搜尋結果,來決定下一次的搜尋方向,一樣從正中間的資料來驗證搜尋結果是否相符
而在搜的過程中,會持續對母體資料進行對半再對半的拆分,其目的是為了有效限縮資料的搜尋範圍(會愈縮愈小)
*二元搜尋為什麼可以是 log2 N 的曲線,礙於篇幅將不在筆記中做詳細介紹,至於為什麼 Big O 的概念不是 O(log2 N) 而是用 O(log N) 表示?
其實是 log 的曲線都長得很像,因此在 Big O 的概念中將簡單用 log 來概括其他 log2, log3, log4... 的 log 曲線
歡迎有興趣的朋友進一步觀看:

適合的情境: 資料母體的資料已經做好由小到大(或由大到小)的排序
最佳情境: 欲搜尋的資料結果剛好位於母體的正中間('請注意'不是位在附近),其次為資料剛好位在母體 1/4 或 3/4 的位置(即剛好都位在每次對半拆分母體的位置)
泛用性: 較 Linear Search 廣泛,尤其是無法事前預測使用者想搜尋什麼資料('請注意'前提是對母體資料已經做好排序)
當你程式寫一寫,需要幫資料彼此之間建立關聯時,你就會用到資料結構的概念...
沒錯!!初識資料結構,一定會覺得它長得很像諸如: key-value-pair(鍵值), JavaScript 的 Object(物件), Python 的 Dictionary(字典), Java (或 C++) 的 Class, MonogDB 的 Document(文件)...
原來看了這麼多相似的東西,其目的就是幫助兩個(或 N 個)看似不相干的資料產生關聯,再回到 C 語言
我們會使用 struct 來建立資型別(資料結構),假設我想記錄'人名'跟'電話'的關聯(也稱具有這兩個條件的資料為 person 好了)
typedef struct
{
string name;
string number;
}
person;使用的方法如下(假設我想像電話簿一樣建立多筆 person 資料):
#include <cs50.h>
#include <stdio.h>
#include <string.h>
typedef struct
{
string name;
string number;
}
person;
int main(void)
{
person people[3];
people[0].name = "Carter";
people[0].number = "+1-617-495-1000";
people[1].name = "David";
people[1].number = "+1-617-495-1000";
people[2].name = "John";
people[2].number = "+1-949-468-2750";
// Search for name
string name = get_string("Name: ");
for (int i = 0; i < 3; i++)
{
if (strcmp(people[i].name, name) == 0)
{
printf("Found %s\n", people[i].number);
return 0;
}
}
printf("Not found\n");
return 1;
}假如我只想建立一筆 person 資料:
#include <cs50.h>
#include <stdio.h>
typedef struct
{
string name;
string number;
}
person;
int main(void)
{
person p; // 聲明一個 person 型別的變數
p.name = "Alice";
p.number = "+1234567890";
printf("Name: %s\nNumber: %s\n", p.name, p.number);
return 0;
}Recursion is a concept within programming where a function calls itself.
從以下程式碼演示了 Recursion 的行為,當一個 function 會重複呼叫它自己,且將持續到符合 return 的條件為止,此行為即為 Recursion
#include <cs50.h>
#include <stdio.h>
void draw(int n);
int main(void)
{
// Get height of pyramid
int height = get_int("Height: ");
// Draw pyramid
draw(height);
}
void draw(int n)
{
// If nothing to draw
if (n <= 0)
{
return;
}
// Draw pyramid of height n - 1
draw(n - 1);
// Draw one more row of width n
for (int i = 0; i < n; i++)
{
printf("#");
}
printf("\n");
}補充:
- Recursion 的行為乍看之下會有點像 loop(迴圈) 進行迭代的過程,但差異點在於 loop(迴圈) 迭代的過程並沒有重新呼叫它自己,而是根據 loop 當時設定的條件(condition) 來進行迭代 (e.g. for loop 常見的 (int i = 0; i < n; i++) 即為 loop 設定的條件)。
- Recursion 的行為如果重複太多遍(或沒有設好 function 最終要達成 return 的條件),將會因為不斷重複呼叫,佔用過多的記憶體而導致 stack overflow; 沒錯,Recursion 一般佔用到的是 stack 的記憶體。
| method | Big O | Big Ω (Omega) | Space complexity |
|---|---|---|---|
| Selection sort | O(n²) | Ω(n²) | θ(1) |
| Bubble Sort | O(n²) | Ω(n) | θ(1) |
| Merge Sort | O(n log n) | Ω(n log n) | θ(n) |
When a list is sorted, searching that list is far less taxing on the computer.
視覺影片:
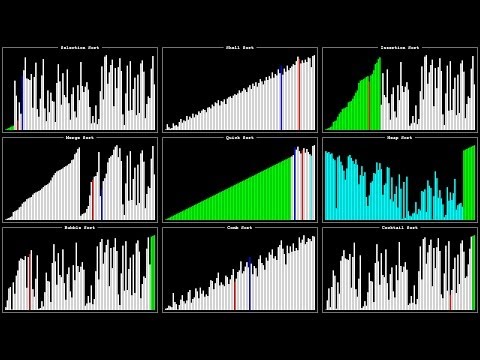
回顧本周課程內容,老師分別針對搜尋(search) 及分類(sorting) 常見且實用的幾種演算法幫同學做介紹,認識什麼是 Big O(即 the worst case), Big Omega(Ω; 即 the best case) 以及 theta(θ; means the worst and the best case at the same time.)
對筆者而言,首先看懂 O, Ω 及 θ 代表什麼意思很重要,接者才會深入研究各個演算法的規則及適合的情境有哪些(sorting 相關的演算法有非常多...)
因為最好的演算法不保證適用所有情境,而是要先理解當下的需求,並根據情境來做出適當的選擇🫰