A collection of tricks to simplify and speed up transformer models:
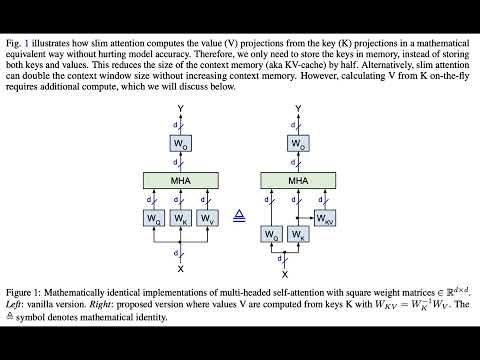
- Slim attention: paper, video, podcast, notebook, code-readme, 🤗 article, reddit
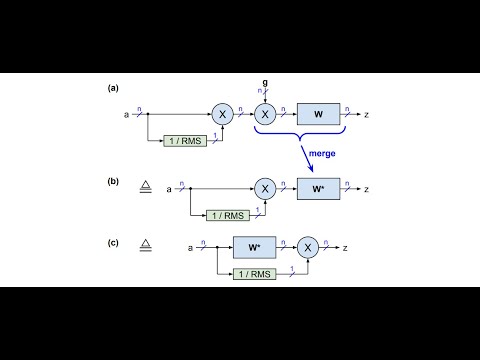
- FlashNorm: paper, video, podcast, notebook, code-readme
- MatShrink [work in progress]: paper, notebook, precision experiments
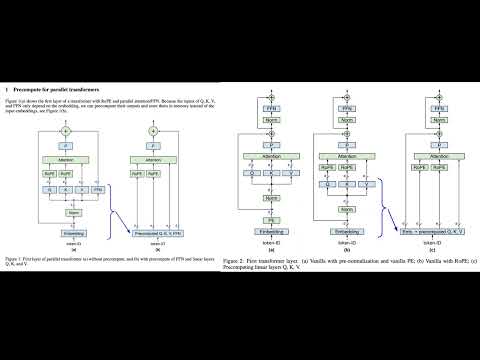
- Precomputing the first layer: paper, video, podcast
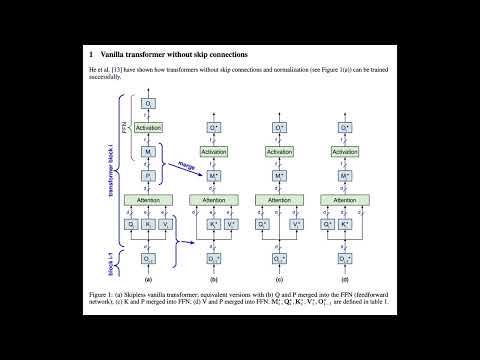
- KV-weights only for skipless transformers: paper, video, podcast, notebook
These transformer tricks extend a recent trend in neural network design toward architectural parsimony, in which unnecessary components are removed to create more efficient models. Notable examples include RMSNorm’s simplification of LayerNorm by removing mean centering, PaLM's elimination of bias parameters, and decoder-only transformer's omission of the encoder stack. This trend began with the original transformer model's removal of recurrence and convolutions.
For example, our FlashNorm removes the weights from RMSNorm and merges them with the next linear layer. And slim attention removes the entire V-cache from the context memory for MHA transformers.
Transformer tricks GitHub repo: here
Install the transformer tricks package:
pip install transformer-tricksAlternatively, to run from latest repo:
git clone https://github.com/OpenMachine-ai/transformer-tricks.git
python3 -m venv .venv
source .venv/bin/activate
pip3 install --quiet -r requirements.txtConvert any RMSNorm-based HuggingFace checkpoint to a -FlashNorm variant and publish it under your own account. The recipe below does the full round-trip in a dozen lines; it works for Llama, Mistral, Gemma, Qwen, SmolLM, and any other transformer that uses RMSNorm followed by a linear layer.
# pip install transformer-tricks huggingface-hub
import transformer_tricks as tt
from huggingface_hub import HfApi, login
login() # paste your HF write token when prompted
SRC = 'meta-llama/Llama-3.2-1B' # source model on HF
OUT = 'YOUR_USERNAME/Llama-3.2-1B-FlashNorm' # destination (under your account)
LOCAL = './Llama-3.2-1B_flashNorm' # local workdir
tt.flashify_repo(SRC, dir=LOCAL, strict=True) # fold g into W*, remove norm tensors
api = HfApi()
api.create_repo(OUT, exist_ok=True)
api.upload_folder(repo_id=OUT, folder_path=LOCAL)
print(f'Published https://huggingface.co/{OUT}')The strict=True flag folds the per-channel norm weights g into the following linear layer and removes the now-redundant norm tensors from the state dict entirely. The resulting checkpoint is mathematically equivalent to the source (Proposition 1 of the FlashNorm paper). Framework support status (HuggingFace Transformers, vLLM, llama.cpp) is tracked on the canonical FlashNorm checkpoint: open-machine/SmolLM2-135M-FlashNorm.
A runnable notebook version of this recipe is at notebooks/flashify_and_publish.ipynb.
Follow the links below for documentation of the python code in this directory:
The papers are accompanied by the following Jupyter notebooks:
- Slim attention:
- Flash normalization:
- Flashify your own model and publish to HuggingFace:
- MatShrink:
- Removing weights from skipless transformers:
Please subscribe to our newsletter on substack to get the latest news about this project. We will never send you more than one email per month.
We pay cash for high-impact contributions. Please check out CONTRIBUTING for how to get involved.
The Transformer Tricks project is currently sponsored by OpenMachine. We'd love to hear from you if you'd like to join us in supporting this project.