泊松分布(Poisson Distribution)是统计学里常见的一种离散概率分布,适合描述单位时间内随机事件发生的次数。在一些常见的例子中,我们通常假设样本服从二项分布(Binomial Distribution),进而计算每次试验成功的概率。由于某些实际问题可能无法满足二项分布的一些限制性假设,而泊松模型在处理计数数据上更为灵活,因此在本章中,我们将考虑利用这一模型对计数数据进行贝叶斯分析。
泊松模型是比二项式模型更为灵活的计数模型,它由一个参数(平均数)决定,不需要二项式模型的全部假设。泊松分布经常被用来建立变量的分布模型,这些变量计算在一定时间间隔内或在一定地点发生的“相对罕见”的时间的数量(例如:一天内高速公路上发生事故的数量、一周内提出索赔的汽车保险数量、银行贷款的违约数量、DNA序列的突变数量、南加州一小时内发生的地震数量等等)。
一个离散的随机变量$Y$具有泊松分布,参数为
如果$Y$具有泊松分布,那么
$$
E(Y)=\theta{,,,,,,,}Var(Y)=\theta
$$
对于泊松分布来说,均值和方差都等于$θ$,但要记住,均值是以计数单位(如全垒打)来衡量的,而方差是以平方单位来衡量的。
泊松分布有很多很好的特性,如下所示:
泊松聚合 如果$Y_1$和$Y_2$是独立的,$Y_1$为泊松(
例 29.1 假设在美国职业棒球大联盟的某个公园里,每场比赛的本垒打数(两队的总和)服从参数为
| 0.5 | 1.5 | 2.5 | 3.5 | 4.5 | |
|---|---|---|---|---|---|
| 概率 | 0.13 | 0.45 | 0.28 | 0.11 | 0.03 |
假设观察到一场有$1$支全垒打的比赛,求出以下的后验分布$θ$ 。特别的,你如何确定似然列?
4.假设现在观察到第二场比赛,有$3$支全垒打,与第一场比赛无关。求出以下的后验分布
5.现在再次考虑原始先验。找到以下的后验分布
6.现在再考虑一下原来的先验。假设我们不观察这两个单独的数值,而只观察两场比赛中总共有4支全垒打。找到以下的后验分布
7.假设我们明天将观察第三场比赛。你如何通过分析和模拟找到这场比赛没有全垒打的后验预测概率?
8.现在让我们考虑一个连续的先验分布,即
9.现在让我们考虑一些真实的数据。假设某公园的每场比赛的全垒打遵循泊松分布,参数为
在32场比赛中,共有97支全垒打。使用网格近似法来计算$θ$的后验分布,一定要指定似然,再画出先验、似然(按比例)和后验。
| 全垒打 | 比赛数目 |
|---|---|
| 0 | 0 |
| 1 | 8 |
| 2 | 8 |
| 3 | 5 |
| 4 | 4 |
| 5 | 3 |
| 6 | 2 |
| 7 | 1 |
| 8 | 1 |
| 9 | 0 |
例29.1的解决方案
1.你的先验是什么就是什么,我们将在后面的部分讨论如何选择先验。尽管每个数值都是一个整数,但每场比赛的平均全垒打数量$θ$可以是大于$0$的任何数值,也就是说,参数$θ$的取值是连续的。
2.
3.似然是在一场比赛中出现1支全垒打的泊松概率,要对每一个
| 先验 | 似然 | 先验$\times$似然 | 后验 | |
|---|---|---|---|---|
| 0.5 | 0.13 | 0.3033 | 0.0394 | 0.1513 |
| 1.5 | 0.45 | 0.3347 | 0.1506 | 0.5779 |
| 2.5 | 0.28 | 0.2052 | 0.0575 | 0.2205 |
| 3.5 | 0.11 | 0.1057 | 0.0116 | 0.0446 |
| 4.5 | 0.03 | 0.0500 | 0.0015 | 0.0058 |
4.似然是指在一场比赛中出现3支全垒打的泊松概率,要对每一个$θ$ 值进行计算。
$$
f(y=3|\theta)=\frac{e^{-\theta}\theta^{3}}{3!}
$$
后验将有大约$90%$的概率置于
| 先验 | 似然 | 先验$\times$似然 | 后验 | |
|---|---|---|---|---|
| 0.5 | 0.1513 | 0.0126 | 0.0019 | 0.0145 |
| 1.5 | 0.5779 | 0.1255 | 0.0725 | 0.5488 |
| 2.5 | 0.2205 | 0.2138 | 0.0471 | 0.3566 |
| 3.5 | 0.0446 | 0.2158 | 0.0096 | 0.0728 |
| 4.5 | 0.0058 | 0.1687 | 0.0010 | 0.0073 |
5.由于这些游戏是独立的
,所以似然是前两部分的似然的乘积。 $$ f(y=(1,3)|\theta)=(\frac{e^{-\theta}\theta^{1}}{1!})(\frac{e^{-\theta}\theta^{3}}{3!}) $$
| 先验 | 似然 | 先验$\times$似然 | 后验 | |
|---|---|---|---|---|
| 0.5 | 0.13 | 0.0038 | 0.0005 | 0.0145 |
| 1.5 | 0.45 | 0.0420 | 0.0189 | 0.5488 |
| 2.5 | 0.28 | 0.0439 | 0.0123 | 0.3566 |
| 3.5 | 0.11 | 0.0228 | 0.0025 | 0.0728 |
| 4.5 | 0.03 | 0.0084 | 0.0003 | 0.0073 |
6.通过泊松聚合,两场比赛的总本垒打数遵循泊松$(2\theta)$分布,似然是对$\theta$的每个值使用泊松$( 2,θ )
| 先验 | 似然 | 先验$\times$似然 | 后验 | |
|---|---|---|---|---|
| 0.5 | 0.13 | 0.0153 | 0.0020 | 0.0145 |
| 1.5 | 0.45 | 0.1680 | 0.0756 | 0.5488 |
| 2.5 | 0.28 | 0.1755 | 0.0491 | 0.3566 |
| 3.5 | 0.11 | 0.0912 | 0.0100 | 0.0728 |
| 4.5 | 0.03 | 0.0337 | 0.0010 | 0.0073 |
- 从$\theta$的后验分布中模拟出一个值,然后给定$\theta$,从泊松$(\theta)$分布中模拟出一个$Y$值,并重复多次。通过找到产生$Y$值为$0$的重复的比例来近似计算$0$全垒打的概率。我们可以用总概率定律来计算这个概率,找出$\theta —e^{-\theta}\theta^{0}/0!=e^{-\theta}—$的每个值的0全垒打的概率,然后用它们的后验概率对这些值进行加权,找出0全垒打的预测概率,即$0.163$。
8.现在让我们考虑一个连续的先验分布,即$\theta$的连续先验分布,它满足
$$
\pi (\theta)\propto ,\theta ^{4-1}e^{-2\theta },{,,,,,,,,}\theta >0
$$
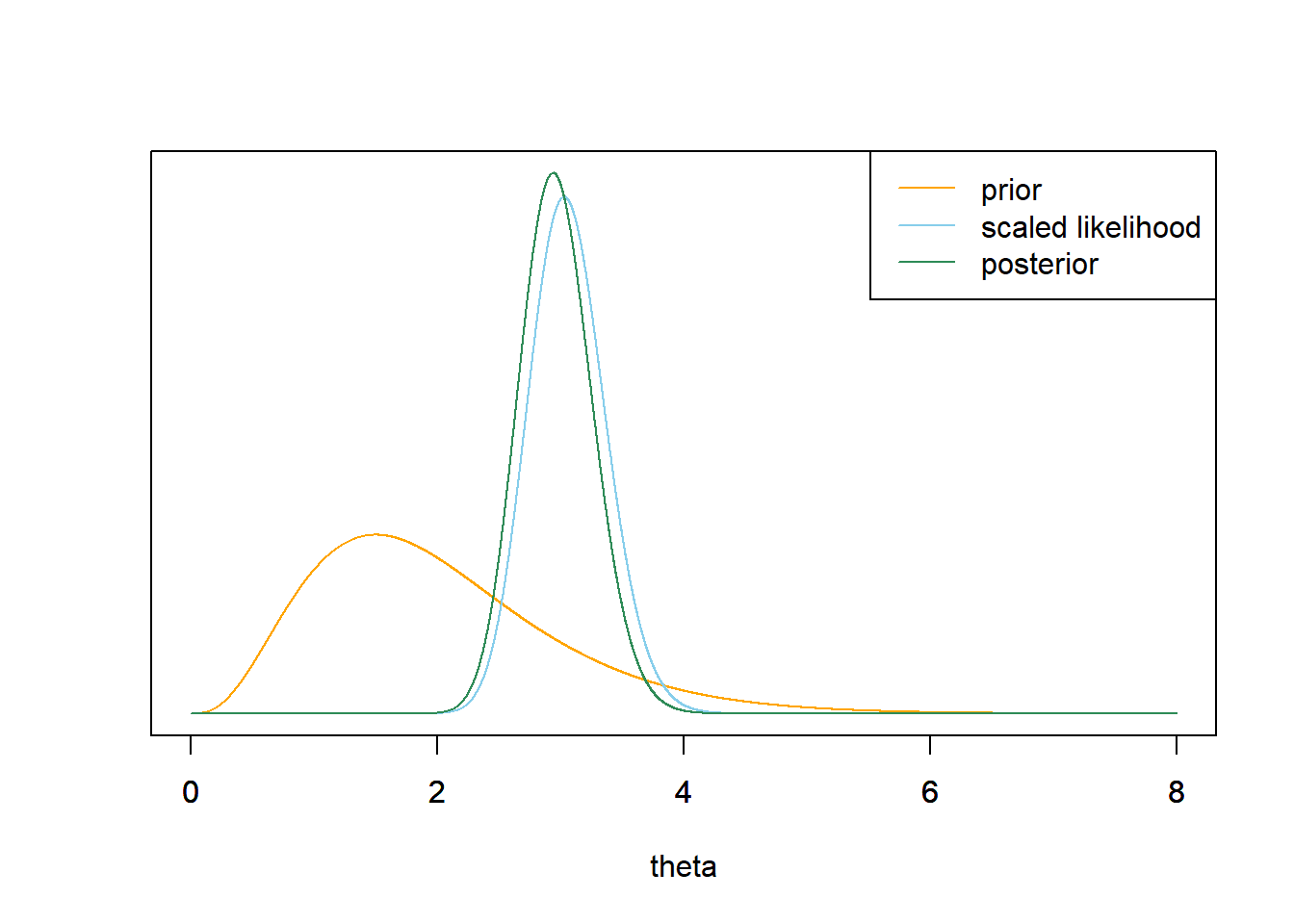
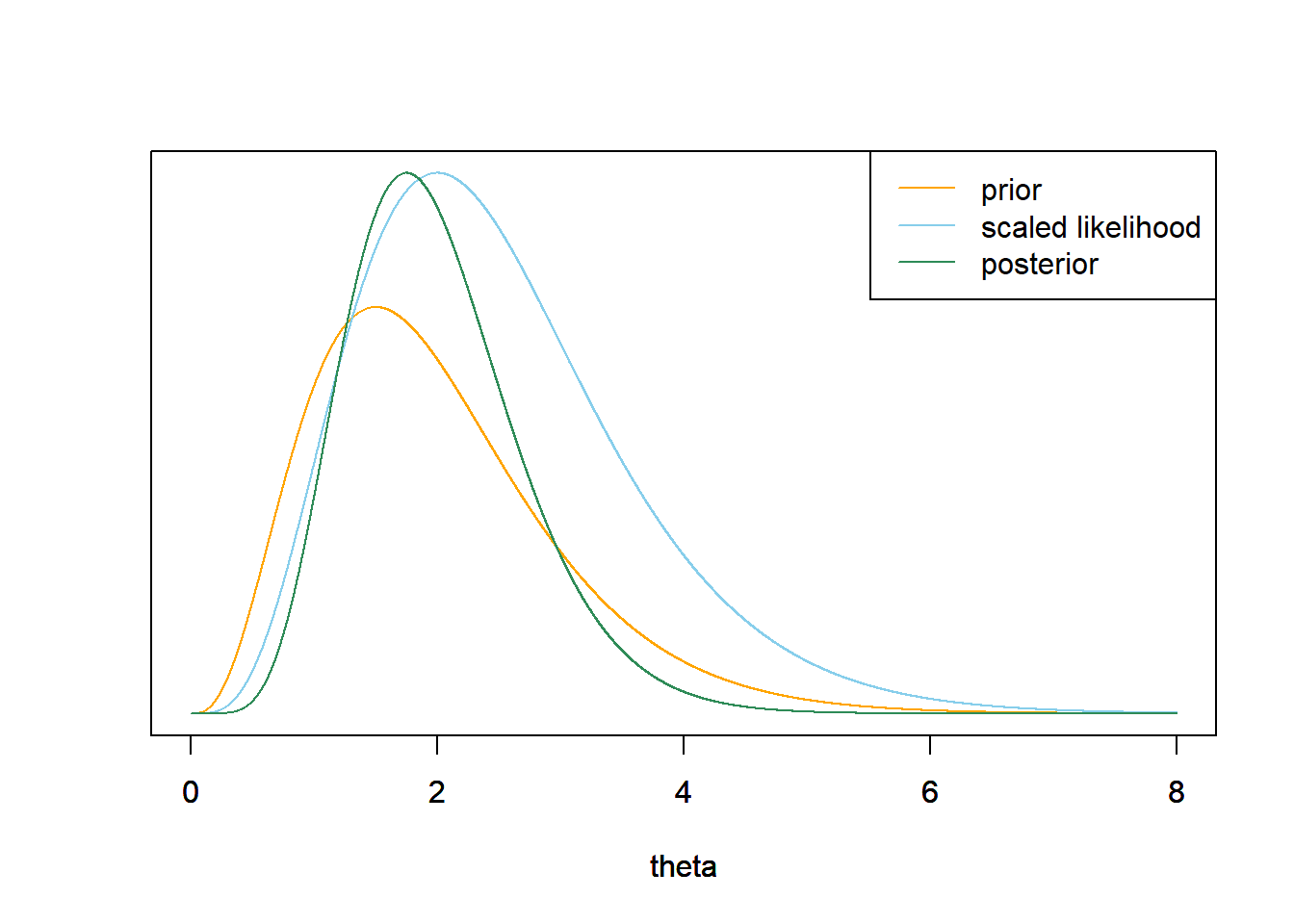
使用网格近似法来计算单场比赛中的1支全垒打的$\theta$的后验分布。绘出先验、似然(按比例)和后验。(注意:你将需要在某些时候把网格切断。虽然
# prior
theta = seq(0, 8, 0.001)
prior = theta ^ (4 - 1) * exp(-2 * theta)
prior = prior / sum(prior)
# data
n = 1 # sample size
y = 1 # sample mean
# likelihood
likelihood = dpois(y, theta)
# posterior
product = likelihood * prior
posterior = product / sum(product)
ylim = c(0, max(c(prior, posterior, likelihood / sum(likelihood))))
xlim = range(theta)
plot(theta, prior, type='l', xlim=xlim, ylim=ylim, col="orange", xlab='theta', ylab='', yaxt='n')
par(new=T)
plot(theta, likelihood/sum(likelihood), type='l', xlim=xlim, ylim=ylim, col="skyblue", xlab='', ylab='', yaxt='n')
par(new=T)
plot(theta, posterior, type='l', xlim=xlim, ylim=ylim, col="seagreen", xlab='', ylab='', yaxt='n')
legend("topright", c("prior", "scaled likelihood", "posterior"), lty=1, col=c("orange", "skyblue", "seagreen"))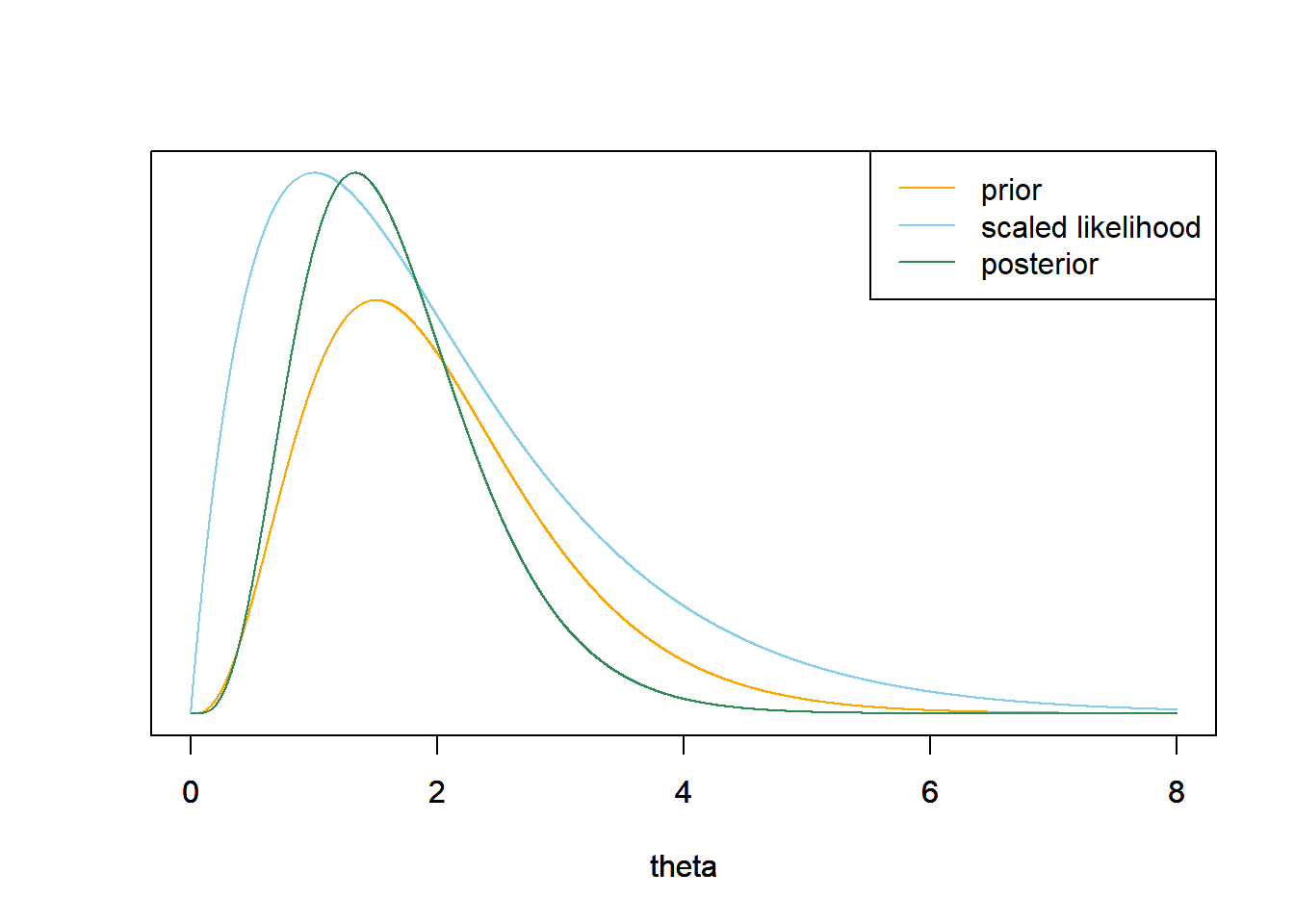
9.通过泊松聚合,32场比赛的总本垒打数遵循泊松(
似然是以$$97/32=3.03$$的样本平均值为中心,后验分布与似然相当接近,但先验仍存在一点影响。
# prior
theta = seq(0, 8, 0.001)
prior = theta ^ (4 - 1) * exp(-2 * theta)
prior = prior / sum(prior)
# data
n = 32 # sample size
y = 97 / 32 # sample mean
# likelihood - for total count
likelihood = dpois(n * y, n * theta)
# posterior
product = likelihood * prior
posterior = product / sum(product)
ylim = c(0, max(c(prior, posterior, likelihood / sum(likelihood))))
xlim = range(theta)
plot(theta, prior, type='l', xlim=xlim, ylim=ylim, col="orange", xlab='theta', ylab='', yaxt='n')
par(new=T)
plot(theta, likelihood/sum(likelihood), type='l', xlim=xlim, ylim=ylim, col="skyblue", xlab='', ylab='', yaxt='n')
par(new=T)
plot(theta, posterior, type='l', xlim=xlim, ylim=ylim, col="seagreen", xlab='', ylab='', yaxt='n')
legend("topright", c("prior", "scaled likelihood", "posterior"), lty=1, col=c("orange", "skyblue", "seagreen"))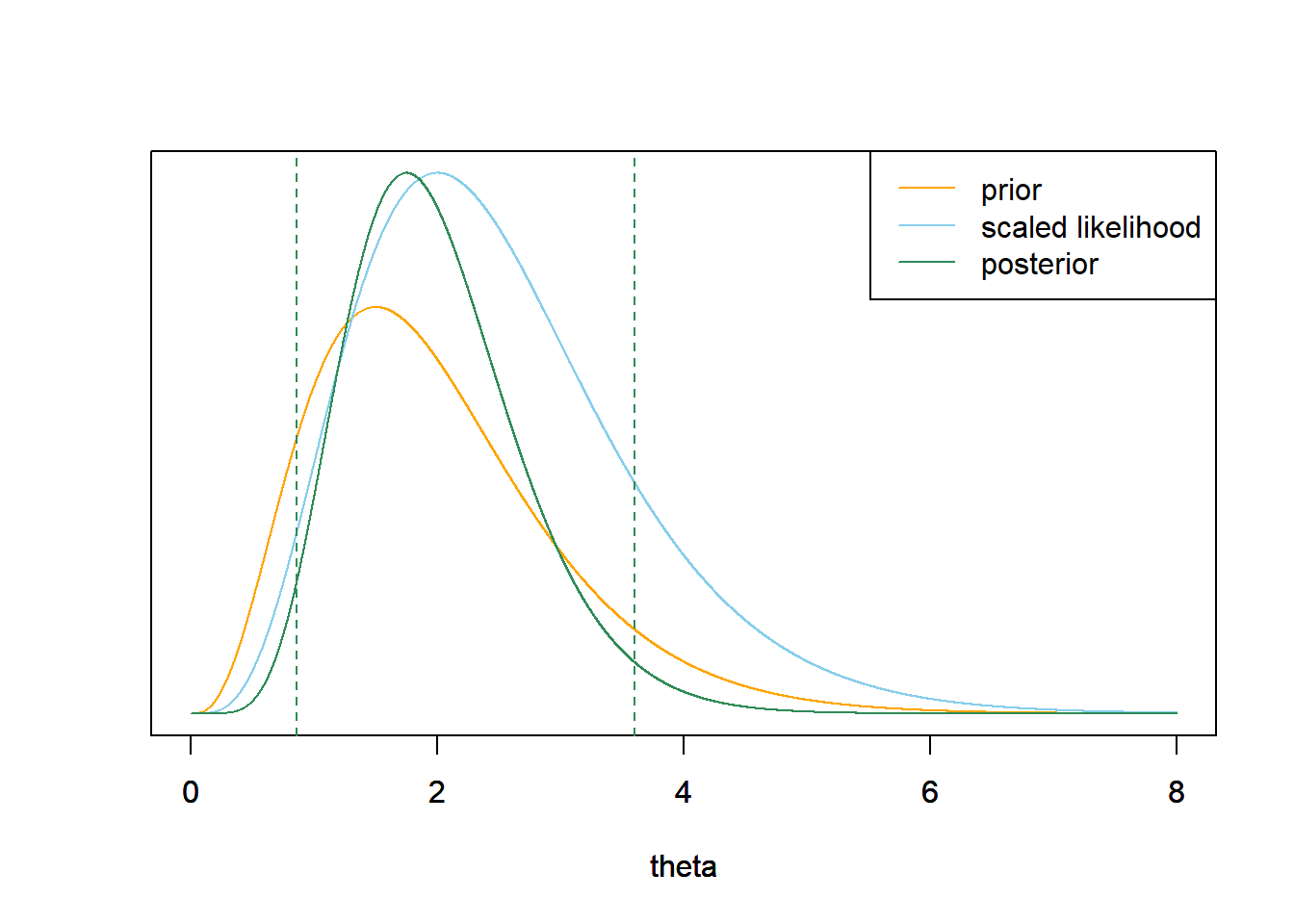
在泊松计数的贝叶斯分析中,通常使用 **伽马分布(Gamma Distribution)**作为先验分布。如果一个连续的RV
在R中:dgamma(u, shape, rate)表示密度,rgamma表示模拟,qgamma表示量纲……
可以证明,一个$$Gamma(α, λ)$$密度有
## Traceback (most recent call last):
## File "C:\Users\kjross\ANACON~2\lib\site-packages\matplotlib\backends\backend_qt5.py", line 508, in _draw_idle
## self.draw()
## File "C:\Users\kjross\ANACON~2\lib\site-packages\matplotlib\backends\backend_agg.py", line 388, in draw
## self.figure.draw(self.renderer)
## File "C:\Users\kjross\ANACON~2\lib\site-packages\matplotlib\artist.py", line 38, in draw_wrapper
## return draw(artist, renderer, *args, **kwargs)
## File "C:\Users\kjross\ANACON~2\lib\site-packages\matplotlib\figure.py", line 1709, in draw
## renderer, self, artists, self.suppressComposite)
## File "C:\Users\kjross\ANACON~2\lib\site-packages\matplotlib\image.py", line 135, in _draw_list_compositing_images
## a.draw(renderer)
## File "C:\Users\kjross\ANACON~2\lib\site-packages\matplotlib\artist.py", line 38, in draw_wrapper
## return draw(artist, renderer, *args, **kwargs)
## File "C:\Users\kjross\ANACON~2\lib\site-packages\matplotlib\axes\_base.py", line 2607, in draw
## self._update_title_position(renderer)
## File "C:\Users\kjross\ANACON~2\lib\site-packages\matplotlib\axes\_base.py", line 2548, in _update_title_position
## ax.xaxis.get_ticks_position() in choices):
## File "C:\Users\kjross\ANACON~2\lib\site-packages\matplotlib\axis.py", line 2146, in get_ticks_position
## self._get_ticks_position()]
## File "C:\Users\kjross\ANACON~2\lib\site-packages\matplotlib\axis.py", line 1832, in _get_ticks_position
## major = self.majorTicks[0]
## IndexError: list index out of range
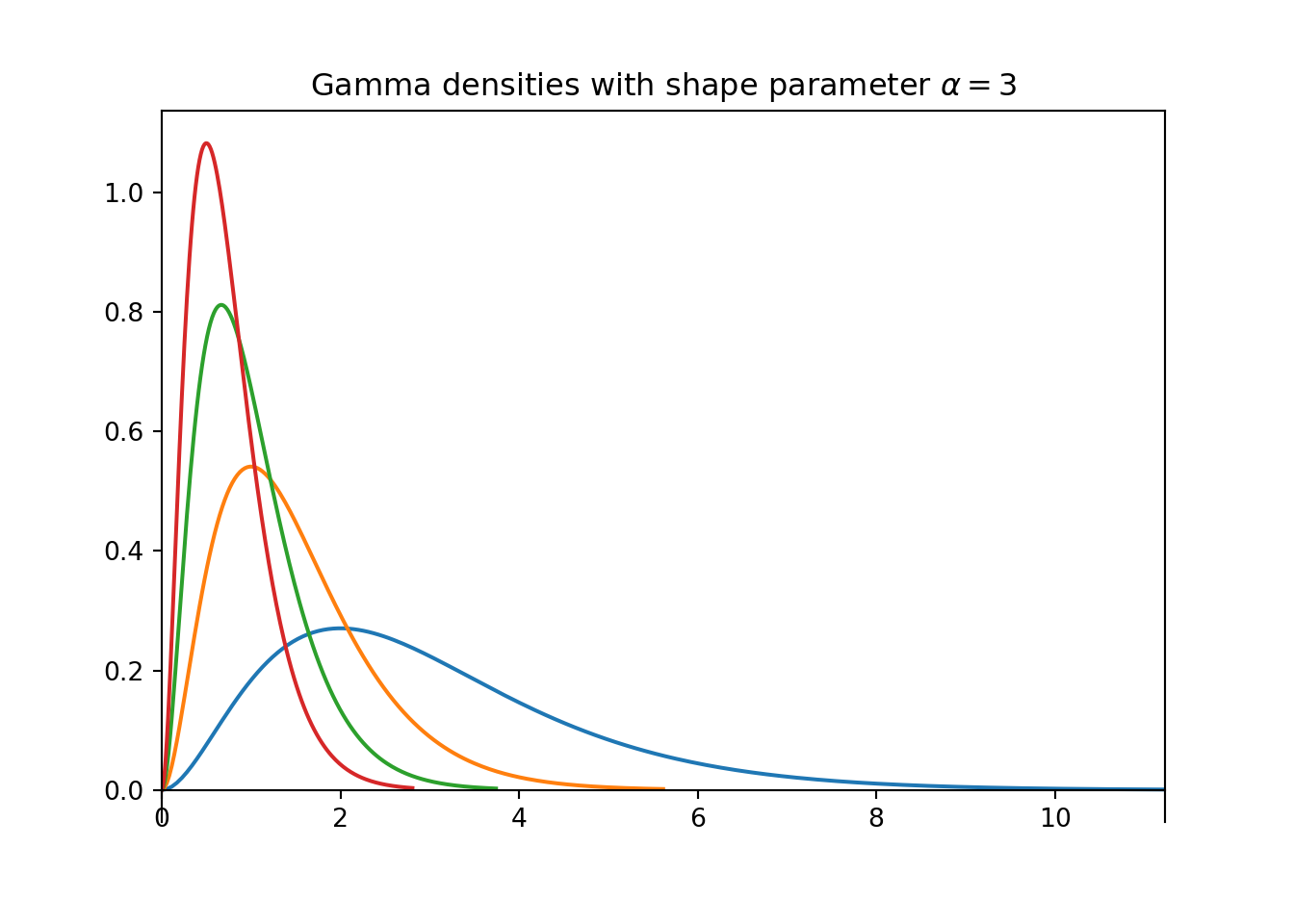
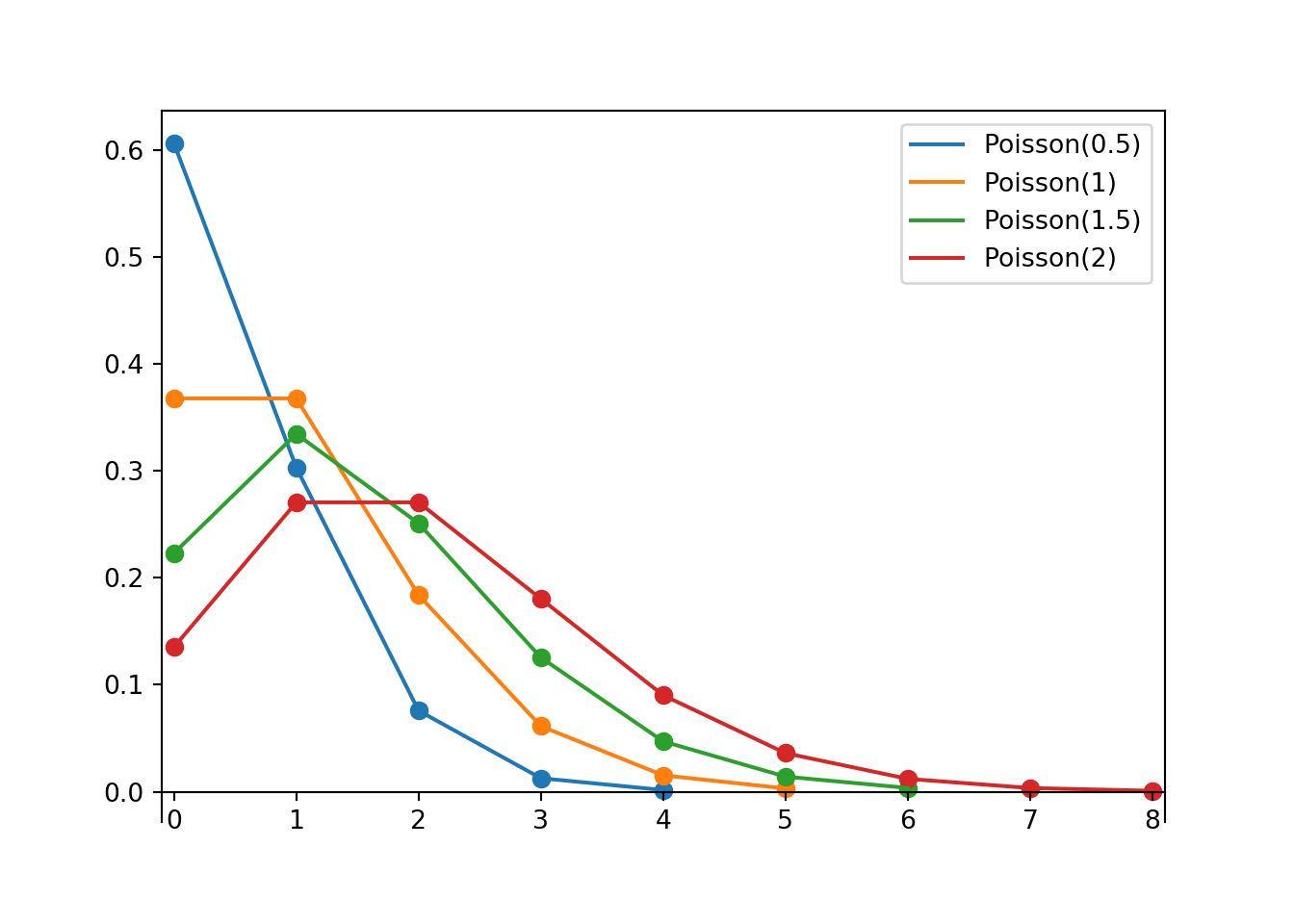
1.上面第一个图包含了一些不同的伽马密度,都有速率参数$\lambda = 1$。将每个密度与它的形状参数$\alpha$相匹配,选择是1,2,5,10。
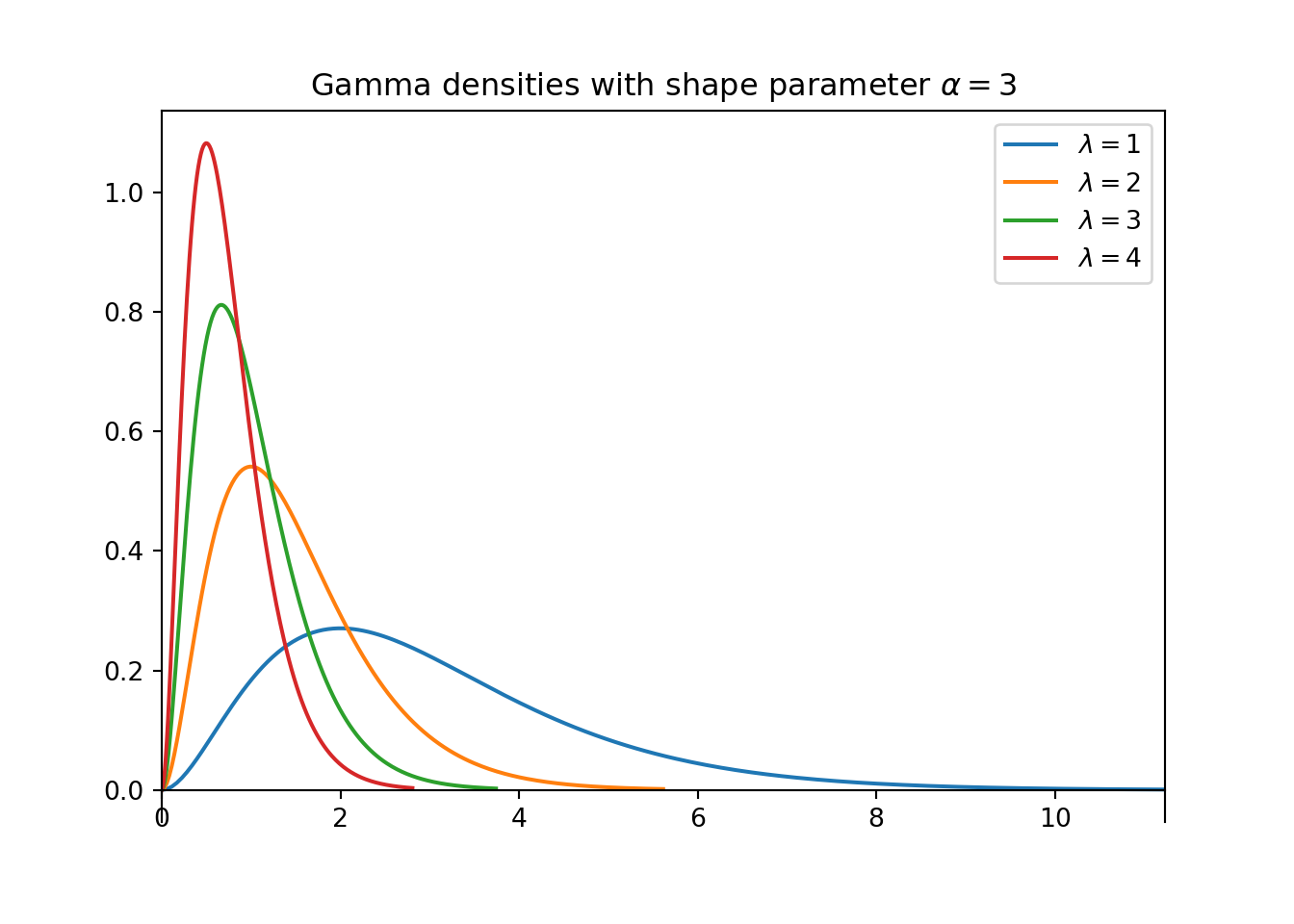
2.上面第二个图包含了几个不同的伽马密度,都有形状参数$α=3$。将每个密度与它的速率参数$$λ$$相匹配;选择是1,2,3,4。
例29.2的解决方案
1.对于固定的$$λ$$,随着形状参数$$α$$的增加,平均值和标准差都会增加。
2.对于固定的$$α$$,随着速率参数$$λ$$的增加,平均值和标准差都会下降。
请注意,改变
例29.3 假设公民银行公园每场比赛的全垒打遵循参数为$$θ$$的泊松分布。假设$$θ$$为伽马先验分布,形状参数$α=4$,速率参数$λ=2$。
1.写出先验密度的表达式$\pi (\theta)$,绘制先验分布图,求出先验的平均数、标准差和95%的置信区间。
2.假设观察到一场有1支全垒打的比赛,写出似然函数。
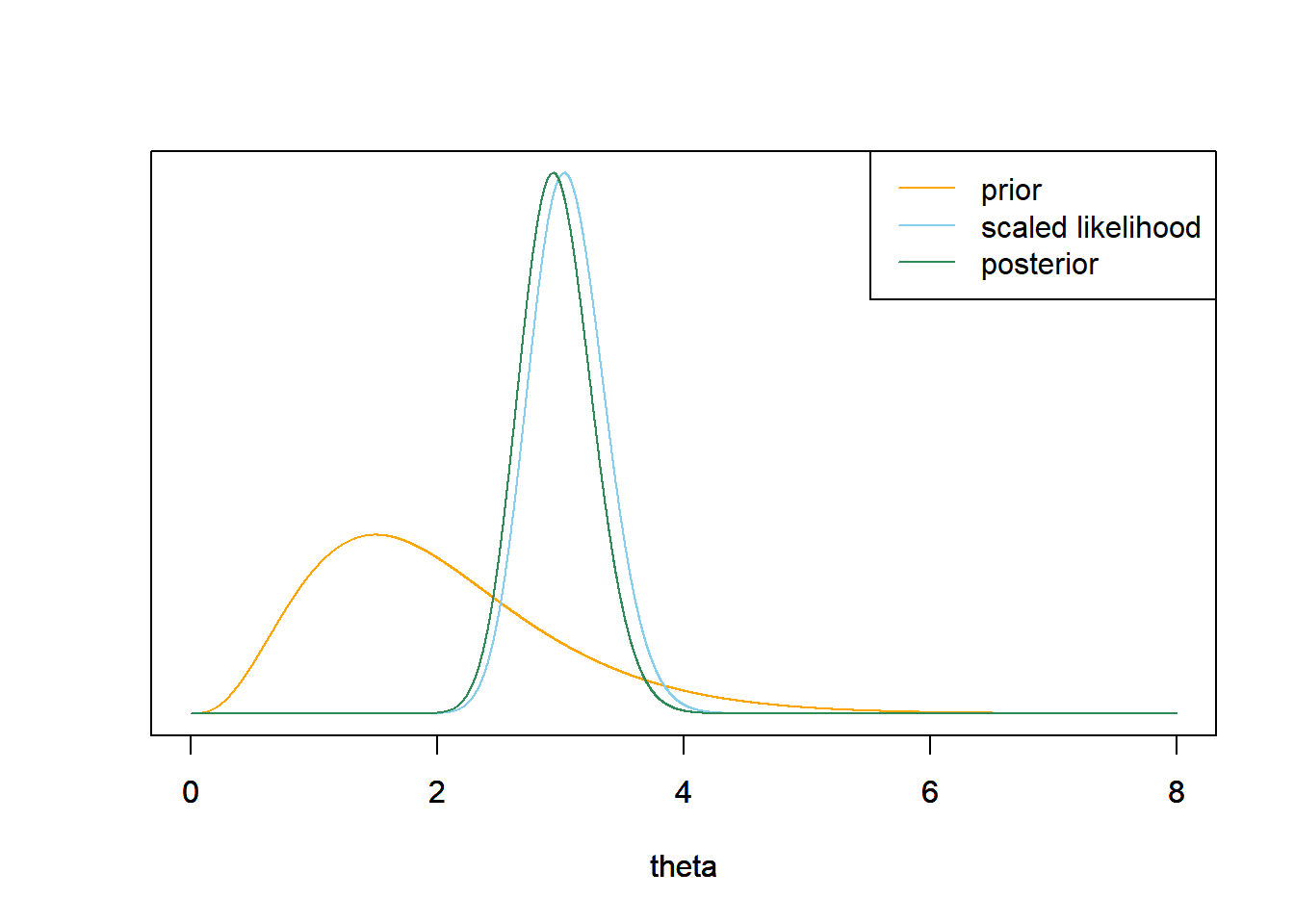
3.写出给定单场比赛有1支全垒打的$θ$的后验分布的表达式,用后验分布的名称和相关参数的值来识别。绘制先验 分布、似然(按比例)和后验分布图,找到$$θ$$的后验平均数、标准差和95%的置信区间。
4.现在再次考虑原始先验。确定在两场比赛的样本中,在第一场比赛中观察到1支全垒打和在第二场比赛中观察到3支全垒打的似然函数,以及给定这个样本的$$θ$$的后验分布,用后验分布的名称和相关参数的值来识别,绘制 先验分布、似然(按比例)和后验分布图。找到$$θ$$的后验平均数、标准差和95%的置信区间。
5.再考虑一下原来的先验。确定在两场比赛的样本中观察到总共4支全垒打的可能性,以及以下的后验分布$θ$的后验分布,用后验分布的名称和相关参数的值来识别,这与前面的部分相比有什么不同?
6.针对2020年的数据(32场比赛中有97支全垒打)来确定似然函数,以及以下$\theta$的后验分布,用后验分布的名称和相关参数的值来识别,绘制先验、似然(按比例)和后验分布图,并找出$\theta$后验平均数、标准差和95%的置信区间。
7.根据上下文来解释上一部分的置信区间。
8.基于2020年的数据,输出后验均值$\theta$ 表示为先验平均值和样本平均值的加权平均值。
例29.3的解决方案
- 注意,在伽马$$(4,2)$$先验分布中,$\theta$是作为变量来处理的。
这与我们在例29.1的网格逼近中使用的先验是一样的,请看下面的图表。 $$ Prior{,,}mean=\frac{\alpha}{\lambda}{,,,,,,,,,,,}\frac{4}{2}=2 $$
使用qgamma查找$$95%$$先验置信区间的端点。
qgamma(c(0.025, 0.975), shape = 4, rate = 2)## [1] 0.5449327 4.3836365
2.似然是在一场比赛中出现1支全垒打的泊松概率,$\theta$均大于0。 $$ f(y=1|\theta)=\frac{e^{-\theta}\theta^{1}}{1!}\propto e^{-\theta}\theta,{,,,,,,,,}\theta> 0 $$ 3.后验正比与先验乘以似然 $$ \pi (\theta |y=1)\propto (e^{-\theta}\theta)(\theta^{4-1}e^{-2\theta}),{,,,,,,,,}\theta>0, $$
我们将上述情况视为具有形状参数$α=4+1$和速率参数$$λ=2+1$$的伽马密度。 $$ Posterior{,,}mean=\frac{\alpha}{\lambda}{,,,,,,,,,,}\frac{5}{3}=1.667 $$
qgamma(c(0.025, 0.975), shape = 4 + 1, rate = 2 + 1)## [1] 0.5411621 3.4138629
theta = seq(0, 8, 0.001) # the grid is just for plotting
# prior
alpha = 4
lambda = 2
prior = dgamma(theta, shape = alpha, rate = lambda)
# likelihood
n = 1 # sample size
y = 1 # sample mean
likelihood = dpois(n * y, n * theta)
# posterior
posterior = dgamma(theta, alpha + n * y, lambda + n)
# plot
plot_continuous_posterior <- function(theta, prior, likelihood, posterior) {
ymax = max(c(prior, posterior))
scaled_likelihood = likelihood * ymax / max(likelihood)
plot(theta, prior, type='l', col='orange', xlim= range(theta), ylim=c(0, ymax), ylab='', yaxt='n')
par(new=T)
plot(theta, scaled_likelihood, type='l', col='skyblue', xlim=range(theta), ylim=c(0, ymax), ylab='', yaxt='n')
par(new=T)
plot(theta, posterior, type='l', col='seagreen', xlim=range(theta), ylim=c(0, ymax), ylab='', yaxt='n')
legend("topright", c("prior", "scaled likelihood", "posterior"), lty=1, col=c("orange", "skyblue", "seagreen"))
}
plot_continuous_posterior(theta, prior, likelihood, posterior)
abline(v = qgamma(c(0.025, 0.975), alpha + n * y, lambda + n),
col = "seagreen", lty = 2)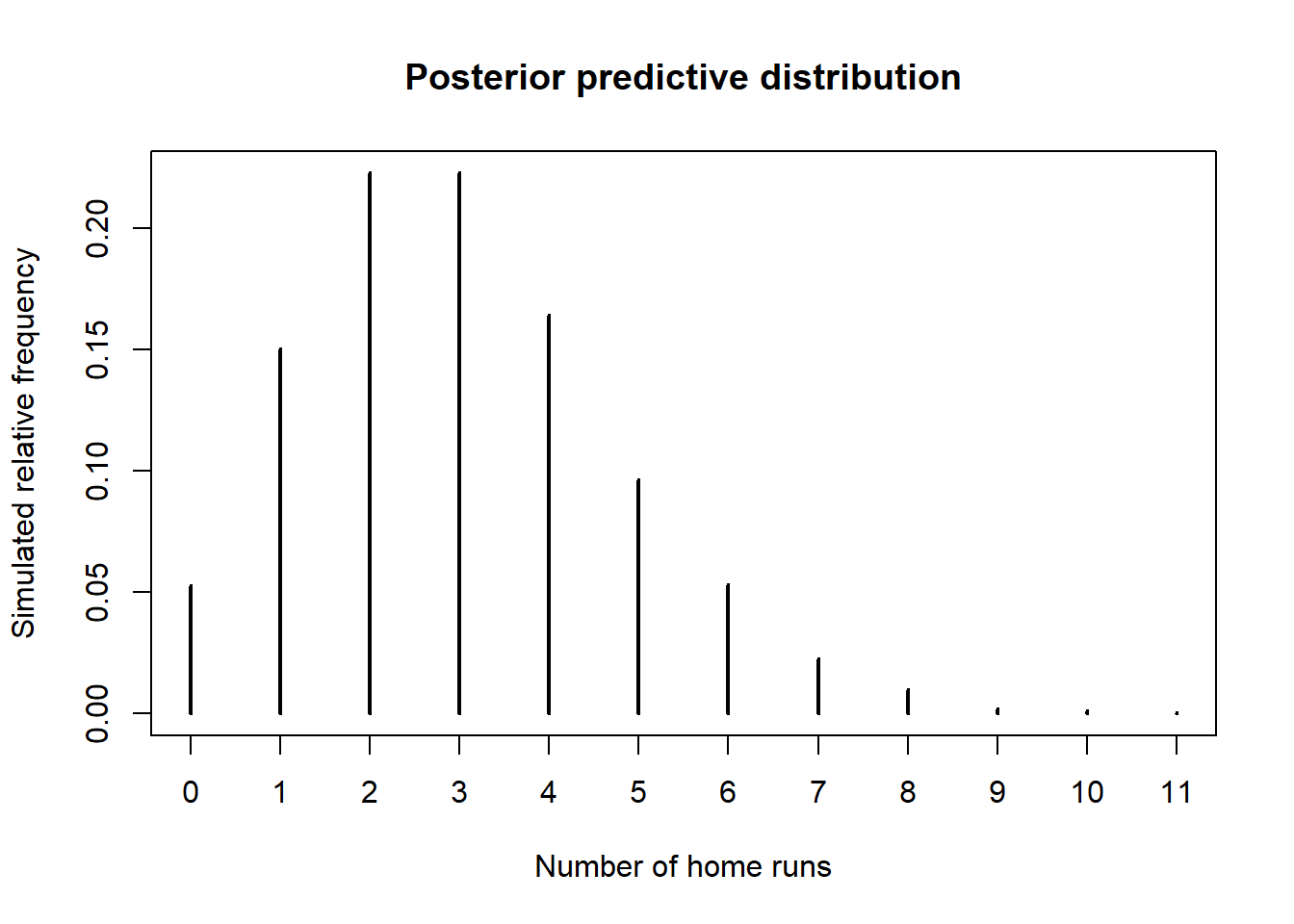
4.这个似然值是$y=1$和$y=3$两个似然值的乘积。 $$ f(y=(1,3)|\theta)=(\frac{e^{-\theta}\theta^{1}}{1!})(\frac{e^{-\theta}\theta^{3}}{3~})\propto e^{-2\theta}\theta^{4},{,,,,,,,,,,}\theta>0 $$ 后验概率满足 $$ \pi (\theta|y=(1,3))\propto (e^{-2\theta}\theta^{4})(\theta^{4-1}e^{-2\theta}),{,,,,,,,,}\theta>0, $$
我们将上述情况视为伽马密度,其形状参数为$\alpha=4+4$,速率参数为$\lambda=2+2$。 $$ Posterior{,,}mean=\frac{\alpha}{\lambda}{,,,,,,,,,,}\frac{8}{4}=2 $$
n = 2 # sample size
y = 2 # sample mean
# likelihood
likelihood = dpois(1, theta) * dpois(3, theta)
# posterior
posterior = dgamma(theta, alpha + n * y, lambda + n)
# plot
plot_continuous_posterior(theta, prior, likelihood, posterior)
abline(v = qgamma(c(0.025, 0.975), alpha + n * y, lambda + n),
col = "seagreen", lty = 2)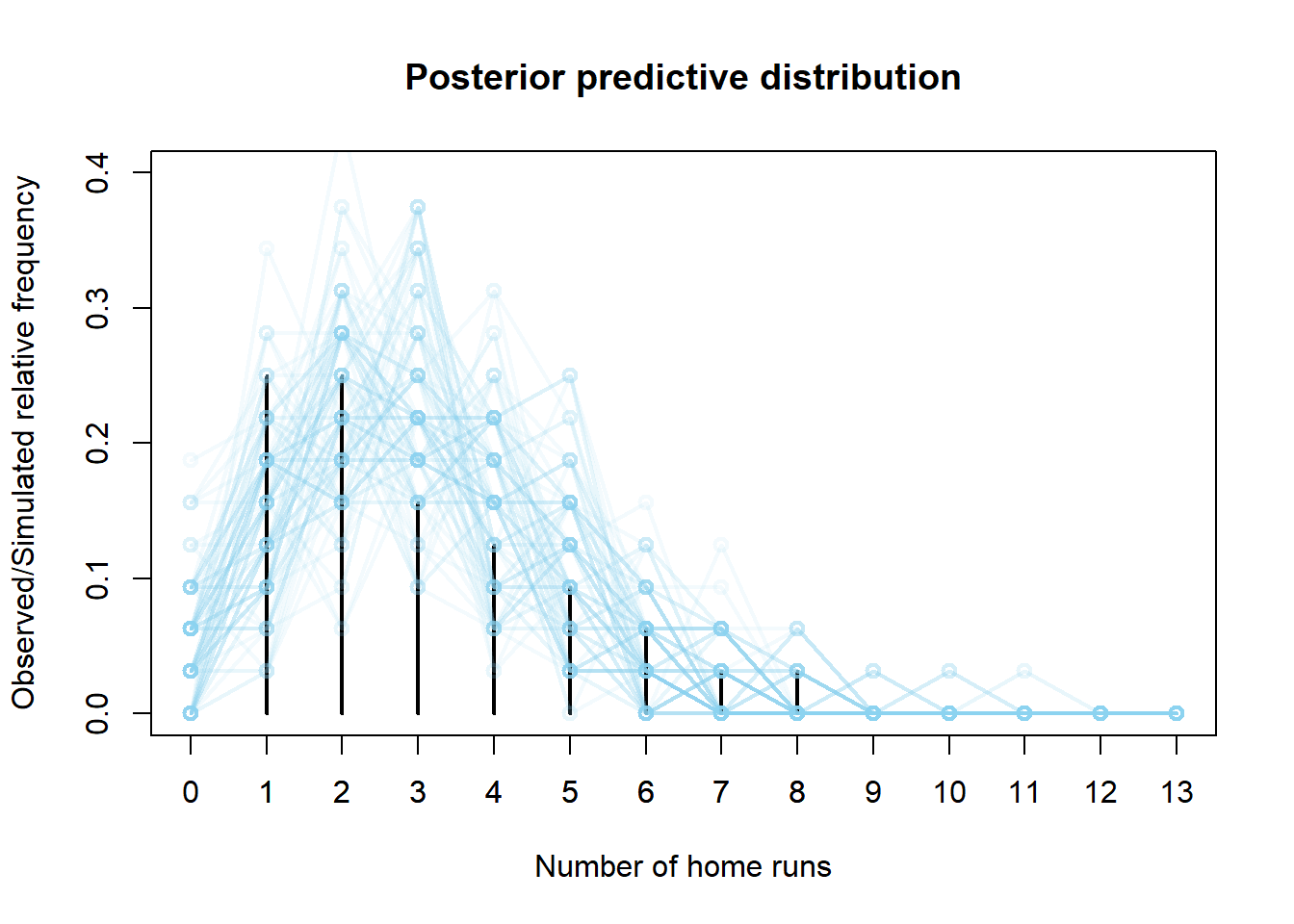
- 通过泊松聚合,2场比赛中的全垒打总数遵循泊松$(2\theta)$分布,似然值是使用泊松$(2\theta)$分布计算出的4(即两场比赛中全垒打)的概率。
关于$\theta$的似然函数的形状与上一部分相同,无论你是观察单个数值还是只观察总计数,似然函数的比例都是一样的。因此,后验分布与上一部分相同。
# likelihood
n = 2 # sample size
y = 2 # sample mean
likelihood = dpois(n * y, n * theta)
# posterior
posterior = dgamma(theta, alpha + n * y, lambda + n)
# plot
plot_continuous_posterior(theta, prior, likelihood, posterior)
abline(v = qgamma(c(0.025, 0.975), alpha + n * y, lambda + n),
col = "seagreen", lty = 2)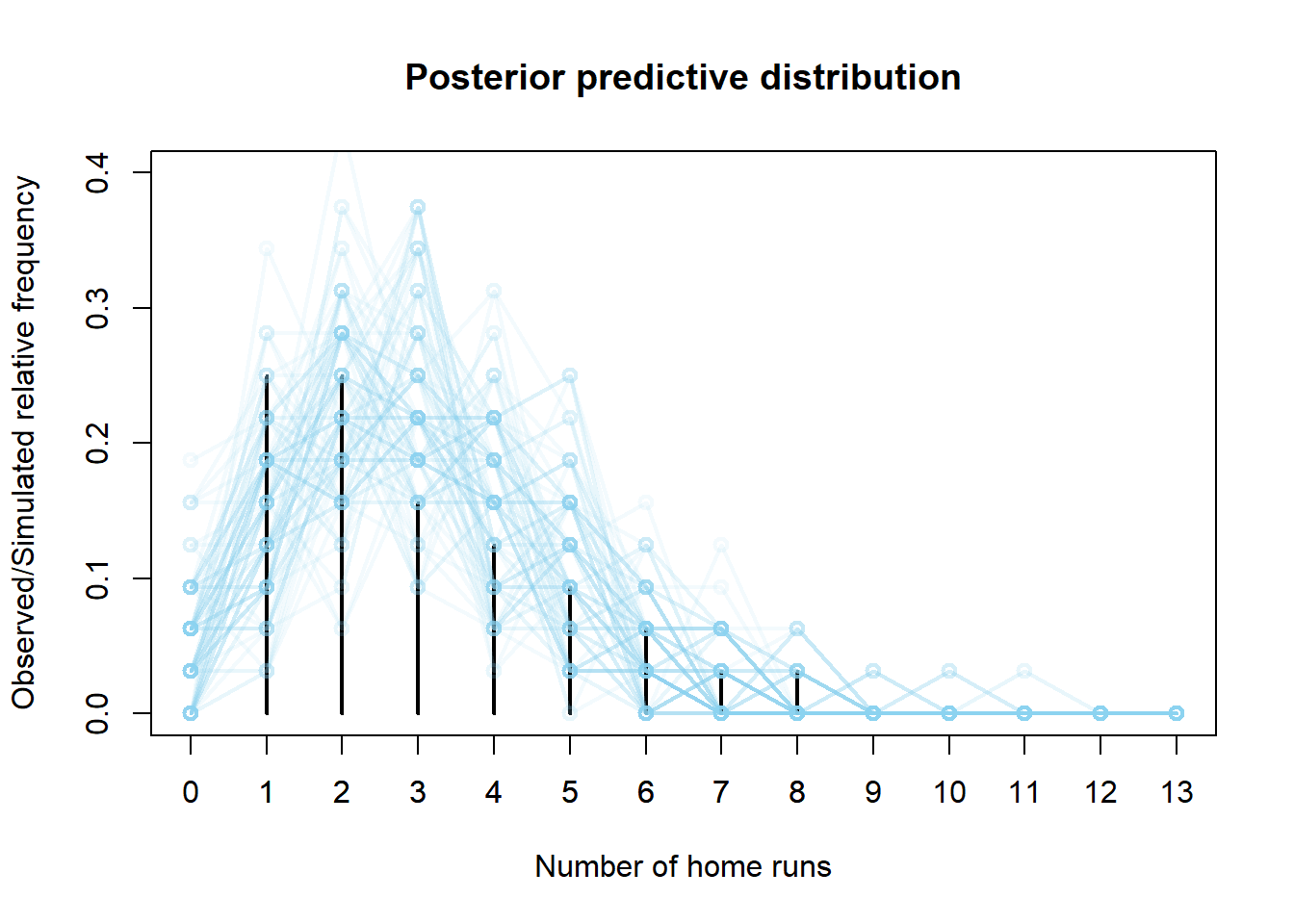
- 通过泊松聚合,32场比赛的总本垒打数遵循泊松$(32\theta)$分布。似然值是指从泊松$(32\theta)$分布中观察到值97(即 32场比赛中的全垒打总数)的概率。
后验概率满足 $$ \pi (\theta|\bar{y}=97/32)\propto(e^{-32\theta}\theta^{97})(\theta^{4-1}e^{-2\theta}),{,,,,,,,}\theta>0 $$
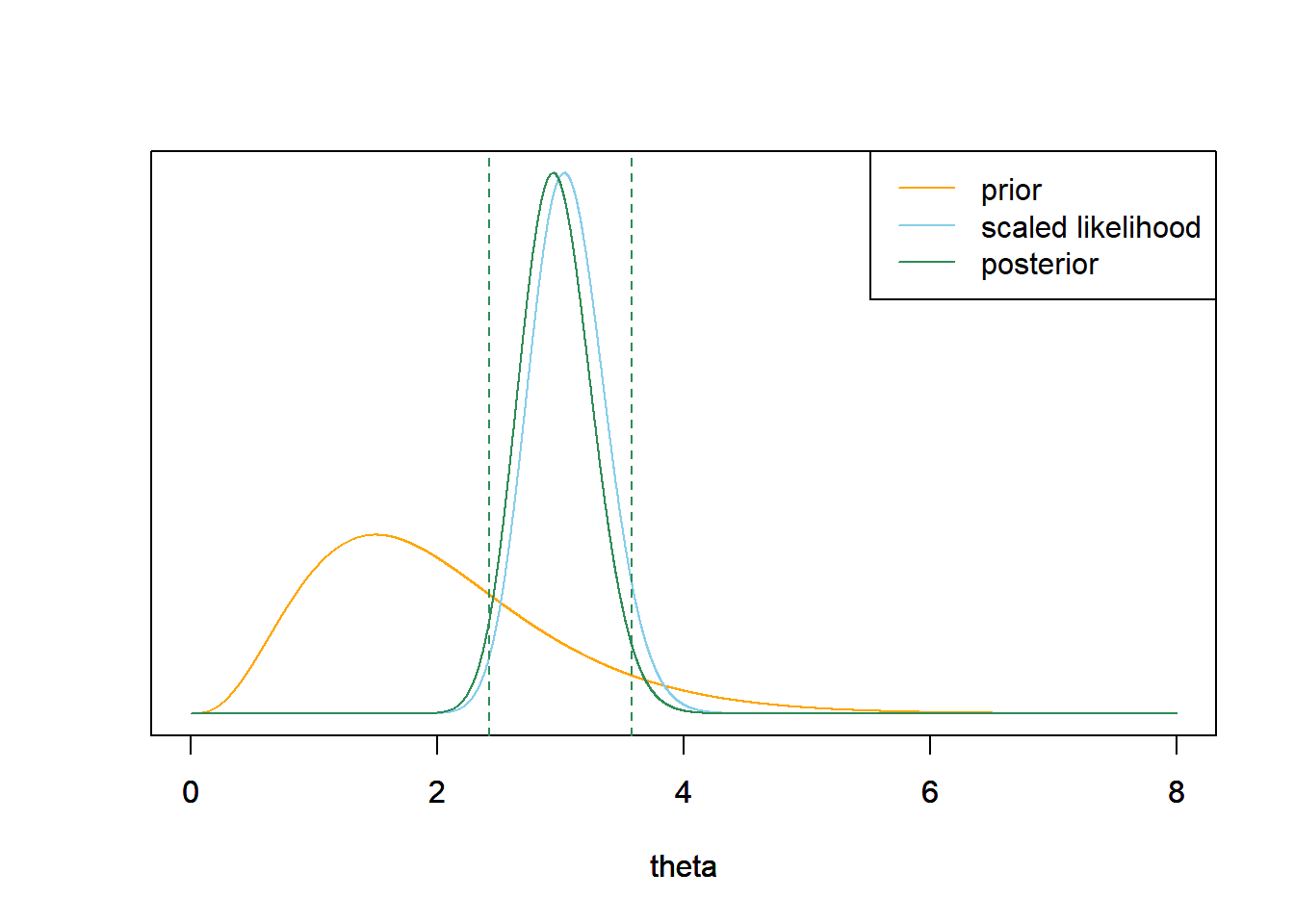
我们将上述情况视为伽马密度,形状参数$\alpha=4+97$,速率参数$\lambda=2+32$。 $$ Posterior{,,}mean=\frac{\alpha}{\lambda}{,,,,,,,,}\frac{101}{34}=2.97 $$
似然是以$97/32=3.03$的样本均值为中心,后验分布与似然相当接近,但先验仍然有一点影响。这个后验与我们在例12.3中通过网格近似计算的后验基本相同。
# likelihood
n = 32 # sample size
y = 97 / 32 # sample mean
likelihood = dpois(n * y, n * theta)
# posterior
posterior = dgamma(theta, alpha + n * y, lambda + n)
# plot
plot_continuous_posterior(theta, prior, likelihood, posterior)
abline(v = qgamma(c(0.025, 0.975), alpha + n * y, lambda + n),
col = "seagreen", lty = 2)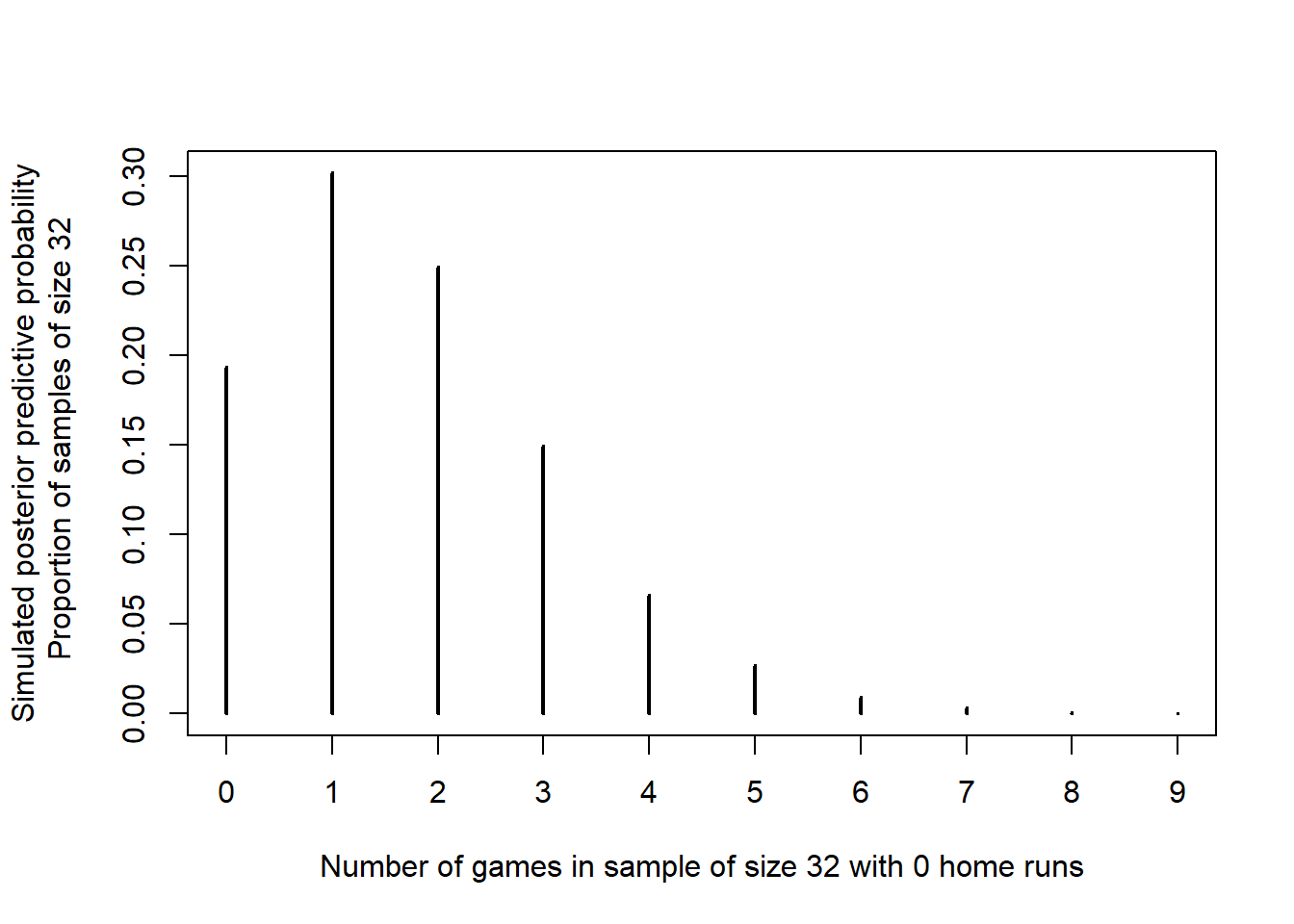
qgamma(c(0.025, 0.975), alpha + n * y, lambda + n)## [1] 2.419593 3.577259
-
公民银行公园每场比赛的平均全垒打数在2.4和3.6之间的后验概率为$$95%$$。
-
先验平均数是4/2=2,基于2的 "先验样本量"。样本平均数是97/32=3.03,基于32的样本量。后验平均数是(4+97)/(2+32)=2.97。后验平均数是先验平均数和样本平均数的加权平均值,其权重基于 "样本量"
在前面的例子中,我们看到,如果被测变量遵循参数为$\theta$的泊松分布,且先验分布服从参数为$\theta$ 的伽马分布,那么θ的后验分布也遵循伽马分布。
在给定的$\theta$下,考虑一个被测变量$Y$,它遵循泊松$(\theta)$分布。设$\bar{y}$是大小为$n$的随机样本的样本平均数,假定$\theta$具有伽马$(\alpha,\lambda)$ 先验分布,那么给定$\bar{y}$之后$$θ$$的后验分布服从伽马$(\alpha+n\bar{y},\lambda+n)$ 分布。也就是说,伽马分布构成了泊松似然的共轭先验族。
后验分布是先验和似然之间的妥协。对于伽马-泊松模型(Gamma-Poisson Model),对这种折中有一个直观的解释——在某种意义上,你可以把$\alpha$解释为 "先验总计数",而$\lambda$为 "先验样本量",但这些只是 "伪观测";此外,$\alpha$和$\lambda$不一定是整数。
注意,如果$\bar{y}$是样本平均数,那么$n\bar{y}=\sum_{i=1}^{n}y_i$是样本总计数。
| Prior | Data | Posterior | |
|---|---|---|---|
| Total count | |||
| Sample size | |||
| Mean |
-
后验总计数是先验总计数$\alpha$和样本总计数$n\bar{y}$的加和。
-
后验样本量是先验样本量$\lambda$和观测样本量$n$之和。
-
后验平均数是先验平均数和样本平均数的加权平均值,其权重与样本大小成正比。 $$ \frac{\alpha+n\bar{y}}{\lambda+n}=\frac{\lambda}{\lambda+n}(\frac{\alpha}{\lambda})+\frac{n}{\lambda+n}\bar{y} $$
-
随着收集的数据越来越多,对样本平均数给予更多的权重(而对先验平均数给予较少的权重)。
-
$\lambda$ 的值越大,表示先验信念越强。因为先验的样本量较大、方差较小,并对先验平均值给予更多的权重。试试这个小程序,它说明了伽马-泊松模型。
而没有指定$\alpha$和$\beta$的情况下,伽马分布的先验可以直接由其先验均值和标准差来指定。如果先验平均数是
例 29.4 继续前面的例子。假设公民银行公园的每场比赛的全垒打服从泊松分布,参数为$\theta$ 。假设对于$\theta$的伽马先验分布,其形状参数为$\alpha=4$和速率参数$\lambda=2$。 基于2020年的数据:在32场比赛中,有97支全垒打。
-
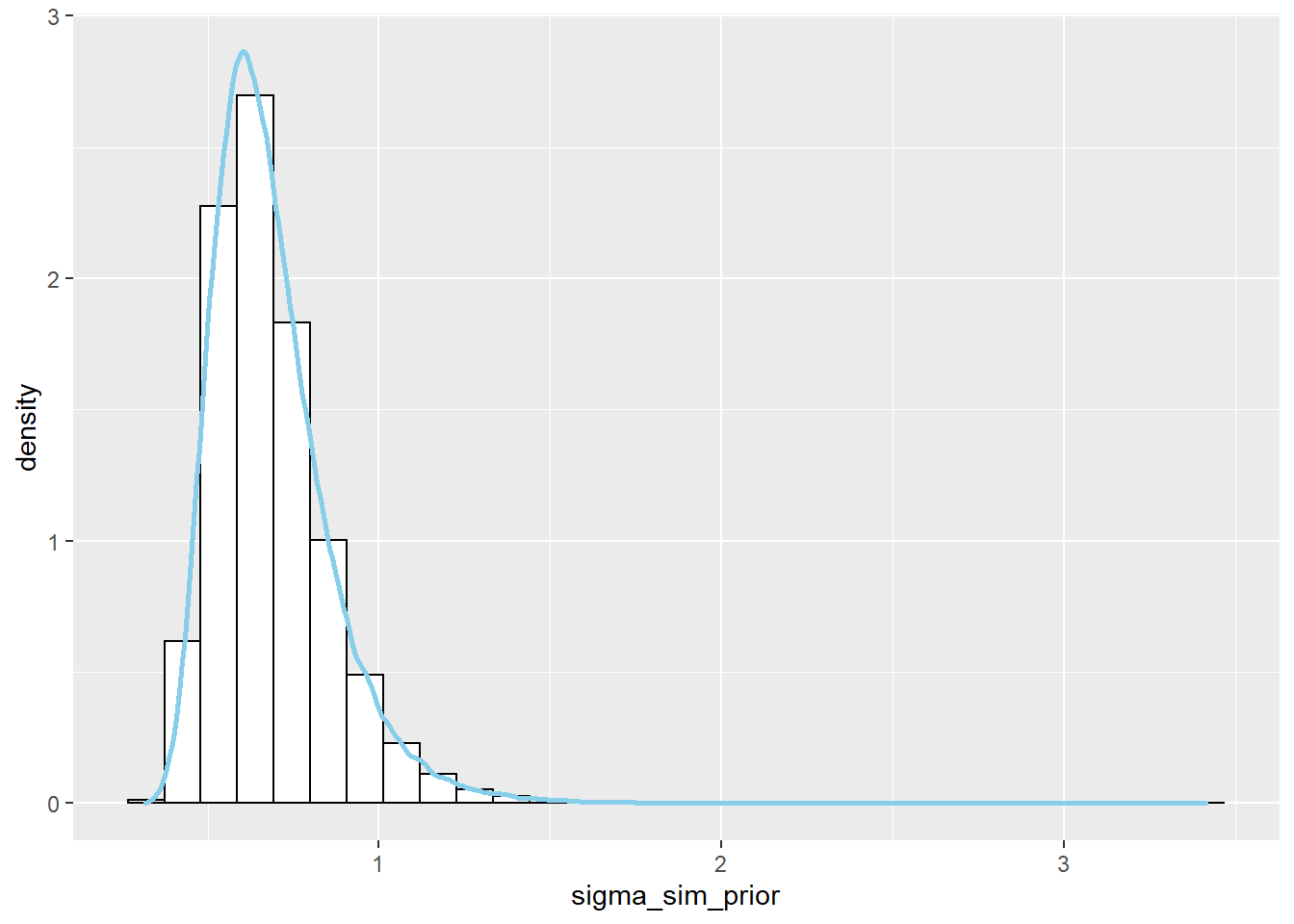
使用JAGS对$\theta$的后验分布进行近似,与前面的例子中的结果进行比较。
-
为什么能用模拟(而不是JAGS)来近似计算一场比赛中全垒打的后验预测分布?
-
使用上一部分的模拟,找到并解释一个$95%$的后验预测区间,其下限为0。
-
泊松模型是数据的合理模型吗?你可以如何使用后验预测模拟来模拟32场比赛的样本在这个模型下会是什么样子。模拟许多这样的样本,注意观察到的样本似乎与该模型是否一致。
-
关于泊松模型的适当性,我们可能会担心样本中没有0全垒打的比赛,故而使用模拟法来近似计算32个样本中0全垒打的比赛数量的后验预测分布。从这个角度看,统计量的观察值是否与伽马-泊松模型一致?
例29.4的解决方案
-
JAGS的代码在最后。结果与前面例子的理论结果非常相似。
-
从伽马$(101,34)$后验分布中模拟出$\theta$的值,然后给定泊松$(\theta)$的分布,重复多次,总结出$y$值来近似后验预测分布。
Nrep = 10000 theta_sim = rgamma(Nrep, 101, 34) y_sim = rpois(Nrep, theta_sim) plot(table(y_sim) / Nrep, type = "h", xlab = "Number of home runs", ylab = "Simulated relative frequency", main = "Posterior predictive distribution")
-
在一场比赛中,有95%的后验预测概率在0到6支全垒打之间。我们可以非常粗略地说,大约95%的比赛有0到6支全垒打。
quantile(y_sim, 0.95)
## 95% ## 6 -
模拟出一个值为$\theta$从其伽马$(101,34)$后验分布中模拟出一个值,然后给定$\theta$,根据泊松$(\theta)$分布模拟32个值的$y$值,对每个样本进行总结并重复多次,模拟出许多大小为32的样本。比较观察到的样本和模拟的样本,除了样本中没有0全垒打的比赛外,该模型似乎是合理的。
df = read.csv("_data/citizens-bank-hr-2020.csv")
y = df$hr
n = length(y)
plot(table(y) / n, type = "h", xlim = c(0, 13), ylim = c(0, 0.4),
xlab = "Number of home runs",
ylab = "Observed/Simulated relative frequency",
main = "Posterior predictive distribution")
axis(1, 0:13)
n_samples = 100
# simulate samples
for (r in 1:n_samples){
# simulate theta from posterior distribution
theta_sim = rgamma(1, 101, 34)
# simulate values from Poisson(theta) distribution
y_sim = rpois(n, theta_sim)
# add plot of simulated sample to histogram
par(new = T)
plot(table(factor(y_sim, levels = 0:13)) / n, type = "o", xlim = c(0, 13), ylim = c(0, 0.4),
xlab = "", ylab = "", xaxt='n', yaxt='n',
col = rgb(135, 206, 235, max = 255, alpha = 25))
}
- 继续上一部分的模拟,现在对于每个模拟的样本,我们记录下0全垒打的比赛数量。
n_samples = 10000
zero_count = rep(NA, n_samples)
# simulate samples
for (r in 1:n_samples){
# simulate theta from posterior distribution
theta_sim = rgamma(1, 101, 34)
# simulate values from Poisson(theta) distribution
y_sim = rpois(n, theta_sim)
zero_count[r] = sum(y_sim == 0)
}
plot(table(zero_count) / n_samples, type = "h",
xlab = "Number of games with 0 home runs",
ylab = "Simulated posterior predictive probability")
下面是JAGS的代码以及注意事项。
- 数据已被加载为单个值,即32场比赛中每场的全垒打数量。
- 似然被定义为一个循环。对于每个
y[i]值,似然是按照泊松$(\theta)$分布计算。 - 先验分布是一个伽马分布。(记住,JAGS中
dgamma,dpois等语法与R中不同)。
# data
df = read.csv("_data/citizens-bank-hr-2020.csv")
y = df$hr
n = length(y)
# model
model_string <- "model{
# Likelihood
for (i in 1:n){
y[i] ~ dpois(theta)
}
# Prior
theta ~ dgamma(alpha, lambda)
alpha <- 4
lambda <- 2
}"
# Compile the model
dataList = list(y=y, n=n)
Nrep = 10000
Nchains = 3
model <- jags.model(textConnection(model_string),
data=dataList,
n.chains=Nchains)## Compiling model graph
## Resolving undeclared variables
## Allocating nodes
## Graph information:
## Observed stochastic nodes: 32
## Unobserved stochastic nodes: 1
## Total graph size: 36
##
## Initializing modelupdate(model, 1000, progress.bar="none")
posterior_sample <- coda.samples(model,
variable.names=c("theta"),
n.iter=Nrep,
progress.bar="none")
# Summarize and check diagnostics
summary(posterior_sample)##
## Iterations = 1001:11000
## Thinning interval = 1
## Number of chains = 3
## Sample size per chain = 10000
##
## 1. Empirical mean and standard deviation for each variable,
## plus standard error of the mean:
##
## Mean SD Naive SE Time-series SE
## 2.973406 0.295767 0.001708 0.001692
##
## 2. Quantiles for each variable:
##
## 2.5% 25% 50% 75% 97.5%
## 2.421 2.768 2.964 3.165 3.581
plot(posterior_sample)