【TPDS 21】The Deep Learning Compiler: A Comprehensive Survey
看懂30%,不DFS, 初步扫盲;未来有需要再返回查
模型被拆分 ,分成了种种IR
- 高级IR:建立控制流以及操作符和数据之间的依赖关系,并提供用于图级优化的接口。
- 包含丰富的编译语义信息,并为定制运算符提供可扩展性
- 低级 IR :应该足够细粒度,以反映硬件特性并代表特定于硬件的优化
- 允许在编译器后端使用成熟的第三方工具链,例如 Halide、多模态模型 、 LLVM
- DAG 有向无环图
- DDG(data dependence graphs,数据依赖图) --- 用于通用的编译器
- 改进 common sub-expression elimination (CSE), dead code elimination (DCE).
- 表达张量计算:Function-based,Lambda expression,Einstein notation:
DL编译器 实现的视角
将现有深度学习框架中的深度学习模型作为输入,然后将模型转换为计算图表示
- 步骤:1)从计算图中捕获特定特征;2)重写图以进行优化。
- 预定义有passes,开发者还可以定制 passes
- 优化可以分为
- 节点级
- 节点消除,消除不必要的节点
- 节点替换,用其他成本较低的节点替换节点
- 块级(局部优化)
- 代数简化 -- (1)计算顺序的优化(2)节点组合的优化 (3)ReduceMean节点的优化
- 代数识别
- 强度约简,更便宜的算子取代更昂贵的算子
- 常量折叠,用常量表达式的值替换常量表达式
- 算子融合Fusion --- 共享计算,消除中间分配
- 提出框架来探索 融合计划(支持element-wise和reduction节点、还支持其他具有复杂依赖关系的计算/内存密集型节点)
- 算子下沉sinking
- 将转置等操作下沉到批量归一化、ReLU、sigmoid
- 代数简化 -- (1)计算顺序的优化(2)节点组合的优化 (3)ReduceMean节点的优化
- 数据流级(全局优化)
- Common Sub-Expression Elimination (CSE).公共子表达始删除 已经算出来的就保留,不再计算
- Dead Code Elimination (DCE). 死代码消除,计算不起作用
- 静态内存规划:尽可能多的重用 buffer
- 布局转换(依据硬件来决定):在计算图中找到存储张量的最佳数据布局,然后将布局变换节点插入到图中
- 节点级
- 前端之后,生成优化的计算图并传递到后端
将高级 IR 转换为低级 IR 并执行特定于硬件的优化:将高级IR转换为LLVM IR等第三方工具链,以利用现有基础设施进行优化
1.2.1 利用深度学习模型和硬件特性的先验知识,通过定制的编译过程来更有效地生成代码
-
硬件固有映射:一组特定的低级IR指令转换为已经在硬件上高度优化的内核
-
内存分配和获取:决定在 shared / thread-local
-
内存延迟隐藏:重新排序pipeline
-
面向循环的优化 Loop Oriented Optimizations
-
并行化
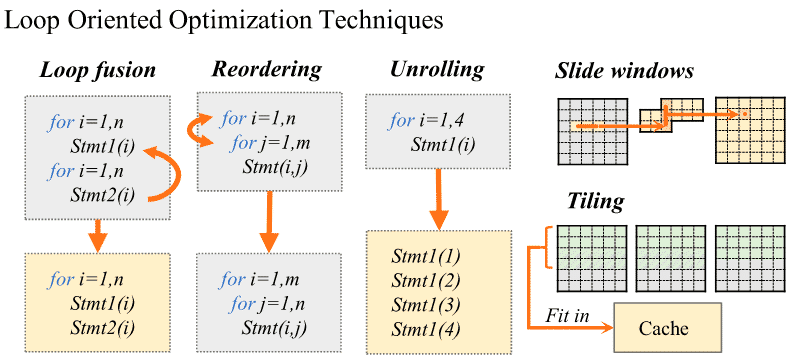
1.2.2 自调优 的要素 (Auto-Tuning 抽象化了解):
- 参数情况①数据与目标 ②优化选项
- 代价模型 选择
- 搜索技术①初始化搜索空间 ②遗传算法 ③模拟退火算法 ④RL强化学习
- 加速①并行化 ②定制化冲用
1.2.3 优化kernel库
- 如果 如果本身的计算 能满足优化好的原语 --- 高性能
- 否则 限制了进一步的优化策略(不能fusion......)
- 动态输入 形状,Pre/Post processing
- 高级的自调优:结合 选择特征来代表程序
- 多面体模型Polyhedral Model
- 子图分割:计算图被分成了子图 --- 子图 上异构平台、不同的处理手段
- 量化:①量化的操作 不占用太多的工程负载;②量化与其他优化的结合
- 统一优化:软硬件协同设计、一个编译器的优化可以用在另一个编译器上
- 可微分编程:程序可以被再分成更原子的形式 --- 但现在的编译器不支持
- 隐私保护:关于“边缘计算”
- 训练支持:多数DL compiler都在优化推理,训练还有很大空间
读论文 --- 做笔记,整理得到表格
DFS到related work部分涉及到的强相关论文
- 强相关指应用了fusion,以及与fusion相关的技术或优化,训练/推理优化 的文章
直接从现有学术论文中,总结现有方法;survey作为扫盲
fusion粒度(subgraph粒度?operator粒度?GPU kernel粒度?)
特异优化(如混精、无同步算法?)
面向网络(如CNN、RNN、GNN?)
实现方式(如自定义框架,基于已有框架,基于已有编译器?)
【IPDPS ‘23】ByteTransformer: A High-Performance Transformer Boosted for Variable-Length Inputs
- 提出了一种(padding-free)无填充算法:消除零填充令牌的冗余计算
- 将输入张量与可变长度序列打包 并 计算所有Transformer操作的定位偏移向量
- 为 Transformer 功能模块提供架构感知优化 --- 主要是多头注意力,减轻中间矩阵的内存开销
- 手动调整 layernorm 的内存占用,添加偏差和激活
- 性能测评 A100+ 普适性 (类Bert)
“现有优化手段: DL编译器 / TensorRT(精细的手动调整)”
- Add bias and layer normalization
- Add bias and activation
[11]TurboTransformer
[平台-24]FasterTransformer https://github.com/NVIDIA/FasterTransformer#fastertransformer
[27]DeepSpeed-Inference
[平台-29]https://github.com/NVIDIA/TensorRT/tree/release/8.6/plugin/bertQKVToContextPlugin(融合的一种实现)
端到端框架 都使用了算子融合优化
TensorFlow Lite [平台-1]、TVM [平台-12]、MNN [平台-29] 、 Pytorch-Mobile [平台-48]
[31] [32] [44] ---- 传统编译器 使用算子融合的
[10]基于polyhedral analysis的算子融合:
[3]Effective Loop Fusion in Polyhedral Compilation Using Fusion Conflict Graphs
[8]On Optimizing Operator Fusion Plans for Large-Scale Machine Learning in SystemML.
[9]A Model for Fusion and Code Motion in an Automatic Parallelizing Compiler.
[22]SPOOF: Sum-Product Optimization and Operator Fusion for Large-Scale Machine Learning.
[71]Loop and data transformations for sparse matrix code.
ß
关于训练的 related work
UNDERSTANDING GNN COMPUTATIONAL GRAPH: A COORDINATED COMPUTATION, IO, AND MEMORY PERSPECTIVE
Understanding and Bridging the Gaps in Current GNN Performance Optimizations.
Deep Graph Library: A Graph-Centric, Highly-Performant Package for Graph Neural Networks
论文依照它的题目思路展开(计算、IO、memory)
- 计算:冗余神经算子计算 --- 重新组织算子
- IO:线程映射不一致 --- 统一的线程映射方案 促成融合
- Memory:中间数据过多 --- 反向过程 中间数据重计算
AStitch: Enabling a New Multi-dimensional Optimization Space for Memory-Intensive ML Training and Inference on Modern SIMT Architectures
[11]XLA [18]TVM [48]huaggingface
[13]Learning to fuse.
[14]Learning to optimize halide with tree search and random programs.
[15]On optimizing machine learning workloads via kernel fusion
[16]Tiramisu: A polyhedral ==compiler== for expressing fast and portable code
[25]TASO: optimizing deep learning computation with automatic generation of graph substitutions
[31]Automatic Horizontal Fusion for GPU Kernels
[34]DNNFusion 重复
[37]Automatic kernel fusion for image processing DSLs.
[38]From loop fusion to kernel fusion: A domain-specific approach to locality optimization
[39]Nimble: Efficiently ==compiling== dynamic neural networks for model inference
[41]Astra: Exploiting predictability to optimize deep learning.
[42]Latte: a language, ==compiler==, and runtime for elegant and efficient deep neural networks
[43]Tensor comprehensions: Framework-agnostic high-performance machine learning abstractions
[45]Scalable kernel fusion for memorybound GPU applications
[46]Accelerating Deep Learning Inference with Cross-Layer Data Reuse on GPUs.
[49]Kernel weaver: Automatically fusing database primitives for efficient gpu computation
[55]Versapipe: a versatile programming framework for pipelined computing on GPU
[57] Fusionstitching: boosting memory intensive computations for deep learning workloads.
[59]DISC : A Dynamic Shape ==Compiler== for Machine Learning Workloads
- 检索关键词 {(DL, ML, CNN, DNN, Transformer), (compiler, optimizer, optimization, framework), (kernel fusion, kernel fission)}
- 主要检索 Dom2的关键词,文章中进一步检索fusion、fission、kernel
- 发表venue:SC、PPoPP、ATC、ASPLOS、IPDPS、ICPP、ICS
- 观感:
-
华人真不少北美:UC-SD/LA/RS/SB
-
很少有在标题 、Abstract上就体现 Fusion的;
-
但是每年都有(对一同一个venue不是连着有)ML compiler、framework、结构化稀疏、Sparse NN --- 专门的track
- PPoPP2023 - Track:Kernels、Attention、Training
- SC:compiling
- ATC23:Kernel and Concurrency, --- OS kernel年念头
KAISA: An Adaptive Second-Order Optimizer Framework for Deep Neural Networks
Efficient Tensor Core-Based GPU Kernels for Structured Sparsity under Reduced Precision
【ISCA‘18】Bit Fusion: Bit-Level Dynamically Composable Architecture for Accelerating Deep Neural Networks
4 - 工作信息提取
Fusion的
-
直接分析某个应用 eg Transformer(DAG图),分析下,融合
-
两个步骤:①检测哪些操作可以被融合,②判断融合是否有利
初步确定了方向,细化知识 --- TVM源码build时,需要LLVM的预先build
up主:先进编译实验室 - 华为昇思MindSpore ---- 通过该课程和专栏 学习的autoTVM、TVM知识
B站:https://space.bilibili.com/1540261574/video
知乎:https://www.zhihu.com/people/33-31-35-97 -- 还有论文解读:Rammer、Astitch、DietCode、DISC、FreeTensor
Reference:①合集·【AI编译器】传统编译器 - ZOMI酱 -Bilibili ②前者的配套资源 - AI Sys
主要Reference:【TPDS21】The Deep Learning CompilerA Comprehensive Survey【OSDI20】Ansor
-
现有的学习框架 --- 衍生出 深度学习编译器
-
TVM作为深度学习编译的典型代表
- 中间表示的抽象比较难设计,如何确定层级
- 需要考虑问题:(1)竖向隔阂:手工/自动方案的整合问题(2)横向隔阂:单向转换,低层级的优化难以反馈到高层
- 解决方案:TVM Unity、MLIR、Apollo(图层和算子层统一)、FreeTensor、整体生态整合
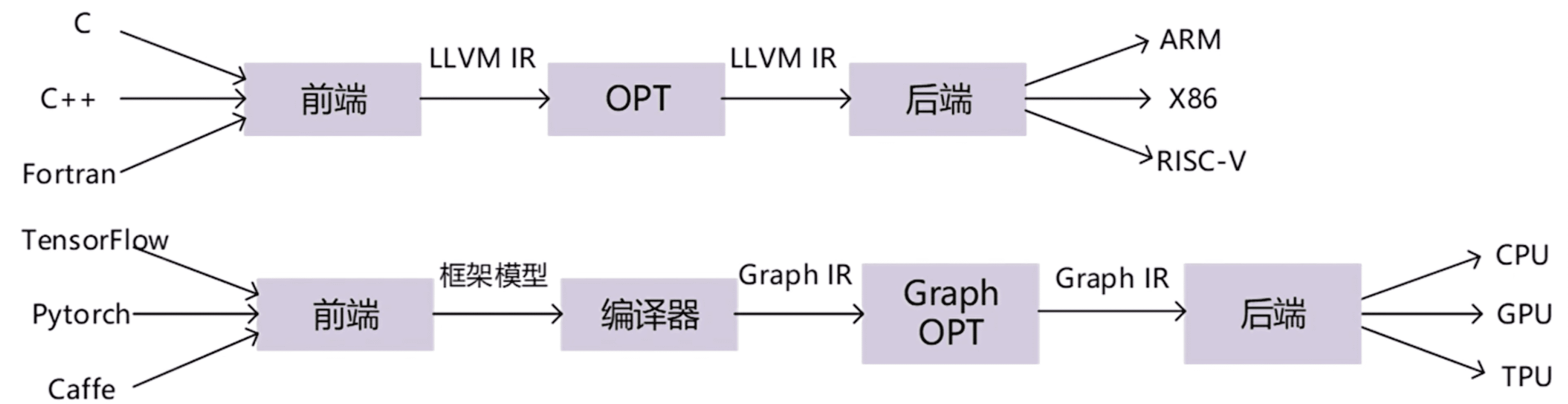
-
解释器inpreter与编译器compiler
-
编译方式的角度:
- 静态编译 AOT(Ahead of Time) - -提前编译
- 动态编译 JIT(Just in time)--- 即时编译
-
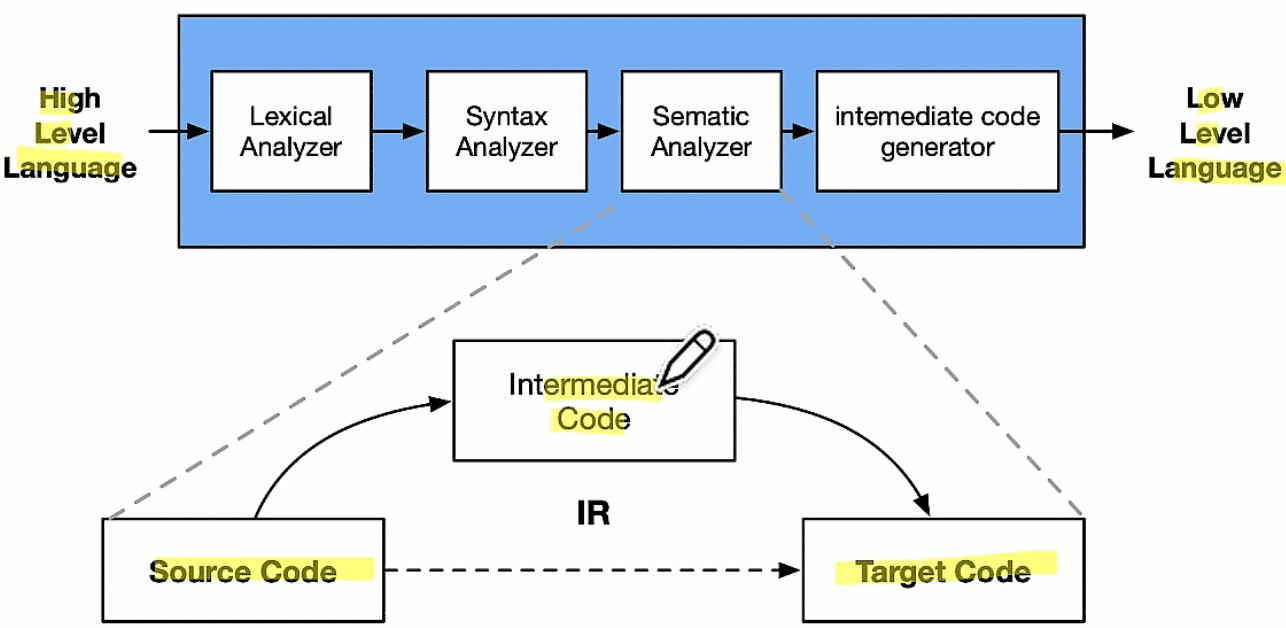
编译器 中的 Pass与IR
-
Pass:对源程序的一次完整扫描或处理
-
IR:intermediate representations 中间表达 - 数据结构或者代码
- 高级语言到机器码,中间的部分不明确 --- IR把它明确下来
-
-
GCC Vs. LLVM
-
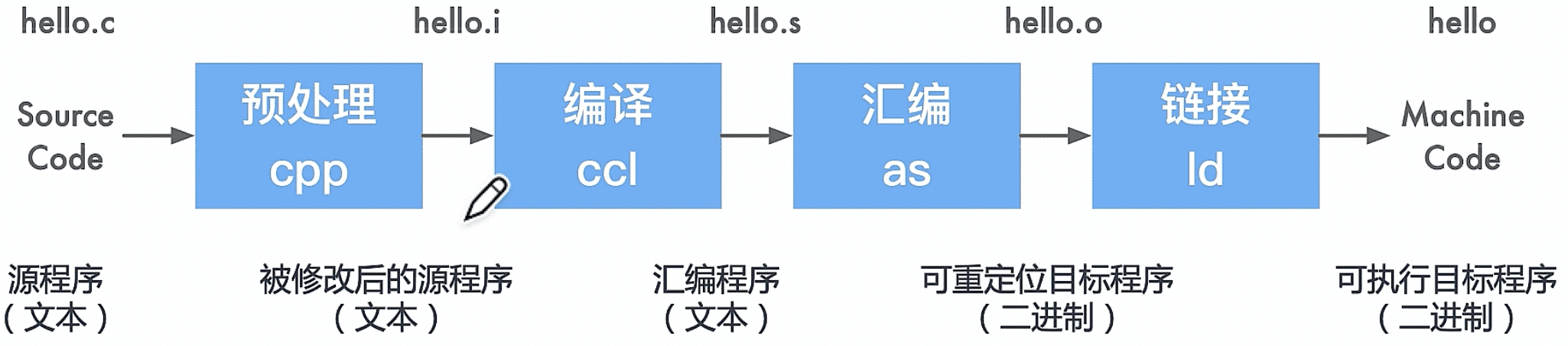
(GNU Compiler Collection, GCC);【开源】是优化过的C语言编译器
- 如今不仅能编译C,Java、C# 都可以
- 编译流程 --- 一整个都叫“编译”,细化下来可以分成这些流程
-
LLVM - 作者Chirs lattner【Apple开发,开源】前端基于了clang
-
如今也是工具集合、工具链(实际上是编译器工具套装,不再只是Low Level virtual Machine),中间需要IR统一
-
一个前端Clang,对接IR和所有后端,编译过程:
-
需要注意的是IR在其中并不是单一的表达方式:不同阶段会采用不同数据结构
-
-

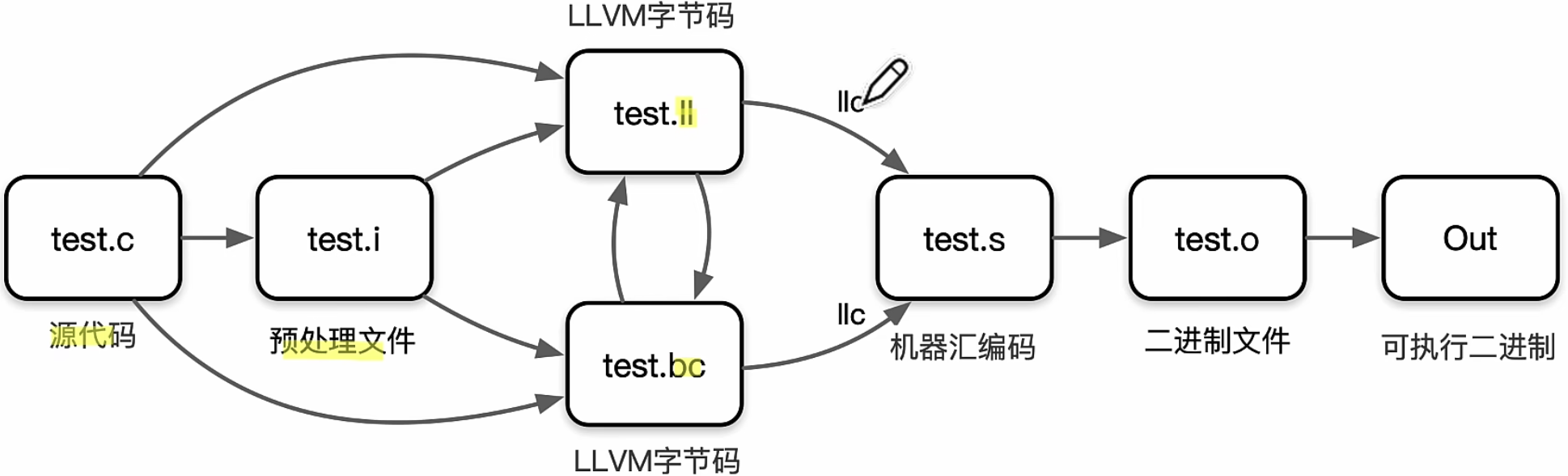
- 经常涉及到的概念:Relay: a highlevel compiler for deep learning
- 更基础讲:计算流图computational graph (dataflow graph) , 用directed acyclic graph (DAG) 来表达;但是缺少对控制的描述
- Relay 是 **TVM **中的模块,所以 【tvm/relay】TVM Doc. Intro to Relay IR
- Relay 作为 NNVM 的进阶版本,同时具有编程语言的特点和深度学习图构造的能力
- Relay 考虑了异构场景下的代码生成
- 把优化过程看作是对IR的变换,具体使用ExprMutator完成
-
autoTVM是TVM主要区别于其它编译器的特征
-
介绍【tvm/autotvm】TVM Doc. python编程接口【tvm.autotvm】 使用教程tutorial案例【tvm/autotvm】tutorial
-
Autotvm与AutoScheduler都是 基于程序优化自动Search的组件,主要包含:
- Cost model 和 特征提取
tvm/autotvm:其中的cost model与特征提取 与我的中上层的关系
- 提供了一种存储 程序 benchmark信息的方法 -- 以用于 Cost model
- 在程序转换之间的一组 Search策略
-
从样例【TVM-guide】Auto-Tune with Templates and AutoTVM的角度 来看使用时的组成部分
- 提供一个算子模板,定义可选参数.
- 创建一个搜索任务,将模板中的可选参数和搜索任务强绑定.
- 使用TUNE进行本地实际测试,记录测试结果.(预跑几个epoch)
- 调用测试结果,将最优结果填入模板中,生成调度,用于实际计算.
- TVM 复现 Faith务必要跑通,了解整体结构
- 确认pytorch有没有相应的算子融合机制,进一步确定从何处入手写kernel
- 还待找一个Transformer类代码的工作做对比实验
Reference:
关于有没有:有;体现形式:torch.compile() --- 在连接中有代码的例子;
(1) 所在版本Pytroch2.0 的详细展示
跳转到 --- DL-basis-Note
首先参考:B站Zomi:算子融合/算子替换/算子前移优化!【推理引擎】离线优化第03篇
-
基础图优化 --- 子步骤 算子融合
-
算子融合:减少二次访存
-
算子替换:一对一替换,一对多替换:fission
-
设计实验:证明计算流程中的同步开销大
-
比较好的 无同步 理解材料?
健崎、正阳、旭宝
-
好上手(含有对比)的 无同步 代码实例?
- A 使用了无同步 / B 没有使用无同步
- A组中的 线程分配 ,线程块block 与col / “block”的关系
- global 状态数组 、任务队列的细节
-
我目前的理解 对齐
- DAC21 SFLU 无同步稀疏 LU 分解算法: 单kernel,一个thread block处理一列
- ==关键点== 在无同步之前:对于巨量level-sets的情况,不同kernel不断启动 同步的时间 成为整个计算时间的瓶颈。
- 将每一列的消除工作分配给 CUDA 中的一个线程块thread block (只有一个kernel)
- 通过访问具有依赖信息的全局内存数组,所有线程块block都忙于等待,直到它们对其他列的依赖被解除。 当线程块block知道其依赖关系已解决(1)立即执行工作(2)更新全局内存 数组 -- 与其他block的依赖关系刷新
-
【SC'23】 PanguLU: 4.4 Synchronisation-Free Scheduling
-
考虑不同子任务之间的依赖关系的无同步通信策略,以减少总体延迟开销;最小调度单元: sparse kernels
-
每个进程总是选择待计算任务中最关键的一个来进行计算,使得关键路径上的任务的计算尽可能快
-
使用无同步数组,在进程之间传递无同步数组的值来实现细粒度的进程调度,让分布式系统中的每个进程计算尽可能多executable sparse kernels --- 实现更高的并行性
- 使用步骤①构造数组:一个子矩阵block会执行多个kernel ; 数组记录每个子矩阵块的剩余工作量(值 为子矩阵块仍需执行某个任务的次数) ②更新无同步数组并管理进程的计算和通信 ;标记一个变量0为可执行,再添加到任务队列(执行 / 等等它所依赖的处理完)
-
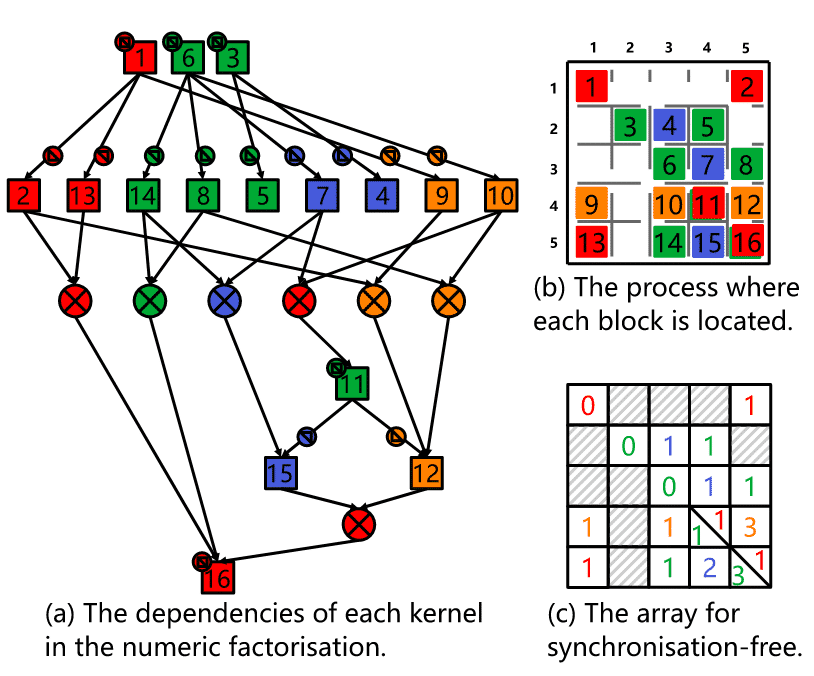
-
【CCPE2017】Fast Synchronization-Free Algorithms for Parallel Sparse Triangular Solves with Multiple Right-Hand Sides
-
【Euro-Par2016】A Synchronization-Free Algorithm for Parallel Sparse Triangular Solves
-
【CCF-THPC2023】 TileSpTRSV
- 用原子加fast atomic operations: atomic-add / atomic-dec
in_degree数组记录每个非零元素的依赖入度 - 这个入度必须先计算好- 无同步的根本目的:SpTRSV操作level-set,每个level 必须串行 ,而不同的kernel启动有很高的启动成本。无同步使用了完全是另一种算法(不是简单的融合算子),把这些操作写成了一个kernel,其中的依赖关系使用数组来记录
- 于我而言kernel-fusion融合:GEMM1+(Mask)+ softmax + GEMM2带来了依赖关系 --- 对于我的算子融合的另一种阐述
重要收获:了解一个工作除了首先看看原文怎么写,还可以参考网上的原文解析、源代码解析 --- egByteTransformer
直接看原文根本看不懂,看源代码非常复杂也没有注释
底层参考【MLSys21】DataMovement,【IPDPS23】ByteTransformer,【PLDI21】DNNFusion,【SC22】DeepSpeed-Inference
中层参考 【ATC22】Faith,【OSDI20】Ansor
上层参考 【ATC22】Faith,【OSDI20】Ansor,【Cluster21】csTuner
惊异于能看懂70%左右 ,除了验证 Transformer的全流程及其含义不明白外~~(感觉也并不是重点)~~
来 识别语义信息 --- 分析计算pattern、融合机会、数据重用机会
语意感知semantic-aware 含义? ---- 数据的含义。 感觉这一部分依赖于GPU的专家知识
- 层内semantic-aware kernel fusion:
- 根本目的是减少对内存的访问 ---- 层间的又进一步减少
- weight-paring based fusion:(1)数据W从Global_Mem ---> shared_Mem,(2)在shared_Mem中取区分为$W_{pos}$与$W_{neg}$,其中
$W_{pos} + W_{neg} = W$ . - double bound based fusion:(1)使用跨Blocks的thread把数据从Global_Mem ---> Shared_Mem,在Global_Mem中算乘 (2)每个thread把数据分别从Shared_Mem --> Reg,在Reg中算累加
- 层间bound-aware cross-layer fusion
- 给算子分类:①input-reduction-compute /② strict-elementwise / ③dense-computation
- 融合:③+②,①+②,②+②
高效映射到GPU后端上--- 手写的算子;与验证 Transformer强相关的专家知识
-
验证模式分类(分了3个典型的计算pattern):①generalized vector reduction / ②generalized elementwise multiplication / ③generalized scalar-vector multiplication
-
工作负载自适应的规约 reduction
-
单线程变多线程 --- 运用多核、占用显存
-
举例:固定长度
$length = 32$ ,从32 iter减少到了5iter$(N - logN)$- 实现上运用 CUDA的专家指令
_shfl_down_sync:直接在各个线程之间传递寄存器中的数据 - 任意长度的,让它近似于
$length = 32k$ 即32的倍数,iter变为$5k$ iter
- 实现上运用 CUDA的专家指令
-
-
以共享为目标的 负载调度
- 充分利用Shared_Men为目标,包含了上面的2和融合
-
广播感知的 超线程
- 只需要一个线程去读标量,广播给其他线程
将专家知识融入 GPU 后端,以促进大型搜索空间探索
-
基于一定规则的 专家知识元文件
- 需要设置GPU的类型
- 硬 规则:GPU上寄存器数量有限 、需要防止Reg溢出
- 软 规则:$thread/block = thread/SM $,多了少了有相应的问题
-
专家引导的 代价模型 -- 2个阶段 处理实现参数和硬件属性之间的关系
(0)给定一组 候选的参数实现
(1)估算Shared_Men与寄存器用量 --- 排除会导致溢出的
(2)训练代价模型 XGboost --- 本身也要上机器学习
Cost Model 预估延迟,找出Top-K的候选方案;用Top-K的方案做profile(预跑5个iter),利用profile的结果微调代价模型
三个关键词:parameter grouping / search space sampling / evolutionary search
- 运行时间占比:实际上是从experiment中取出来的(V100 * 2)
- 以上实验数据证明 -- 专家知识观察:①高性能测设置少 ②优化参数设置之间有关联性 ③高性能设置的关联性
一组统计和机器学习的方法来生成 参数组 和 采样参数设置,参数组用于设计 指导采样过程的回归函数
- 优化的空间参数 --- Stencil运算强相关的一些参数
- 参数组合 --- 双端队列算法 Algorithm 1
- 搜索空间采样
- 在采样过程中删去性能不高的参数设置
- Algorithm 2 矩阵组合
考虑近似 + 定制的遗传算法 开展 迭代的自调优:找到最优的 优化参数组合
- 基于遗传算法的 进化搜索(Evolutionary Search)
- genes基因 --- individuals个体 ---- population 种群
- 培养新个体和子群:①从邻居选父母 ②个体的基因从父母中随机选 ③给定一个概率 基因变异
关于search: 策略相同,但搜索目标和cluster21 csTuner有本质的区别
Ansor目前已经被集成进了TVM中 更名为 AutoScheduler,出现在TVM-publcation中
因此Ansor的相关解读,已经作为了TVM介绍的一部分
读的过程中感觉需要进一步了解TVM、Auto知识 ---- 跳转回[2.2TVM补充 ](##2.2 - TVM)
-
模板引导的search:
-
TVM要求用户为了计算定义 手写模板 ---定义了基本结构
-
然后compiler结合具体硬件和输入参数 来search具体参数设置
-
-
基于序列构造的search:
- 将(不完整的)程序构造分解为 固定的决策序列 来定义搜索空间
- 上Beam search来进行早期的剪枝(Halide) --- 把节点展开unfold
-
$top-k$ 找出最后的几种组合
基于梯度下降 --- ML ??
记高频词汇:
explicit 明确的 implicit隐含的、不明确的
facilitate 促进
for instance 例如
versatility 多功能性
exhaustive 详尽的 holistic 全面的、整体的
genetic 基因的、遗传的 genetic algorithm遗传算法
valid 有效的
deteriorate 退化、恶化的
mitigate 减缓
semantic-aware 语义感知的
eliminate 消除
estimate 估算
intrinsic 固有的
scalar 标量
redundant 冗余的
constitute 构成
conform 符合
normal distribution 正态分布
crucial 至关重要的
construction 构造
substantial 重大的 实惠的
granularity 粒度
-
从语言、矩阵乘的角度==最好理解的== https://zhuanlan.zhihu.com/p/403433120
诶等等,我9个月前赶SC23的时候好像是了解过的
-
读懂Transformer --- 本周日完成BG,兼备份毕业论文
- 目前已能搞懂:AI(众多公式,不究太深) + 计算(学姐所梳理的算子)
- 广搜罗论文,读英文文献的方法,笔记记录工作流
- 结合笔记,来写BG:Transformer部分(Bert)
-
读懂的过程:
注,需要整理同时paper,以备之后作参考论文
- 网站等解读记录内容①专门社区-huggingface ②【偏灵魂】Transf基本概念与训练一个此模型 ③【更偏灵魂】知乎 - Attention机制 ④【很好懂的灵魂 - 强推】知乎 - 读懂Transforemr模型 ⑤读懂Bert与资源整理 - 2019 ⑥【可能是最重要 - 强推】 - 图示Transformer,主要有很多矩阵运算的图
- Transformer、Bert 论文本体与解读 ——主力是综述:eg(Efiicient Trans...)
- 所延伸(暨之前的的一些索引)的变体T&B
-
写BG,学姐对于SyncFree 的部分,在论文中会出现的位置主要在于“方法”中
- 主力还是Bert(辩证:而非Transformers)篇幅在0.75页左右
- BG后半部分 主要写融合所遇到的问题(综述,参考turbo-transformer)
原思路:从MLP出发,到CNN,再到NLP系列的模型。但看了以后仍然感觉并不清楚,也并不需要之大为什么,此部分内容不是我们所关注的。本部分为AI所关注的点,并不是我们(计算机专业、HPC实验室)所关注的计算的内容。 其具体为什么、关注句子的哪一部分、QKV是为何,均不重要
长期来看,尽管在昨天的过程中知道了什么是前向反向、Transformer的发展和基本原理,是有需要的,但不应是在需要写出BG得时候来学这个过程。目前完全不管,只看计算、算子
学校确实是比公司更宽松的学习环境,但也看时效。很多时候其实是可以放开了手脚来学习的,但是目前我这个阶段暂时不行。有部分老师允许学生有一个相当长的时间段来学习,但其实我个人也不认可这种理念和形式,太容易养闲人而没有实用的反馈,完全是一个玄乎的事。目前的状态,私以为是对的,但具体独当一面还需要来适应它
-
对Bert的 BG,不关心与QKV层面的、以及模型来源的BG
- 从算子、运算层面的操作出发,直接给出Bert - 算子融合的 BG
- BG中应涉及,为什么融合,传统上的融合方式,融合的特点。主要参考印度小哥图示解释Transformer矩阵计算过程,与turboTransformers-paper
-
具体而言,撰写思路:还是先从中文出发 --- 翻译为英文
3段:(预计占比0.75个半页面、纯文字)
- 自Transformer发布以来产生的Bert的良好效果、广泛应用,使用GPU平台,简单介绍、这一块对于模型的配图???
- 但在其计算过程中存在困难:计算 + 存储, 评价思路
- Sparse的模型结构介绍,主要稀疏的对象、实现手段、情况效果
- 算子融合的Transformer
- 姝慧姐留下来的分析报告,overleaf中 ---- 主要导向openAI
- 网络上的搜索结果 --- 广搜机制
- 记得之前看过一篇关于 Transformers的Survey --- 图
读的目标是 - 了解别人如何实现fuse的,希望能够找到一份融合好的MHA作为基准,以及别人如何利用Sparity;
在看了他们的代码以后感觉就没什么感觉,除了了解基本的测试方法以外,核心的东西(fuse)还是没看懂
Keywords:fuse、Sparse
项目本身的 Github - ByteTransformer;但从“无填充算法”的想法而言,基于了同公司的工作Bytedance - EffectiveTransformer
热烈的马,在跑了这个代码,并把这个代码作为基准来做了profile以后对这个论文理解有质的提升(10% --- 70%)
尤其对于一些关键词,一眼真; 更反映出之前读的paper都读的是个jier
这篇paper的一些说法可以参考 -- 问题分析、实验设置、时间复杂的分析
-
最主要贡献:无填充算法 - 将输入张量与可变长度序列打包、添加新索引(前缀和prefix sum)
- 别人处理变长variable-length:填充到固定长度fixed-length;
-
算子融合
- cuBLas高度优化GEMM,算子融合则不管这部分,而是关注于除了GEMM外的其他部分
- Add bias+layer Norm \ Add bias+activation:
- Fuse MHA 减缓了内存开销:中间矩阵内存开销是
${seq_len}^2$ ,fuse了MHA的部分 (基于Cutlass)- 短序列MHA:无pad FMHA,大量计算索引offset,定义了SKEW_HALF避免bank conflict
- 长序列MHA:grouped GEMM、Grouped-GEMM-based FMHA
- cuBLas高度优化GEMM,算子融合则不管这部分,而是关注于除了GEMM外的其他部分
-
手动微调 (参数设置)
-
没有基于别人的相关工作,只有cutlass,用了tensorcore
-
其中的 grouped GEMM已经合并进了cutlass
Byte的评价:”部分融合“ --- 优化了Transformer模型中的部分容易融合的操作,layernorm+激活
-- MHA的部分 有融合(结构图)(TensorRT)
-- 自己也实现了融合的部分(只有Attention)
主要参考 李沐 - 安静、高性价比双卡装机 - 100亿模型计划
资料参考:
- 显卡价格参考:newegg.com(专门做单子产品的交易网站)
- 查询GeForce的参数:直接搜GeForce 40series 的 wiki百科
- GPU的性能监控小工具:
sudo apt install nvtop使用方式上同top
初步配置思路:
非常适合上手的推荐:李沐 -环境安装,BERT、GPT、T5 性能测试,和横向对比 - 100亿模型计划
- CUDA, pip/onda pytorch
- Nvidia drive + conda pytorch
- Nvidia drive + nvidia docker