Feature Proposal: External Agent Provider abstraction for native voice agent APIs #35
Description
Summary
We'd like to propose an abstraction that enables EVA to benchmark hosted voice agent APIs (native voice agents beyond Pipecat) — directly addressing the Extended Leaderboard roadmap item:
More cascade and speech-to-speech systems evaluated and added to the findings including native voice agent APIs beyond Pipecat (ElevenAgents, Gemini Live, OpenAI Realtime, Deepgram Voice Agent, etc.)
We've built a working implementation in our fork, run a full 50 records × 3 trials evaluation, and wanted to discuss the approach before submitting a PR.
The Problem
EVA currently evaluates voice agents that run inside a Pipecat pipeline (STT → LLM → TTS or S2S). But many production voice agents are hosted black boxes — you call them via a phone number or WebSocket and interact over audio. There's no Pipecat pipeline to instrument.
Examples: Telnyx AI Assistants, ElevenLabs Conversational AI, Deepgram Voice Agent, OpenAI Realtime API, Google Gemini Live.
Proposed Architecture
An External Agent Provider plugin interface that lets EVA evaluate any hosted voice agent:
┌──────────────────────────────────────────────────────────────────┐
│ EVA Runner │
│ │
│ ┌──────────────┐ ┌──────────────────────┐ ┌────────────┐ │
│ │ ElevenLabs │ WS │ External Agent │ │ Tool │ │
│ │ User Sim │◄───►│ Bridge (generic) │ │ Webhook │ │
│ └──────────────┘ └──────────┬───────────┘ └──────┬─────┘ │
│ Provider │ │ │
│ Transport│ │ │
└──────────────────────────────────┼───────────────────────┼───────┘
│ │
┌────────▼─────────┐ ┌────────▼───────┐
│ Provider │ │ External │
│ Platform │───►│ Voice Agent │
└──────────────────┘ └────────────────┘
Core abstraction: ExternalAgentProvider
class ExternalAgentProvider(ABC):
@abstractmethod
def create_transport(self, conversation_id, webhook_base_url) -> BaseTelephonyTransport:
"""Create a transport connection to the external agent."""
@abstractmethod
async def setup(self) -> None:
"""One-time setup before a benchmark run (e.g., configure assistant via API)."""
@abstractmethod
async def teardown(self) -> None:
"""Clean up after a benchmark run."""
@abstractmethod
async def fetch_intended_speech(self, transport) -> list[dict]:
"""Post-call enrichment: fetch what the agent intended to say (for metrics)."""
def register_webhook_routes(self, app: FastAPI) -> None:
"""Optional: register provider-specific webhook endpoints."""Adding a new provider requires only a new providers/xxx/ directory with config, transport, and setup. No changes to the bridge, worker, runner, or metrics pipeline.
Two-layer transport design
The transport layer has two independent abstractions that can be mixed and matched:
BaseTelephonyTransport— the audio pipe (start/stop/send_audio/emit_audio). Different agents connect differently: SIP, WebSocket, WebRTC. Each is a different transport.ExternalAgentProvider— the lifecycle layer that creates transports and manages agent configuration.
These are independent: any SIP-reachable agent could reuse the Telnyx Call Control transport with a different provider. A WebSocket-based transport (for ElevenLabs) just needs start(), stop(), send_audio().
Why a client-side bridge?
The bridge sits between the user simulator and the external agent. This is intentional:
- Metrics compatibility — captures
pipecat_logs.jsonlformat from raw audio (VAD events, turn boundaries, timestamps) that the external agent's API doesn't expose - Platform-independent latency measurement — third-party observer, not self-reported by the provider, making cross-provider comparisons fair
Important caveat: Real production calls don't have this intermediary. Benchmark latency will be higher than real-world latency. EVA measures relative performance across providers under identical conditions — not absolute production latency.
Changes to Core EVA
We've kept upstream changes minimal. Here's every file we touch and why:
| Area | Files | Lines | Why |
|---|---|---|---|
| User simulator | client.py, audio_interface.py |
+63 | audio_codec param (pcm/mulaw) — external agents may use different formats |
| Config | models/config.py |
+131 | ExternalAgentConfig base + discriminator (same pattern as existing config hierarchy) |
| Orchestrator | runner.py, worker.py |
+171 | Provider lifecycle + bridge instantiation (parallel to existing AssistantServer logic) |
| Metrics base | metrics/base.py |
+20 | message_trace field + helper methods for turn counting |
| Metrics processor | metrics/processor.py |
+168 | Control event filtering, sort priority, message_trace loading (general correctness improvements) |
| Individual metrics | 5 files | +30 | Use base class helpers instead of direct trace access |
| Tools | airline_tools.py |
+5 | end_call stub (webhook intercepts it; stub passes tool validation) |
| Audit log | audit_log.py |
+8 | replace_transcript() for post-call enrichment |
Everything else (~2000 lines) is purely additive in a new assistant/external/ package.
Relationship to PR #14
We noticed the concern in PR #14 about Pipecat log coupling. Our approach addresses this by having the bridge write normalized output files (message_trace.jsonl, pipecat_logs.jsonl) before the metrics processor sees them — the processor doesn't need to know about bridge mode.
Benchmark Results
We ran the full EVA benchmark (50 records × 3 trials, 150 conversations) using our Telnyx provider. The Telnyx AI Assistant was configured with all self-hosted components on the Telnyx platform:
- LLM: Kimi-K2.5 (Moonshot AI)
- STT: Deepgram Flux
- TTS: Telnyx Ultra
| Metric | Score |
|---|---|
| EVA-A_pass@1 (Accuracy) | 0.48 |
| EVA-X_pass@1 (Experience) | 0.67 |
| EVA-A_mean | 0.71 |
| EVA-X_mean | 0.63 |
| EVA-overall_mean | 0.67 |
Here's how Telnyx (Kimi-K2.5) places on the EVA leaderboard at pass@1:
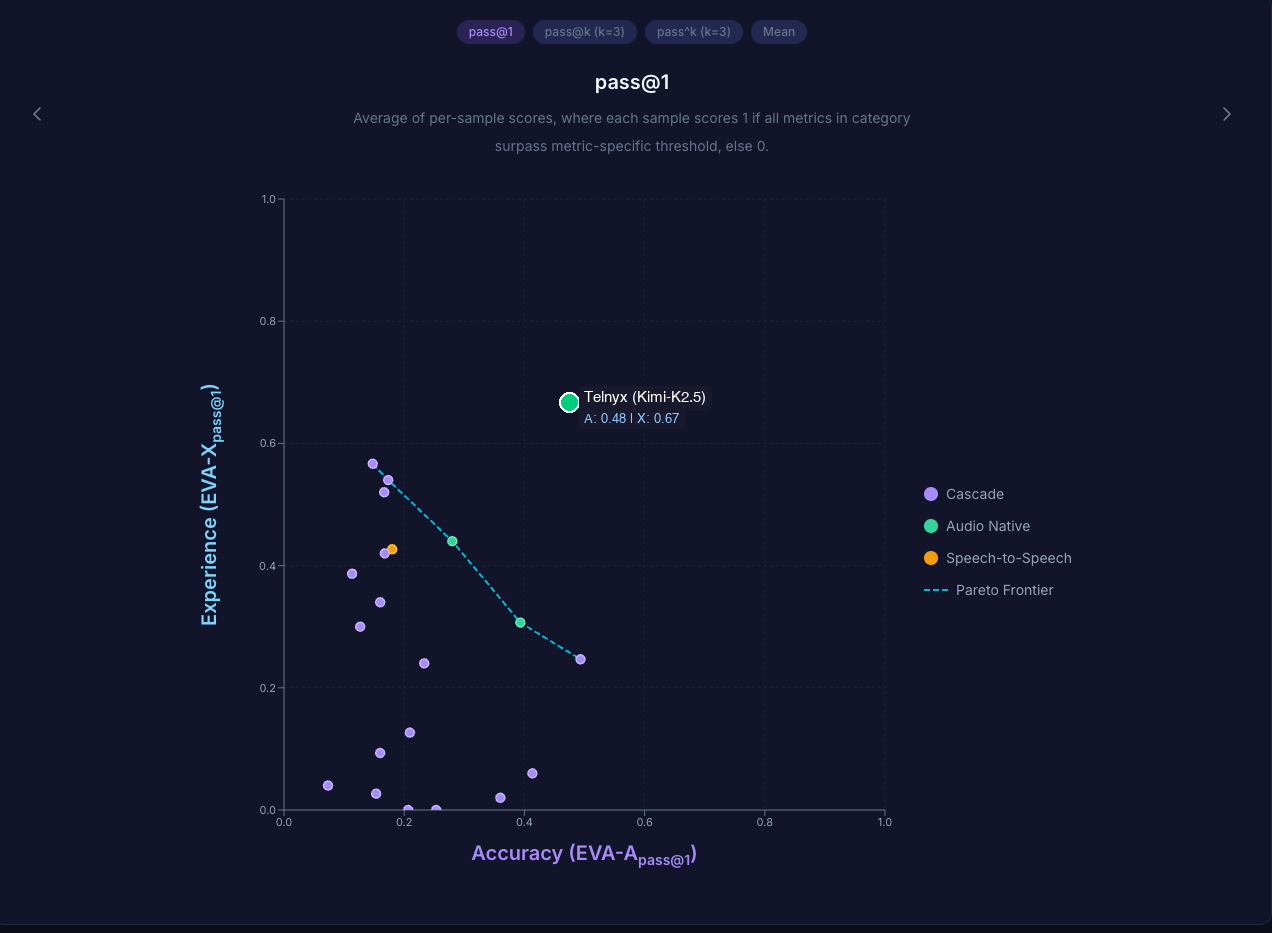
Telnyx sits above the current Pareto frontier — meaningfully ahead of existing cascade and audio-native systems on Experience, with competitive Accuracy.
Full metrics: metrics_summary.json
Why this matters for the Extended Leaderboard: Hosted voice agent APIs that own the full stack (telephony + STT + LLM + TTS) can optimize end-to-end in ways that component-level Pipecat cascades can't. Adding support for external providers doesn't just expand coverage — it pushes the Pareto frontier and raises the bar for what "good" looks like on the leaderboard.
Resources
- Full diff against upstream — every change in one view
- Documentation — architecture, adding providers, changes to core EVA
Next Steps
We'd love feedback on:
- Does this abstraction align with your vision for the Extended Leaderboard?
- Are the core changes acceptable? We've tried to minimize them, but we're open to alternative approaches (e.g., making the metrics processor fully pluggable).
- Would you prefer a single PR or a series of smaller ones?
Happy to iterate on the design before submitting any code. Thanks for building EVA — it's been great to work with.